Fp关联规则算法计算置信度及MapReduce实现思路
说明:参考Mahout FP算法相关相关源码。
算法工程可以在FP关联规则计算置信度下载:(只是单机版的实现,并没有MapReduce的代码)
使用FP关联规则算法计算置信度基于下面的思路:
1. 首先使用原始的FP树关联规则挖掘出所有的频繁项集及其支持度;这里需要注意,这里是输出所有的频繁项集,并没有把频繁项集合并,所以需要修改FP树的相关代码,在某些步骤把所有的频繁项集输出;(ps:参考Mahout的FP树单机版的实现,进行了修改,暂不确定是否已经输出了全部频繁项集)
为举例简单,可以以下面的数据为例(原始事务集):
牛奶,鸡蛋,面包,薯片 鸡蛋,爆米花,薯片,啤酒 鸡蛋,面包,薯片 牛奶,鸡蛋,面包,爆米花,薯片,啤酒 牛奶,面包,啤酒 鸡蛋,面包,啤酒 牛奶,面包,薯片 牛奶,鸡蛋,面包,黄油,薯片 牛奶,鸡蛋,黄油,薯片
2. 得到所有的频繁项集如下:
0,2,3=4 2,4=3 0,1,2,3=3 3=6 2=7 1,2=5 1=7 0=7 0,3=5 0,2=6 0,1=5 4=4 0,1,2=4 0,1,3=4 1,3=5 1,4=3上面的频繁项集中,等号后面的是支持度;每条频繁项集显示的是经过编码的,编码的规则如下:{薯片=0, 牛奶=3, 鸡蛋=2, 面包=1, 啤酒=4}。同时,可以看到上面的频繁项集中的编码是按照顺序排列的(从小到大);
计算每条频繁项集的置信度(只计算2项和2项以上的频繁项集):
1) 对于频繁n项集,查找其前向(前向定义为前面n-1项集,比如频繁项集:0,2,3那么其前向为0,2)的支持度,如果频繁n项集存在,那么其前向(频繁n-1项集)必然存在(如果频繁项集是所有的频繁项集的话,这个规则一定是成立的);
2)使用n项集的支持度除以n项集的前向的支持度即可得到n项集的置信度;
3. 按照2中的计算方法是可以计算所有的频繁项集的置信度的,但是这里有个问题:只能计算比如0,2,3这个频繁项集的置信度,而不能计算0,3,2这个频繁项集的置信度(FP算法中频繁项集0,2,3和0,3,2是一样的频繁项集,但是计算置信度的时候就会不一样);
4. 针对3的问题,可以给出下面的解决方案;
针对每条记录(包含n个项),把每个项作为后向(定义为最后一个项,比如频繁项集0,1,2,3可以分别把0、1、2、3作为后向,输出相对于置信度不同的频繁项集),其他前向保持相对顺序不变;
比如针对频繁项集:0,1,2,3 =3,应该输出:
1,2,3,0=3
0,2,3,1=3
0,1,3,2=3
0,1,2,3=3
由于针对同一个后向,其前向的顺序其实对于计算置信度是没有影响的(比如针对0作为后向,1,2,3和2,1,3和3,2,1其支持度应该是一样的),这样对于算法来说其输出的含有置信度的频繁项集是比较完备的;
使用4的方法把原来FP树的频繁项集进行扩充即可得到2中计算方法的数据了。
5. 针对4的输出(4的输出其实只是频繁项集和支持度,较3的结果来说只是把1条记录变为了n条而已),计算各个频繁项集的置信度,其实就是两个表的互查,即以A表的n项频繁集参考B表的n-1项频繁集来计算n项置信度,A表和B表是一样的。可以使用MapReduce的思路,稍后细说。
参考Mahout的单机FP实现,给出的计算置信度的代码主要如下:
1. 由于mahout里面的实现其交互是和HDFS文件交互的,这里可以和本地文件进行交互,或者直接存入内存,本文的实现是直接存入内存的,如果要存入文件也是可以的(不过可能要经过过滤重复记录的操作);
所以把单机版的FP中某些代码做了修改,比如下面的代码:
// generateTopKFrequentPatterns(new TransactionIterator<A>( // transactionStream, attributeIdMapping), attributeFrequency, // minSupport, k, reverseMapping.size(), returnFeatures, // new TopKPatternsOutputConverter<A>(output, reverseMapping), // updater);修改为下面的代码:
generateTopKFrequentPatterns(new TransactionIterator<A>( transactionStream, attributeIdMapping), attributeFrequency, minSupport, k, reverseMapping.size(), returnFeatures,reverseMapping );这种修改在FPTree里面有很多,就不一一赘述,详情参考本文源码下载的工程;
