DPM(Defomable Parts Model) 源码分析
DPM(Deformable Parts Model)--原理(一)
原文:http://blog.csdn.net/ttransposition/article/details/12966521
DPM(Deformable Parts Model)
Reference:
Object detection with discriminatively trained partbased models. IEEE Trans. PAMI, 32(9):1627–1645, 2010.
"Support Vector Machines for Multiple-Instance Learning,"Proc. Advances in Neural Information Processing Systems,2003.
作者主页:http://www.cs.berkeley.edu/~rbg/latent/index.html
-
大体思路
DPM是一个非常成功的目标检测算法,连续获得VOC(Visual Object Class)07,08,09年的检测冠军。目前已成为众多分类器、分割、人体姿态和行为分类的重要部分。2010年Pedro Felzenszwalb被VOC授予"终身成就奖"。DPM可以看做是HOG(Histogrrams of Oriented Gradients)的扩展,大体思路与HOG一致。先计算梯度方向直方图,然后用SVM(Surpport Vector Machine )训练得到物体的梯度模型(Model)。有了这样的模板就可以直接用来分类了,简单理解就是模型和目标匹配。DPM只是在模型上做了很多改进工作。

上图是HOG论文中训练出来的人形模型。它是单模型,对直立的正面和背面人检测效果很好,较以前取得了重大的突破。也是目前为止最好的的特征(最近被CVPR20 13年的一篇论文 《Histograms of Sparse Codes for Object Detection》 超过了)。但是, 如果是侧面呢?所以自然我们会想到用多模型来做。DPM就使用了2个模型,主页上最新版本Versio5的程序使用了12个模型。


上图就是自行车的模型,左图为侧面看,右图为从正前方看。好吧,我承认已经面目全非了,这只是粗糙版本。训练的时候只是给了一堆自行车的照片,没有标注是属于component 1,还是component 2.直接按照边界的长宽比,分为2半训练。这样肯定会有很多很多分错了的情况,训练出来的自然就失真了。不过没关系,论文里面只是把这两个Model当做初始值。重点就是作者用了多模型。

上图右边的两个模型各使用了6个子模型,白色矩形框出来的区域就是一个子模型。基本上见过自行车的人都知道这是自行车。之所以会比左边好辨识,是因为分错component类别的问题基本上解决了,还有就是图像分辨率是左边的两倍,这个就不细说,看论文。
有了多模型就能解决视角的问题了,还有个严重的问题,动物是动的,就算是没有生命的车也有很多款式,单单用一个Model,如果动物动一下,比如美女搔首弄姿,那模型和这个美女的匹配程度就低了很多。也就是说,我们的模型太死板了,不能适应物体的运动,特别是非刚性物体的运动。自然我们又能想到添加子模型,比如给手一个子模型,当手移动时,子模型能够检测到手的位置。把子模型和主模型的匹配程度综合起来,最简单的就是相加,那模型匹配程度不就提高了吗?思路很简单吧!还有个小细节,子模型肯定不能离主模型太远了,试想下假如手到身体的位置有两倍身高那么远,那这还是人吗?也许这是个检测是不是鬼的好主意。所以我们加入子模型与主模型的位置偏移作为Cost,也就是说综合得分要减去偏移Cost.本质上就是使用子模型和主模型的空间先验知识。

好了,终于来了一张合影。最右边就是我们的偏移Cost,圆圈中心自然就是子模型的理性位置,如果检测出来的子模型的位置恰好在此,那Cost就为0,在周边那就要减掉一定的值,偏离的越远减掉的值越大。
最后再理一下继承发展关系,HOG特征源自于SIFT,参见《Distinctive image features from scale-invariant Keypoints》。Part Model 早在1973年就被提出参见《The representation and matching of pictorial structures》(木有看……)。
另外HOG特征可以参考鄙人博客:Opencv HOG行人检测 源码分析SIFT特征本来也想写的但是,那时候懒,而且表述比较啰嗦,就参考一位跟我同一届的北大美女的系列博客吧。【OpenCV】SIFT原理与源码分析
总之,DPM的本质就是弹簧形变模型,参见 1973年的一篇论文 The representation and matching of pictorial structures

2.检测
检测过程比较简单:
综合得分:

![]() 是rootfilter (我前面称之为主模型)的得分,或者说是匹配程度,本质就是
是rootfilter (我前面称之为主模型)的得分,或者说是匹配程度,本质就是![]() 和
和![]() 的卷积,后面的partfilter也是如此。中间是n个partfilter(前面称之为子模型)的得分。
的卷积,后面的partfilter也是如此。中间是n个partfilter(前面称之为子模型)的得分。![]() 是为了component之间对齐而设的rootoffset.
是为了component之间对齐而设的rootoffset.![]()
![]() 为rootfilter的left-top位置在root feature map中的坐标,
为rootfilter的left-top位置在root feature map中的坐标,![]() 为第
为第![]() 个partfilter映射到part feature map中的坐标。
个partfilter映射到part feature map中的坐标。![]() 是因为part feature map的分辨率是root feature map的两倍,
是因为part feature map的分辨率是root feature map的两倍,![]() 为相对于rootfilter left-top 的偏移。
为相对于rootfilter left-top 的偏移。
![]() 的得分如下:
的得分如下:

上式是在patfilter理想位置![]() ,即anchor position的一定范围内,寻找一个综合匹配和形变最优的位置。
,即anchor position的一定范围内,寻找一个综合匹配和形变最优的位置。![]() 为偏移向量,
为偏移向量,![]() 为偏移向量
为偏移向量![]() ,
,![]()
![]() 为偏移的Cost权值。比如
为偏移的Cost权值。比如![]() 则
则![]()
![]() 即为最普遍的欧氏距离。这一步称为距离变换,即下图中的transformed response。这部分的主要程序有train.m、featpyramid.m、dt.cc.
即为最普遍的欧氏距离。这一步称为距离变换,即下图中的transformed response。这部分的主要程序有train.m、featpyramid.m、dt.cc.

3.训练
3.1多示例学习(Multiple-instance learning)
3.1.1 MI-SVM
一般机器学习算法,每一个训练样本都需要类别标号(对于二分类:1/-1)。实际上那样的数据其实已经经过了抽象,实际的数据要获得这样的标号还是很难,图像就是个典型。还有就是数据标记的工作量太大,我们想偷懒了,所以多只是给了正负样本集。负样本集里面的样本都是负的,但是正样本里面的样本不一定都是正的,但是至少有一个样本是正的。比如检测人的问题,一张天空的照片就可以是一个负样本集;一张某某自拍照就是一个正样本集(你可以在N个区域取N个样本,但是只有部分是有人的正样本)。这样正样本的类别就很不明确,传统的方法就没法训练。
疑问来了,图像的不是有标注吗?有标注就应该有类别标号啊?这是因为图片是人标的,数据量特大,难免会有些标的不够好,这就是所谓的弱监督集(weakly supervised set)。所以如果算法能够自动找出最优的位置,那分类器不就更精确吗? 标注位置不是很准确,这个例子不是很明显,还记得前面讲过的子模型的位置吗?比如自行车的车轮的位置,是完全没有位置标注的,只知道在bounding box区域附件有一个车轮。不知道精确位置,就没法提取样本。这种情况下,车轮会有很多个可能的位置,也就会形成一个正样本集,但里面只有部分是包含轮子的。
针对上述问题《Support Vector Machines for Multiple-Instance Learning》提出了MI-SVM。本质思想是将标准SVM的最大化样本间距扩展为最大化样本集间距。具体来说是选取正样本集中最像正样本的样本用作训练,正样本集内其它的样本就等候发落。同样取负样本中离分界面最近的负样本作为负样本。因为我们的目的是要保证正样本中有正,负样本不能为正。就基本上化为了标准SVM。取最大正样本(离分界面最远),最小负样本(离分界面最近):

对于正样本:![]() 为正样本集中选中的最像大正样本的样本。
为正样本集中选中的最像大正样本的样本。
对于负样本:可以将max展开,因为最小的负样本满足的话,其余负样本就都能满足,所以任意负样本有:
![]()
目标函数:
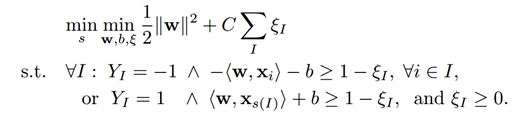
也就是说选取正样本集中最大的正样本,负样本集中的所有样本。与标准SVM的唯一不同之处在于拉格朗日系数的界限。
![]()
而标准SVM的约束是:
![]()
最终化为一个迭代优化问题:

思想很简单:第一步是在正样本集中优化;第二步是优化SVM模型。与K-Means这类聚类算法一样都只是简单的两步,却爆发了无穷的力量。
这里可以参考一篇博客Multiple-instance learning。
关于SVM的详细理论推导就不得不推荐我最为膜拜的MIT Doctor pluskid: 支持向量机系列
关于SVM的求解:SVM学习——Sequential Minimal Optimization
SVM学习——Coordinate Desent Method
此外,与多示例学习对应的还有多标记学习(multi-lable learning)有兴趣可以了解下。二者联系很大,多示例是输入样本的标记具有歧义(可正可负),而多标记是输出样本有歧义。
3.1.2 Latent SVM
1)Latent-SVM实质上和MI-SVM是一样的。区别在于扩展了Latent变量。首先解释下Latent变量,MI-SVM决定正样本集中哪一个样本作为正样本的![]() 就是一个latent变量。不过这个变量是单一的,比较简单,取值只是正样本集中的序号而已。DPM中也是要选择最大的正样本,但是它的latent变量就特别多。比如bounding box的实际位置,在HOG特征金字塔中的level,某样本属于哪一类component。也就是说我们有了一张正样本的图片,标注了bounding box,我们要在某一位置,某一尺度,提取出一个最大正样本作为某一component的正样本。
就是一个latent变量。不过这个变量是单一的,比较简单,取值只是正样本集中的序号而已。DPM中也是要选择最大的正样本,但是它的latent变量就特别多。比如bounding box的实际位置,在HOG特征金字塔中的level,某样本属于哪一类component。也就是说我们有了一张正样本的图片,标注了bounding box,我们要在某一位置,某一尺度,提取出一个最大正样本作为某一component的正样本。
直接看Latent-SVM的训练过程:

这一部分还牵扯到了Data-minig。先不管,先只看循环中的3-6,12.
3-6就对于MI-SVM的第一步。12就对应了MI-SVM的第二步。作者这里直接用了梯度下降法,求解最优模型β。
2)现在说下Data-minig。作者为什么不直接优化,还搞个Data-minig干嘛呢?因为,负样本数目巨大,Version3中用到的总样本数为2^28,其中Pos样本数目占的比例特别低,负样本太多,直接导致优化过程很慢,因为很多负样本远离分界面对于优化几乎没有帮助。Data-minig的作用就是去掉那些对优化作用很小的Easy-examples保留靠近分界面的Hard-examples。分别对应13和10。这样做的的理论支撑证明如下:

3)再简单说下随机梯度下降法(Stochastic Gradient Decent):
首先梯度表达式:
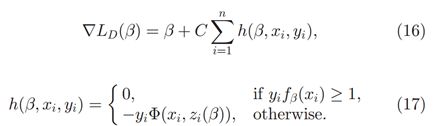
梯度近似:
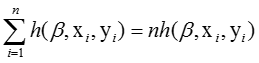
优化流程:

这部分的主要程序:pascal_train.m->train.m->detect.m->learn.cc
3.2 训练初始化
LSVM对初始值很敏感,因此初始化也是个重头戏。分为三个阶段。英语方面我就不班门弄斧了,直接上截图。



![]()

下面稍稍提下各阶段的工作,主要是论文中没有的Latent 变量分析:
Phase1:是传统的SVM训练过程,与HOG算法一致。作者是随机将正样本按照aspect ration(长宽比)排序,然后很粗糙的均分为两半训练两个component的rootfilte。这两个rootfilter的size也就直接由分到的pos examples决定了。后续取正样本时,直接将正样本缩放成rootfilter的大小。
Phase2:是LSVM训练。Latent variables 有图像中正样本的实际位置包括空间位置(x,y),尺度位置level,以及component的类别c,即属于component1 还是属于 component 2。要训练的参数为两个 rootfilter,offset(b)
Phase3:也是LSVM过程。
先提下子模型的添加。作者固定了每个component有6个partfilter,但实际上还会根据实际情况减少。为了减少参数,partfilter都是对称的。partfilter在rootfilter中的锚点(anchor location)在按最大energy选取partfilter的时候就已经固定下来了。
这阶段的Latent variables是最多的有:rootfilter(x,y,scale),partfilters(x,y,scale)。要训练的参数为 rootfilters, rootoffset, partfilters, defs(![]() 的偏移Cost)。
的偏移Cost)。
这部分的主要程序:pascal_train.m
-
4.细节
4.1轮廓预测(Bounding Box Prediction)


