最大熵模型简记
最近两天简单看了下最大熵模型,特此做简单笔记,后续继续补充。最大熵模型是自然语言处理(NLP, nature language processing)被广泛运用,比如文本分类等。主要从分为三个方面,一:熵的数学定义;二:熵数学形式化定义的来源;三:最大熵模型。
注意:这里的熵都是指信息熵。
一:熵的数学定义:
下面分别给出熵、联合熵、条件熵、相对熵、互信息的定义。
熵:如果一个随机变量X的可能取值为X = {x1, x2,…, xk},其概率分布为P(X = xi) = pi(i= 1,2, ..., n),则随机变量X的熵定义为:
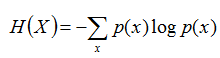
把最前面的负号放到最后,便成了:
上面两个熵的公式,无论用哪个都行,而且两者等价,一个意思(这两个公式在下文中都会用到)。
联合熵:两个随机变量X,Y的联合分布,可以形成联合熵JointEntropy,用H(X,Y)表示。
条件熵:在随机变量X发生的前提下,随机变量Y发生所新带来的熵定义为Y的条件熵,用H(Y|X)表示,用来衡量在已知随机变量X的条件下随机变量Y的不确定性。
且有此式子成立:H(Y|X)= H(X,Y) – H(X),整个式子表示(X,Y)发生所包含的熵减去X单独发生包含的熵。至于怎么得来的请看推导:
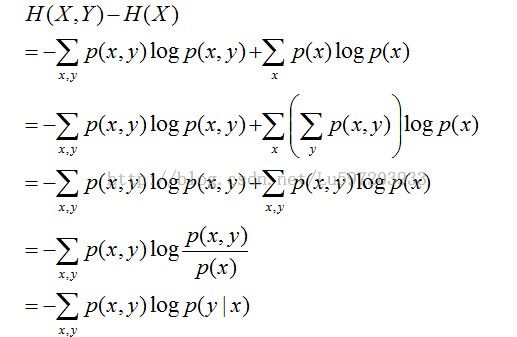
相对熵:又称互熵,交叉熵,鉴别信息,Kullback熵,Kullback-Leible散度等。设p(x)、q(x)是X中取值的两个概率分布,则p对q的相对熵是:
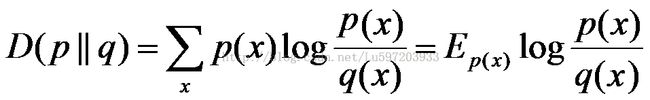
在一定程度上,相对熵可以度量两个随机变量的“距离”,且有D(p||q)≠D(q||p)。另外,值得一提的是,D(p||q)是必然大于等于0的,可以通过jensen不等式证明得出结果。
互信息:两个随机变量X,Y的互信息定义为X,Y的联合分布和各自独立分布乘积的相对熵,用I(X,Y)表示:
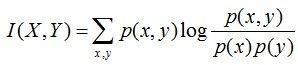
且有I(X,Y)=D(P(X,Y)|| P(X)P(Y))。下面,咱们来计算下H(Y)-I(X,Y)的结果,如下:
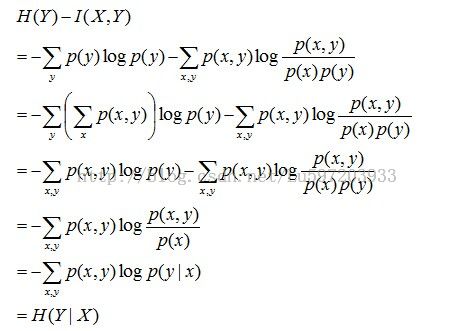
通过上面的计算过程,我们发现竟然有H(Y)-I(X,Y) = H(Y|X)。故通过条件熵的定义,有:H(Y|X)= H(X,Y) - H(X),而根据互信息定义展开得到H(Y|X) = H(Y) - I(X,Y),把前者跟后者结合起来,便有I(X,Y)= H(X) + H(Y) - H(X,Y),此结论被多数文献作为互信息的定义。
二:熵形式化定义的来源
这里给出几个简单的例子:
• 例1:假设有5个硬币:1,2,3,4,5,其中一个是假的,比其他的硬币轻。有一个天平,天平每次能比较两堆硬币,得出的结果可能是以下三种之一:
• 左边比右边轻
• 右边比左边轻
• 两边同样重
问:至少要使用天平多少次才能保证找到假硬币?
(某年小学生数学竞赛题目:P)
解法:让X表示佳硬币的序号,x∈X = {1,2,3,4,5};让Y表示天平得到的结果,y∈Y={1,2,3};其中1表示左轻,2表示右轻,3表示一样重。用天平秤n次,获得的结果获得的结果是:y1 y2… yn,y1 y2… yn的所有可能组合数目是3^n,我们要通过y1 y2… yn找出x。所以:每个y1 y2… yn组合最多可能有一个对应的x取值。
因为x取X中任意一个值的时候,我们都要能够找出x,因此对于任意一个x的取值,至少要有一个y1 y2… yn与之对应。根据鸽笼原理……
|Y|^n ≥|X|,两边开根号,就可以得到n*logY≥logX, 此外logX= 1/X*logX+ 1/X*logX+…(共有X个,表示每个硬币发生的概率与log(1/p)的成绩),因此logX可以看做是硬币的不确定度,而logY看做是表达能力,n表示需要多少个表达能力才能表示硬币的不确定度。故n = logX/logY.