2. 由于mahout的FP树最后输出的频繁项集是经过整合的,所以有些频繁项集没有输出(即只输出了最大频繁项集),而上面提出的算法是需要所有频繁项集都进行输出的,所以在函数generateSinglePathPatterns(FPTree tree, int k,long minSupport) 和函数generateSinglePathPatterns(FPTree tree,int k,long minSupport)的return中加上一句:
addFrequentPatternMaxHeap(frequentPatterns);
这个方法的具体代码为:
/**
* 存储所有频繁项集
* @param patternsOut
*/
private static void addFrequentPatternMaxHeap(FrequentPatternMaxHeap patternsOut){
String[] pStr=null;
// 这里的Pattern有问题,暂时使用字符串解析
for(Pattern p:patternsOut.getHeap()){
pStr=p.toString().split("-");
if(pStr.length<=0){
continue;
}
// 对字符串进行下处理,这样可以减少存储
pStr[0]=pStr[0].replaceAll(" ", "");
pStr[0]=pStr[0].substring(1,pStr[0].length()-1);
if(patterns.containsKey(pStr[0])){
if(patterns.get(pStr[0])<p.support()){// 只取支持度最大的
patterns.remove(pStr[0]);
patterns.put(pStr[0], p.support());
}
}else{
patterns.put(pStr[0], p.support());
}
}
}这里假定这样的操作可以得到所有的频繁项集,并且存入到了patterns静态map变量中。
3. 根据思路第4中的描述,把FP产生的频繁项集进行扩充:
/**
* 根据排序频繁相机支持度 生成多频繁项集支持度
*/
public void generateFatPatterns(){
int[] patternInts=null;
for(String p :patterns.keySet()){
patternInts = getIntsFromPattern(p);
if(patternInts.length==1){// 针对频繁一项集
fatPatterns.put(String.valueOf(patternInts[0]), patterns.get(p));
}else{
putInts2FatPatterns(patternInts,patterns.get(p));
}
}
}
/**
* 把数组中的每一项作为后向进行输出,添加到fatpatterns中
* @param patternInts
* @param support
*/
private void putInts2FatPatterns(int[] patternInts, Long support) {
// TODO Auto-generated method stub
String patternStr =Ints2Str(patternInts);
fatPatterns.put(patternStr, support);// 处理最后一个后向
for(int i=0;i<patternInts.length-1;i++){// 最后一个后向在前面已经处理
// 不能使用同一个数组
patternStr=Ints2Str(swap(patternInts,i,patternInts.length-1));
fatPatterns.put(patternStr, support);
}
}
public void savePatterns(String output,Map<String,Long> map){
// 清空patternsMap
patternsMap.clear();