仔细看下自行车的左轮,如果我们只用rootfilter检测出来的区域,即红色区域,那么前轮会被切掉一部分,但是如果能综合partfilter检测出来的bounding box就能得到更加准确的bounding box如右图。
这部分很简单就是用最小二乘(Least Squres)回归,程序中trainbox.m中直接左除搞定。
4.2 HOG
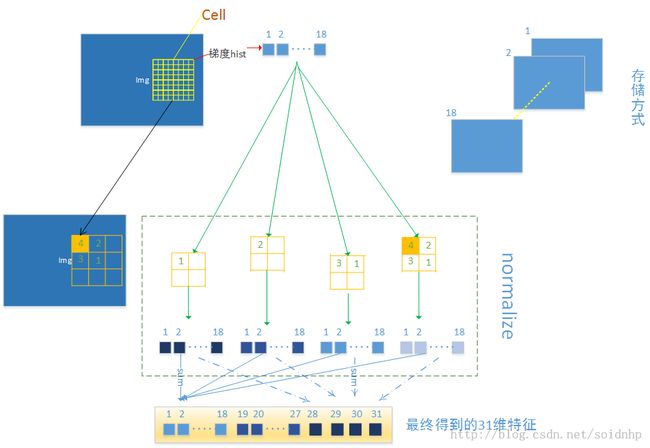
作者对HOG进行了很大的改动。作者没有用4*9=36维向量,而是对每个8x8的cell提取18+9+4=31维特征向量。作者还讨论了依据PCA(Principle Component Analysis)可视化的结果选9+4维特征,能达到HOG 4*9维特征的效果。
这里很多就不细说了。开题一个字都还没写,要赶着开题……主要是features.cc。有了下面这张图,自己慢慢研究下:
源码分析:
DPM(Defomable Parts Model) 源码分析-检测
DPM(Defomable Parts Model) 源码分析-训练
DPM(Defomable Parts Model) 源码分析-检测(二)
原文:http://blog.csdn.net/ttransposition/article/details/12954195
DPM(Defomable Parts Model)原理
首先声明此版本为V3.1。因为和论文最相符。V4增加了模型数由2个增加为6个,V5提取了语义特征。源码太长纯代码应该在2K+,只选取了核心部分代码
demo.m
- function demo()
- test('000034.jpg', 'car');
- test('000061.jpg', 'person');
- test('000084.jpg', 'bicycle');
- function test(name, cls)
- % load and display image
- im=imread(name);
- clf;
- image(im);
- axis equal;
- axis on;
- disp('input image');
- disp('press any key to continue'); pause;
- % load and display model
- load(['VOC2007/' cls '_final']); %加载模型
- visualizemodel(model);
- disp([cls ' model']);
- disp('press any key to continue'); pause;
- % detect objects
- boxes = detect(im, model, 0); %model为mat中的结构体
- top = nms(boxes, 0.5); %Non-maximum suppression.
- showboxes(im, top);
- %print(gcf, '-djpeg90', '-r0', [cls '.jpg']);
- disp('detections');
- disp('press any key to continue'); pause;
- % get bounding boxes
- bbox = getboxes(model, boxes); %根据检测到的root,parts,预测bounding
- top = nms(bbox, 0.5);
- bbox = clipboxes(im, top); %预测出来的bounding,可能会超过图像原始尺寸,所以要减掉
- showboxes(im, bbox);
- disp('bounding boxes');
- disp('press any key to continue'); pause;
detect.m
- function [boxes] = detect(input, model, thresh, bbox, ...
- overlap, label, fid, id, maxsize)
- % 论文 fig.4
- % boxes = detect(input, model, thresh, bbox, overlap, label, fid, id, maxsize)
- % Detect objects in input using a model and a score threshold.
- % Higher threshold leads to fewer detections.
- % boxes = [rx1 ry1 rx2 ry2 | px1 py1 px2 py2 ...| componetindex | score ]
- % The function returns a matrix with one row per detected object. The
- % last column of each row gives the score of the detection. The
- % column before last specifies the component used for the detection.
- % The first 4 columns specify the bounding box for the root filter and
- % subsequent columns specify the bounding boxes of each part.
- %
- % If bbox is not empty, we pick best detection with significant overlap.
- % If label and fid are included, we write feature vectors to a data file.
- %phase 2: im, model, 0, bbox, overlap, 1, fid, 2*i-1
- % trian boxex : detect(im, model, 0, bbox, overlap)
- if nargin > 3 && ~isempty(bbox)
- latent = true;
- else
- latent = false;
- end
- if nargin > 6 && fid ~= 0
- write = true;
- else
- write = false;
- end
- if nargin < 9
- maxsize = inf;
