第十三周项目2 Kruskal算法
/* * Copyright (c)2015,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名称:项目2.cbp * 作 者:孙钦达 * 完成日期:2015年12月4日 * 版 本 号:v1.0 * 问题描述:Kruskal算法 * 输入描述:无 * 程序输出:最小生成树 */
#ifndef GRAPH_H_INCLUDED
#define GRAPH_H_INCLUDED
#define MaxSize 100
#define MAXV 100 //最大顶点个数
#define INF 32767 //INF表示∞
typedef int InfoType;
//以下定义邻接矩阵类型
typedef struct
{
int no; //顶点编号
InfoType info; //顶点其他信息,在此存放带权图权值
} VertexType; //顶点类型
typedef struct //图的定义
{
int edges[MAXV][MAXV]; //邻接矩阵
int n,e; //顶点数,弧数
VertexType vexs[MAXV]; //存放顶点信息
} MGraph; //图的邻接矩阵类型
//以下定义邻接表类型
typedef struct ANode //弧的结点结构类型
{
int adjvex; //该弧的终点位置
struct ANode *nextarc; //指向下一条弧的指针
InfoType info; //该弧的相关信息,这里用于存放权值
} ArcNode;
typedef int Vertex;
typedef struct Vnode //邻接表头结点的类型
{
Vertex data; //顶点信息
int count; //存放顶点入度,只在拓扑排序中用
ArcNode *firstarc; //指向第一条弧
} VNode;
typedef VNode AdjList[MAXV]; //AdjList是邻接表类型
typedef struct
{
AdjList adjlist; //邻接表
int n,e; //图中顶点数n和边数e
} ALGraph; //图的邻接表类型
typedef struct
{
int u; //边的起始顶点
int v; //边的终止顶点
int w; //边的权值
} Edge;
//功能:由一个反映图中顶点邻接关系的二维数组,构造出用邻接矩阵存储的图
//参数:Arr - 数组名,由于形式参数为二维数组时必须给出每行的元素个数,在此将参数Arr声明为一维数组名(指向int的指针)
// n - 矩阵的阶数
// g - 要构造出来的邻接矩阵数据结构
void ArrayToMat(int *Arr, int n, MGraph &g); //用普通数组构造图的邻接矩阵
void ArrayToList(int *Arr, int n, ALGraph *&); //用普通数组构造图的邻接表
void MatToList(MGraph g,ALGraph *&G);//将邻接矩阵g转换成邻接表G
void ListToMat(ALGraph *G,MGraph &g);//将邻接表G转换成邻接矩阵g
void DispMat(MGraph g);//输出邻接矩阵g
void DispAdj(ALGraph *G);//输出邻接表G
void InsertSort(Edge E[],int n);
void Kruskal(MGraph g);
#endif // GRAPH_H_INCLUDED
#include "head.h"
#include<stdio.h>
int main()
{
MGraph g;
int A[6][6]=
{
{0,6,1,5,INF,INF},
{6,0,5,INF,3,INF},
{1,5,0,5,6,4},
{5,INF,5,0,INF,2},
{INF,3,6,INF,0,6},
{INF,INF,4,2,6,0}
};
ArrayToMat(A[0], 6, g);
printf("最小生成树构成:\n");
Kruskal(g);
return 0;
}
#include <stdio.h>
#include <malloc.h>
#include "head.h"
//功能:由一个反映图中顶点邻接关系的二维数组,构造出用邻接矩阵存储的图
//参数:Arr - 数组名,由于形式参数为二维数组时必须给出每行的元素个数,在此将参数Arr声明为一维数组名(指向int的指针)
// n - 矩阵的阶数
// g - 要构造出来的邻接矩阵数据结构
void ArrayToMat(int *Arr, int n, MGraph &g)
{
int i,j,count=0; //count用于统计边数,即矩阵中非0元素个数
g.n=n;
for (i=0; i<g.n; i++)
for (j=0; j<g.n; j++)
{
g.edges[i][j]=Arr[i*n+j]; //将Arr看作n×n的二维数组,Arr[i*n+j]即是Arr[i][j],计算存储位置的功夫在此应用
if(g.edges[i][j]!=0 && g.edges[i][j]!=INF)
count++;
}
g.e=count;
}
void ArrayToList(int *Arr, int n, ALGraph *&G)
{
int i,j,count=0; //count用于统计边数,即矩阵中非0元素个数
ArcNode *p;
G=(ALGraph *)malloc(sizeof(ALGraph));
G->n=n;
for (i=0; i<n; i++) //给邻接表中所有头节点的指针域置初值
G->adjlist[i].firstarc=NULL;
for (i=0; i<n; i++) //检查邻接矩阵中每个元素
for (j=n-1; j>=0; j--)