String preItem=null;
for(String p:map.keySet()){
// 单项没有前向,不用找
if(p.lastIndexOf(",")==-1){
continue;
}
// 找出前向
preItem = p.substring(0, p.lastIndexOf(","));
if(map.containsKey(preItem)){
// patterns.get(p) 支持度,patterns.get(preItem)前向支持度
patternsMap.put(p, map.get(p)*1.0/map.get(preItem));
}
}
FPTreeDriver.createFile(patternsMap, output);
}由于把频繁项集和支持度都放入了Map中,所以这样计算比较简单。
对比使用扩充的和没有使用扩充的频繁项集产生的关联规则如下图所示:
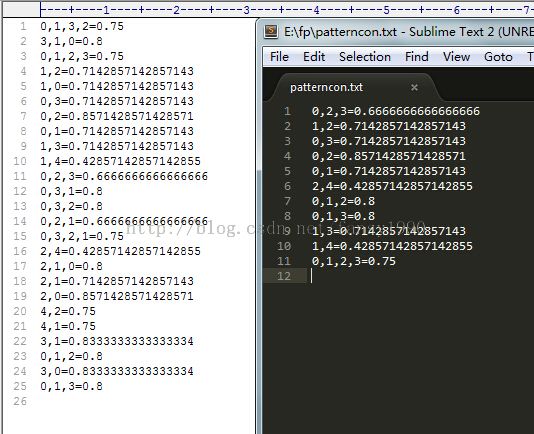
这里可以看到扩充后的关联规则1,3和3,1 是不一样的,其置信度一个是0.714,一个是0.8,所以可以解释为从1推出3的概率没有从3推出1的概率大。举个生活简单的实例:买了电视机,再买遥控器的概率肯定比买了遥控器再买电视机的概率大。
但是如果所有扩充后的频繁项集和支持度数据太大而不能完全放入内存应该如何操作呢。
这里可以使用MapReduce的思路来实现。
这里可以使用MapReduce的思路来实现。
MapReduce实现计算置信度的思路:
0. 这里假设已经得到了扩充后的频繁项集的支持度,并存在与HDFS文件系统上面,假设为文件A;
1. 把文件A复制一份得到文件B;
1. 把文件A复制一份得到文件B;
2. 参考《hadoop多文件格式输入》http://blog.csdn.net/fansy1990/article/details/26267637,设计两个不同的Mapper,一个处理A,一个处理B。对A的处理为直接输出频繁项集,输出的key为频繁项集,value是支持度和A的标签;对B的处理为输出所有的频繁项集中项大于1的频繁项集,其输出的key是频繁项集的前向(定义为频繁项集前面n-1个项),value是频繁项集的后向(后向定义为频繁项集的最后一项)和支持度和标签。
3. 在2中不同的Mapper进行处理的数据会在Reducer中进行汇集。在Reducer中进行如下的处理:针对相同的key,遍历其value集合,如果被贴了A标签那么就赋值一个变量,用于做分母,如果是B标签那么就进行计算,计算是把B标签的数据的支持度除以刚才A标签的变量,得到置信度confidence,输出的key为输入的key+B标签的后向,value是confidence。
比如A的输出为 <(0,2,3),5+A>; 其中(0,2,3)为频繁项集,是key;5+A是value,其中5是支持度,A是标签
B中的输出为:
<(0,2,3),4+3+B> ;
其中(0,2,3,4)为频繁项集,key是前向(0,2,3);4+3+B是value,其中4是后向,3是支持度,B是标签;
<(0,2,3),5+3+B> ; 其中(0,2,3,5)为频繁项集,key是前向(0,2,3);5+3+B是value,其中5是后向,3是支持度,B是标签;
<(0,2,3),6+2+B>;其中(0,2,3,6)为频繁项集,key是前向(0,2,3);6+2+B是value,其中6是后向,2是支持度,B是标签;
那么Reducer中汇总的数据就是:
<(0,2,3),[(5+A),(4+3+B),
(5+3+B),(6+2+B)>;
遍历其中的value集合,首先,把标签A的支持度作为分母,即分母是5;
接着, 遍历B的标签,比如(4+3+B),由于是B的标签那么就计算支持度除以A的分母为3/5 , 输出为<(0,2,3,4),3/5>;
接着遍历,即可输出:
<(0,2,3,5),3/5>; <(0,2,3,6),2/5>; 等记录;
这里需要注意
1)当Reducer中只有A的标签数据时,这时是不需要进行输出的,因为这个是最大频繁项集,不能作为任何频繁项集的前向;
2)上面的value可以自行设计为自定义Writable类型,而不是简单的字符串;
3) 计算置信度的MapReduce代码暂没有实现,本文提供的下载是单机版的,且扩充频繁项集是可以放入内存的;
分享,成长,快乐
转载请注明blog地址:http://blog.csdn.net/fansy1990