- end
- % we assume color images
- input = color(input); %如果是灰度图,扩充为三通道 R=G=B=Gray
- % prepare model for convolutions
- rootfilters = [];
- for i = 1:length(model.rootfilters) %
- rootfilters{i} = model.rootfilters{i}.w;% r*w*31维向量,9(方向范围 0~180) +18(方向范围 0-360)+4(cell熵和)
- end
- partfilters = [];
- for i = 1:length(model.partfilters)
- partfilters{i} = model.partfilters{i}.w;
- end
- % cache some data 获取所有 root,part的所有信息
- for c = 1:model.numcomponents % releas3.1 一种对象,只有2个模型,releas5 有3*2个模型
- ridx{c} = model.components{c}.rootindex; % m1=1,m2=2
- oidx{c} = model.components{c}.offsetindex; %o1=1,o2=2
- root{c} = model.rootfilters{ridx{c}}.w;
- rsize{c} = [size(root{c},1) size(root{c},2)]; %root size,单位为 sbin*sbin的block块,相当于原始HOG中的一个cell
- numparts{c} = length(model.components{c}.parts); %目前为固定值6个,但是有些part是 fake
- for j = 1:numparts{c}
- pidx{c,j} = model.components{c}.parts{j}.partindex; %part是在该对象的所有component的part下连续编号
- didx{c,j} = model.components{c}.parts{j}.defindex; % 在 rootfiter中的 anchor location
- part{c,j} = model.partfilters{pidx{c,j}}.w; % 6*6*31
- psize{c,j} = [size(part{c,j},1) size(part{c,j},2)]; %
- % reverse map from partfilter index to (component, part#)
- rpidx{pidx{c,j}} = [c j];
- end
- end
- % we pad the feature maps to detect partially visible objects
- padx = ceil(model.maxsize(2)/2+1); % 7/2+1 = 5
- pady = ceil(model.maxsize(1)/2+1); % 11/2+1 = 7
- % the feature pyramid
- interval = model.interval; %10
- %--------------------------------特征金字塔---------------------------------------------------------
- % feat的尺寸为 img.rows/sbin,img.cols/sbin
- % scales:缩放了多少
- [feat, scales] = featpyramid(input, model.sbin, interval); % 8,10
- % detect at each scale
- best = -inf;
- ex = [];
- boxes = [];
- %---------------------逐层检测目标-----------------------------------------------------------%
- for level = interval+1:length(feat) %注意是从第二层开始
- scale = model.sbin/scales(level); % 1/缩小了多少
- if size(feat{level}, 1)+2*pady < model.maxsize(1) || ... %扩展后还是未能达到 能同时计算两个component的得分
- size(feat{level}, 2)+2*padx < model.maxsize(2) || ...
- (write && ftell(fid) >= maxsize) %已经没有空间保存样本了
- continue;
- end
- if latent %训练时使用,检测时跳过
- skip = true;
- for c = 1:model.numcomponents
- root_area = (rsize{c}(1)*scale) * (rsize{c}(2)*scale);% rootfilter
- box_area = (bbox(3)-bbox(1)+1) * (bbox(4)-bbox(2)+1); % bbox该class 所有 rootfilter 的交集即minsize
- if (root_area/box_area) >= overlap && (box_area/root_area) >= overlap %这句话真纠结,a>=0.7b,b>=0.7a -> a>=0.7b>=0.49a
- skip = false;
- end
- end
- if skip
- continue;
- end
- end
- % -----------convolve feature maps with filters -----------
- %rootmatch,partmatch ,得分图root的尺度总是part的一半,
- %rootmatch尺寸是partmatch的一半
- featr = padarray(feat{level}, [pady padx 0], 0); % 上下各补充 pady 行0,左右各补充padx行 0
- %C = fconv(A, cell of B, start, end);
- rootmatch = fconv(featr, rootfilters, 1, length(rootfilters));