if (Arr[i*n+j]!=0) //存在一条边,将Arr看作n×n的二维数组,Arr[i*n+j]即是Arr[i][j]
{
p=(ArcNode *)malloc(sizeof(ArcNode)); //创建一个节点*p
p->adjvex=j;
p->info=Arr[i*n+j];
p->nextarc=G->adjlist[i].firstarc; //采用头插法插入*p
G->adjlist[i].firstarc=p;
}
G->e=count;
}
void MatToList(MGraph g, ALGraph *&G)
//将邻接矩阵g转换成邻接表G
{
int i,j;
ArcNode *p;
G=(ALGraph *)malloc(sizeof(ALGraph));
for (i=0; i<g.n; i++) //给邻接表中所有头节点的指针域置初值
G->adjlist[i].firstarc=NULL;
for (i=0; i<g.n; i++) //检查邻接矩阵中每个元素
for (j=g.n-1; j>=0; j--)
if (g.edges[i][j]!=0) //存在一条边
{
p=(ArcNode *)malloc(sizeof(ArcNode)); //创建一个节点*p
p->adjvex=j;
p->info=g.edges[i][j];
p->nextarc=G->adjlist[i].firstarc; //采用头插法插入*p
G->adjlist[i].firstarc=p;
}
G->n=g.n;
G->e=g.e;
}
void ListToMat(ALGraph *G,MGraph &g)
//将邻接表G转换成邻接矩阵g
{
int i,j;
ArcNode *p;
g.n=G->n; //根据一楼同学“举报”改的。g.n未赋值,下面的初始化不起作用
g.e=G->e;
for (i=0; i<g.n; i++) //先初始化邻接矩阵
for (j=0; j<g.n; j++)
g.edges[i][j]=0;
for (i=0; i<G->n; i++) //根据邻接表,为邻接矩阵赋值
{
p=G->adjlist[i].firstarc;
while (p!=NULL)
{
g.edges[i][p->adjvex]=p->info;
p=p->nextarc;
}
}
}
void DispMat(MGraph g)
//输出邻接矩阵g
{
int i,j;
for (i=0; i<g.n; i++)
{
for (j=0; j<g.n; j++)
if (g.edges[i][j]==INF)
printf("%3s","∞");
else
printf("%3d",g.edges[i][j]);
printf("\n");
}
}
void DispAdj(ALGraph *G)
//输出邻接表G
{
int i;
ArcNode *p;
for (i=0; i<G->n; i++)
{
p=G->adjlist[i].firstarc;
printf("%3d: ",i);
while (p!=NULL)
{
printf("-->%d/%d ",p->adjvex,p->info);
p=p->nextarc;
}
printf("\n");
}
}
void InsertSort(Edge E[],int n) //对E[0..n-1]按递增有序进行直接插入排序
{
int i,j;
Edge temp;
for (i=1; i<n; i++)
{
temp=E[i];
j=i-1; //从右向左在有序区E[0..i-1]中找E[i]的插入位置
while (j>=0 && temp.w<E[j].w)
{
E[j+1]=E[j]; //将关键字大于E[i].w的记录后移
j--;
}
E[j+1]=temp; //在j+1处插入E[i]
}
}
void Kruskal(MGraph g)
{
int i,j,u1,v1,sn1,sn2,k;
int vset[MAXV];
Edge E[MaxSize]; //存放所有边
k=0; //E数组的下标从0开始计
for (i=0; i<g.n; i++) //由g产生的边集E
for (j=0; j<g.n; j++)
if (g.edges[i][j]!=0 && g.edges[i][j]!=INF)
{
E[k].u=i;
E[k].v=j;
E[k].w=g.edges[i][j];
k++;
}
InsertSort(E,g.e); //采用直接插入排序对E数组按权值递增排序
for (i=0; i<g.n; i++) //初始化辅助数组
vset[i]=i;
k=1; //k表示当前构造生成树的第几条边,初值为1
j=0; //E中边的下标,初值为0
while (k<g.n) //生成的边数小于n时循环
{
u1=E[j].u;
v1=E[j].v; //取一条边的头尾顶点
sn1=vset[u1];
sn2=vset[v1]; //分别得到两个顶点所属的集合编号
if (sn1!=sn2) //两顶点属于不同的集合
{
printf(" (%d,%d):%d\n",u1,v1,E[j].w);
k++; //生成边数增1
for (i=0; i<g.n; i++) //两个集合统一编号
if (vset[i]==sn2) //集合编号为sn2的改为sn1
vset[i]=sn1;
}
j++; //扫描下一条边
}
}
运行结果:
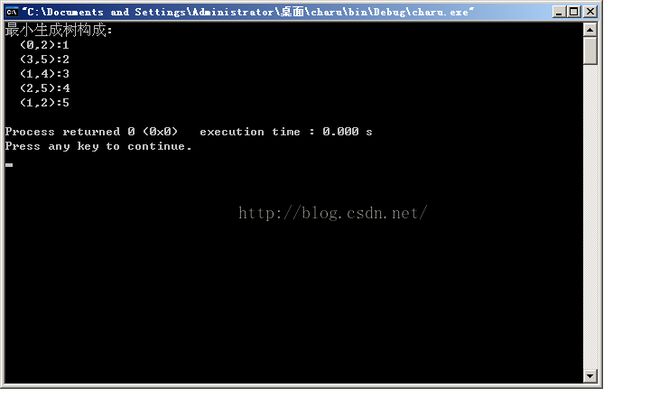
识点总结:
kruskal算法总共选择n- 1条边,(共n个点)所使用的贪婪准则是:从剩下的边中选择一条不会产生环路的具有最小耗费的边加入已选择的边的集合中。注意到所选取的边若产生环路则不可能形成一棵生成树。kruskal算法分e 步,其中e 是网络中边的数目。按耗费递增的顺序来考虑这e 条边,每次考虑一条边。当考虑某条边时,若将其加入到已选边的集合中会出现环路,则将其抛弃,否则,将它选入。