NAND速度优化探索
使用的硬件平台为博通7231,NAND型号为K9GAG08U0E。
最初的情况是这样的,此款cpu的nand控制器不支持DMA,另外默认的主频是108M的,经过测试flash的读速度为4M/s左右,对于系统性能有一定的限制(软件启动速度,系统开机速度等),后来更改nand控制器主频为206M,CE信号的低、高电平时间适量缩短(这个是最重要的,这个缩短之后,一个读周期就会大大缩短,比提高主频效果还明显,主频提高,但是这两个参数不动的话,一个读周期并缩短不了多少)。这样之后,读速度提高到8M/s左右。最后的情况是。8M/s可以说已经是极限了。由于cpu硬件的限制导致了nand读写速度的瓶颈。通过分析波形图,最后得出结论,主要是由于IO速度太慢(而这个已经无法提高了)造成的。
下面是抓得波形图及一些简单说明:
信号1:RE信号(读使能)。
信号2:GPIO参考波形(用于定位读操作的各个时间点)。
NAND_TIMING_1_CS2设置的值:0x33424236
NAND_TIMING_2_CS2设置的值:0x80001ef6
波形简单说明:
根据NAND_TIMING_1_CS2寄存器的设置,RE信号一个周期为28ns。
1.由波形可知,一个PAGE 8K 数据分8次传输,每次1K,由图tek00012.bmp可知,1K数据传输需要32us,而RE一个周期为28ns,正好是1K的数据。
2.由波形图可知RE信号每个1K数据之间有80us的空闲,如果能把这个时间减小,那么flash读取速度就能有较大的提高。
3.由图tek0008.bmp,tek0009.bmp,tek00011.bmp可看出,那80us的空闲主要花费在3个部分,两个高脉冲分别为两次循环读取512数据的时间(参考下面的代码),这个并不是恒定的,可能与系统调度有关。一个低脉冲时间应该是花费在把另外512 byte内容准备到cache中。各个阶段花费时间都在图中可以看出。(关于这个每次读512Byte在博通手册中有说明)
对GPIO的操作代码(drivers/mtd/nand/brcmstb_nand.c):
static void brcmstb_nand_read_by_pio(struct mtd_info *mtd,