- if length(partfilters) > 0
- featp = padarray(feat{level-interval}, [2*pady 2*padx 0], 0);
- partmatch = fconv(featp, partfilters, 1, length(partfilters));
- end
- %-------------------逐component检测-----------------------------------
- % 参见论文 Fig 4
- % 最终得到 综合得分图 score
- for c = 1:model.numcomponents
- % root score + offset
- score = rootmatch{ridx{c}} + model.offsets{oidx{c}}.w;
- % add in parts
- for j = 1:numparts{c}
- def = model.defs{didx{c,j}}.w;
- anchor = model.defs{didx{c,j}}.anchor;
- % the anchor position is shifted to account for misalignment
- % between features at different resolutions
- ax{c,j} = anchor(1) + 1; %
- ay{c,j} = anchor(2) + 1;
- match = partmatch{pidx{c,j}};
- [M, Ix{c,j}, Iy{c,j}] = dt(-match, def(1), def(2), def(3), def(4)); % dx,dy,dx^2,dy^2的偏移惩罚系数
- % M part的综合匹配得分图,与part尺寸一致。Ix{c,j}, Iy{c,j} 即part实际的最佳位置(相对于root)
- % 参见论文公式 9
- score = score - M(ay{c,j}:2:ay{c,j}+2*(size(score,1)-1), ...
- ax{c,j}:2:ax{c,j}+2*(size(score,2)-1));
- end
- %-------阈值淘汰------------------------
- if ~latent
- % get all good matches
- % ---thresh 在 分类时为0,在 找 hard exmaple 时是 -1.05--
- I = find(score > thresh); %返回的是从上到下从左到右的索引
- [Y, X] = ind2sub(size(score), I); %还原为 行,列坐标
- tmp = zeros(length(I), 4*(1+numparts{c})+2); %一个目标的root,part,score信息,见程序开头说明
- for i = 1:length(I)
- x = X(i);
- y = Y(i);
- [x1, y1, x2, y2] = rootbox(x, y, scale, padx, pady, rsize{c});
- b = [x1 y1 x2 y2];
- if write
- rblocklabel = model.rootfilters{ridx{c}}.blocklabel;
- oblocklabel = model.offsets{oidx{c}}.blocklabel;
- f = featr(y:y+rsize{c}(1)-1, x:x+rsize{c}(2)-1, :);
- xc = round(x + rsize{c}(2)/2 - padx); %
- yc = round(y + rsize{c}(1)/2 - pady);
- ex = [];
- ex.header = [label; id; level; xc; yc; ...
- model.components{c}.numblocks; ...
- model.components{c}.dim];
- ex.offset.bl = oblocklabel;
- ex.offset.w = 1;
- ex.root.bl = rblocklabel;
- width1 = ceil(rsize{c}(2)/2);
- width2 = floor(rsize{c}(2)/2);
- f(:,1:width2,:) = f(:,1:width2,:) + flipfeat(f(:,width1+1:end,:));
- ex.root.w = f(:,1:width1,:);
- ex.part = [];
- end
- for j = 1:numparts{c}
- [probex, probey, px, py, px1, py1, px2, py2] = ...
- partbox(x, y, ax{c,j}, ay{c,j}, scale, padx, pady, ...
- psize{c,j}, Ix{c,j}, Iy{c,j});
- b = [b px1 py1 px2 py2];
- if write
- if model.partfilters{pidx{c,j}}.fake
- continue;
- end
- pblocklabel = model.partfilters{pidx{c,j}}.blocklabel;
- dblocklabel = model.defs{didx{c,j}}.blocklabel;
- f = featp(py:py+psize{c,j}(1)-1,px:px+psize{c,j}(2)-1,:);
- def = -[(probex-px)^2; probex-px; (probey-py)^2; probey-py];
- partner = model.partfilters{pidx{c,j}}.partner;
- if partner > 0
- k = rpidx{partner}(2);
- [kprobex, kprobey, kpx, kpy, kpx1, kpy1, kpx2, kpy2] = ...
- partbox(x, y, ax{c,k}, ay{c,k}, scale, padx, pady, ...
- psize{c,k}, Ix{c,k}, Iy{c,k});
- kf = featp(kpy:kpy+psize{c,k}(1)-1,kpx:kpx+psize{c,k}(2)-1,:);