那么为什么用log 来表示“不确定度”和“描述能力”呢?前面已经讲过了,假设一个Y 的表达能力是H(Y) 。显然,H(Y) 与Y 的具体内容无关,只与|Y| 有关。所以像是log|Y|^n 这种形式,把n就可以拿出来了,因为关系不大所以扔掉n就剩下log|Y| 了。
“不确定度”和“描述能力”都表达了一个变量所能变化的程度。在这个变量是用来表示别的变量的时候,这个程度是表达能力。在这个变量是被表示变量的时候,这个程度是不确定度。而这个可变化程度,就是一个变量的熵(Entropy)。显然:熵与变量本身含义无关,仅与变量的可能取值范围有关。
题目的变形:
假设有5个硬币:1,2,3,…5,其中一个是假的,比其他的硬币轻。已知第一个硬币是假硬币的概率是三分之一;第二个硬币是假硬币的概率也是三分之一,其他硬币是假硬币的概率都是九分之一。
有一个天平,天平每次能比较两堆硬币,得出的结果可能是以下三种之一:
• 左边比右边轻
• 右边比左边轻
• 两边同样重
假设使用天平n次找到假硬币。问n的期望值至少是多少?
(不再是小学生问题:P)
我们按照上面的思路,就可以很容易的求出来H(x) = 1/3*log3+1/3*log3 + 1/9*3*log9,表示的仍是是假硬币不确定度的期望。
H(Y)=log3,所以n就等于H(x)/H(Y).
这样就可以得出熵的来源了,希望能看懂。
三:最大熵模型
这一部分可以看july的blog:http://blog.csdn.net/v_july_v/article/details/40508465
主要记录下:
1:熵的原则是承认已知事物(知识),且对未知事物不做任何假设,没有任何偏见。从投资的角度来看,这是风险最小的做法,而从信息论的角度讲,就是保留了最大的不确定性,也就是说让熵达到最大(投资风险最小化)。
2:最大熵模型的完整表述如下:
其约束条件为:
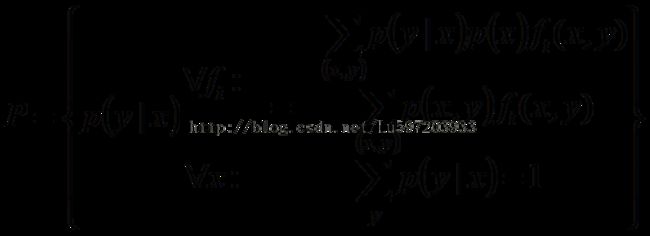
Lagrange函数表达为:
得到的结果为:
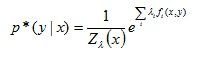
其中:
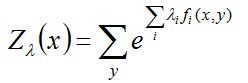
导出最终要求解:

最大熵模型模型属于对数线性模型,因为其包含指数函数,所以几乎不可能有解析解。换言之,即便有了解析解,仍然需要数值解。那么,能不能找到另一种逼近?构造函数f(λ),求其最大/最小值?
IIS(ImprovedIterative Scaling)是目前最大熵模型的最优化算法,优于梯度下降算法(这里是无约束的优化问题,但是通过求导无法给出解析解,所以当然也可以使用梯度迭代,牛顿法,拟牛顿法,通用的迭代法(GIS))。
改进的迭代尺度法IIS的核心思想是:假设最大熵模型当前的参数向量是λ,希望找到一个新的参数向量λ+δ,使得当前模型的对数似然函数值L增加。重复这一过程,直至找到对数似然函数的最大值。
3:将最优解p(y|x)代入到最大似然估计的公式中,我们会发现其和最大熵得到的关于参数λ具有相同的目标函数。可以断定:最大熵的解(无偏的对待不确定性)同时是最符合样本数据分布的解,进一步证明了最大熵模型的合理性。最大熵模型是对不确定度的无偏分配,最大似然估计则是对知识的无偏理解。
问题:(1)我还没有弄明白在讲解最大熵模型时,为什么要引入特征函数来导出约束条件,它如何形象的表示一个具体的例子。这个可能需要看一些具体文本分类的案例才能理解,有知道的可以留言。谢谢!
(2)我还没有看IIS的数学推导,留着后续用到的时候再看吧…..
参考文献:
1: http://blog.csdn.net/v_july_v/article/details/40508465july的最大熵模型推导
2:http://blog.csdn.net/daoqinglin/article/details/6906421
3: 统计学习方法<李航>
3:http://jiangtanghu.com/docs/cn/maxEnt.pdf最大熵读书笔记