struct nand_chip *chip, u64 addr, unsigned int trans,
u32 *buf, u8 *oob)
{
struct brcmstb_nand_host *host = chip->priv;
int i, j;
for (i = 0; i < trans; i++, addr += FC_BYTES) {
BDEV_WR_RB(BCHP_NAND_CMD_ADDRESS, addr & 0xffffffff);
/* SPARE_AREA_READ does not use ECC, so just use PAGE_READ */
/***发送读命令之前把参考GPIO拉低***/
GPIO_SETZERO(0);
brcmstb_nand_send_cmd(CMD_PAGE_READ);
brcmstb_nand_waitfunc(mtd, chip);
/***数据准备好之后拉高***/
GPIO_SETONE(0);
if (likely(buf))
for (j = 0; j < FC_WORDS; j++, buf++){
*buf = le32_to_cpu(BDEV_RD(FC(j)));
}
/***循环读取512Byte数据***/
GPIO_SETZERO(0);
if (oob)
oob += read_oob_from_regs(i, oob, mtd->oobsize / trans, host->hwcfg.sector_size_1k);
}
}

tek00005
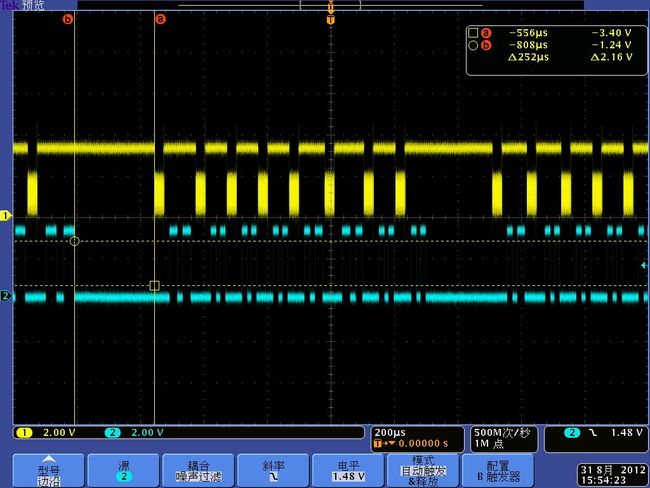
tek00006
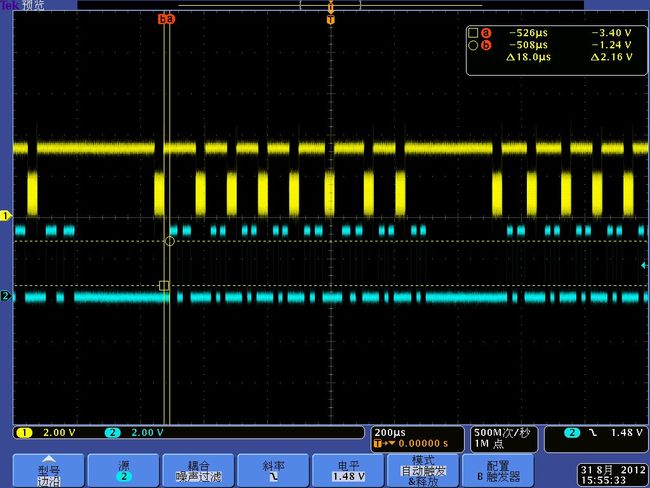
tek00007
tek00008
tek00009
tek000011
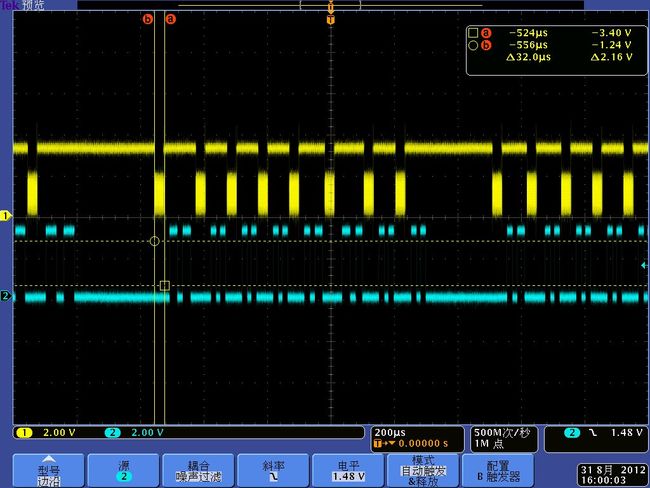
tek000012
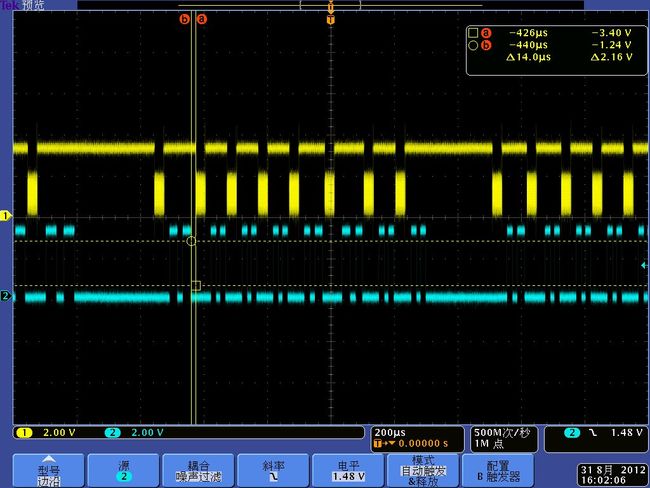
tek00013