- % flip linear term in horizontal deformation model
- kdef = -[(kprobex-kpx)^2; kpx-kprobex; ...
- (kprobey-kpy)^2; kprobey-kpy];
- f = f + flipfeat(kf);
- def = def + kdef;
- else
- width1 = ceil(psize{c,j}(2)/2);
- width2 = floor(psize{c,j}(2)/2);
- f(:,1:width2,:) = f(:,1:width2,:) + flipfeat(f(:,width1+1:end,:));
- f = f(:,1:width1,:);
- end
- ex.part(j).bl = pblocklabel;
- ex.part(j).w = f;
- ex.def(j).bl = dblocklabel;
- ex.def(j).w = def;
- end
- end
- if write
- exwrite(fid, ex); % 写入负样本
- end
- tmp(i,:) = [b c score(I(i))];
- end
- boxes = [boxes; tmp];
- end
- if latent
- % get best match
- for x = 1:size(score,2)
- for y = 1:size(score,1)
- if score(y, x) > best
- % 以该(y,x)为left-top点的rootfilter的范围在原图像中的位置
- [x1, y1, x2, y2] = rootbox(x, y, scale, padx, pady, rsize{c});
- % intesection with bbox
- xx1 = max(x1, bbox(1));
- yy1 = max(y1, bbox(2));
- xx2 = min(x2, bbox(3));
- yy2 = min(y2, bbox(4));
- w = (xx2-xx1+1);
- h = (yy2-yy1+1);
- if w > 0 && h > 0
- % check overlap with bbox
- inter = w*h;
- a = (x2-x1+1) * (y2-y1+1); % rootfilter 的面积
- b = (bbox(3)-bbox(1)+1) * (bbox(4)-bbox(2)+1); % bbox的面积
- % 计算很很独特,如果只是 inter / b 那么 如果a很大,只是一部分与 bounding box重合,那就不可靠了,人再怎么标注错误,也不会这么大
- % 所以,a越大,要求的重合率越高才好,所以分母+a,是个不错的选择,但是这样减小的太多了,所以减去 inter
- o = inter / (a+b-inter);
- if (o >= overlap)
- %
- best = score(y, x);
- boxes = [x1 y1 x2 y2];
- % 这一部分一直被覆盖,最后保留的是 best样本
- if write
- f = featr(y:y+rsize{c}(1)-1, x:x+rsize{c}(2)-1, :);
- rblocklabel = model.rootfilters{ridx{c}}.blocklabel;
- oblocklabel = model.offsets{oidx{c}}.blocklabel;
- xc = round(x + rsize{c}(2)/2 - padx);
- yc = round(y + rsize{c}(1)/2 - pady);
- ex = [];
- % label; id; level; xc; yc,正样本的重要信息!
- % xc,yc,居然是相对于剪切后的图片
- ex.header = [label; id; level; xc; yc; ...
- model.components{c}.numblocks; ...
- model.components{c}.dim];
- ex.offset.bl = oblocklabel;
- ex.offset.w = 1;
- ex.root.bl = rblocklabel;
- width1 = ceil(rsize{c}(2)/2);
- width2 = floor(rsize{c}(2)/2);
- f(:,1:width2,:) = f(:,1:width2,:) + flipfeat(f(:,width1+1:end,:));
- ex.root.w = f(:,1:width1,:); %样本特征
- ex.part = [];
- end
- for j = 1:numparts{c}
- %probex,probey综合得分最高的位置,相对于featp
- %px1,py1,px2,py2 转化成相对于featr
- [probex, probey, px, py, px1, py1, px2, py2] = ...
- partbox(x, y, ax{c,j}, ay{c,j}, scale, ...
- padx, pady, psize{c,j}, Ix{c,j}, Iy{c,j});
- boxes = [boxes px1 py1 px2 py2];
- if write
- if model.partfilters{pidx{c,j}}.fake
- continue;
- end
- p = featp(py:py+psize{c,j}(1)-1, ...
- px:px+psize{c,j}(2)-1, :);
- def = -[(probex-px)^2; probex-px; (probey-py)^2; probey-py];
- pblocklabel = model.partfilters{pidx{c,j}}.blocklabel;
- dblocklabel = model.defs{didx{c,j}}.blocklabel;
- partner = model.partfilters{pidx{c,j}}.partner;
- if partner > 0
- k = rpidx{partner}(2);
- [kprobex, kprobey, kpx, kpy, kpx1, kpy1, kpx2, kpy2] = ...
- partbox(x, y, ax{c,k}, ay{c,k}, scale, padx, pady, ...
- psize{c,k}, Ix{c,k}, Iy{c,k});
- kp = featp(kpy:kpy+psize{c,k}(1)-1, ...
- kpx:kpx+psize{c,k}(2)-1, :);
- % flip linear term in horizontal deformation model
- kdef = -[(kprobex-kpx)^2; kpx-kprobex; ...
- (kprobey-kpy)^2; kprobey-kpy];
- p = p + flipfeat(kp);
- def = def + kdef;
- else
- width1 = ceil(psize{c,j}(2)/2);
- width2 = floor(psize{c,j}(2)/2);
- p(:,1:width2,:) = p(:,1:width2,:) + ...
- flipfeat(p(:,width1+1:end,:));
- p = p(:,1:width1,:);
- end
- ex.part(j).bl = pblocklabel;
- ex.part(j).w = p;
- ex.def(j).bl = dblocklabel;
- ex.def(j).w = def;
- end
- end
- boxes = [boxes c best];
- end
- end
- end
- end
- end
- end
- end
- end
- if latent && write && ~isempty(ex)
- exwrite(fid, ex); %datfile
- end
- % The functions below compute a bounding box for a root or part
- % template placed in the feature hierarchy.
- %
- % coordinates need to be transformed to take into account:
- % 1. padding from convolution
- % 2. scaling due to sbin & image subsampling
- % 3. offset from feature computation
- %
- function [x1, y1, x2, y2] = rootbox(x, y, scale, padx, pady, rsize)
- x1 = (x-padx)*scale+1; %图像是先缩放(构造金字塔时)再打补丁
- y1 = (y-pady)*scale+1;
- x2 = x1 + rsize(2)*scale - 1; % 宽度也要缩放
- y2 = y1 + rsize(1)*scale - 1;
- function [probex, probey, px, py, px1, py1, px2, py2] = ...
- partbox(x, y, ax, ay, scale, padx, pady, psize, Ix, Iy)
- probex = (x-1)*2+ax; %最优位置
- probey = (y-1)*2+ay;
- px = double(Ix(probey, probex)); %综合得分最高的位置
- py = double(Iy(probey, probex));
- px1 = ((px-2)/2+1-padx)*scale+1; % pading是root的两倍
- py1 = ((py-2)/2+1-pady)*scale+1;
- px2 = px1 + psize(2)*scale/2 - 1;
- py2 = py1 + psize(1)*scale/2 - 1;
- % write an example to the data file
- function exwrite(fid, ex)
- fwrite(fid, ex.header, 'int32');
- buf = [ex.offset.bl; ex.offset.w(:); ...
- ex.root.bl; ex.root.w(:)];
- fwrite(fid, buf, 'single');
- for j = 1:length(ex.part)
- if ~isempty(ex.part(j).w)
- buf = [ex.part(j).bl; ex.part(j).w(:); ...
- ex.def(j).bl; ex.def(j).w(:)];
- fwrite(fid, buf, 'single');
- end
- end
features.cc
- #include <math.h>
- #include "mex.h"
- // small value, used to avoid division by zero
- #define eps 0.0001
- #define bzero(a, b) memset(a, 0, b)
- int round(float a) { float tmp = a - (int)a; if( tmp >= 0.5 ) return (int)a + 1; else return (int)a; }
- // unit vectors used to compute gradient orientation
- // cos(20*i)
- double uu[9] = {1.0000,
- 0.9397,
- 0.7660,
- 0.500,
- 0.1736,
- -0.1736,
- -0.5000,
- -0.7660,
- -0.9397};
- //sin(20*i)
- double vv[9] = {0.0000,
- 0.3420,
- 0.6428,
- 0.8660,
- 0.9848,
- 0.9848,
- 0.8660,
- 0.6428,
- 0.3420};
- static inline double min(double x, double y) { return (x <= y ? x : y); }
- static inline double max(double x, double y) { return (x <= y ? y : x); }
- static inline int min(int x, int y) { return (x <= y ? x : y); }
- static inline int max(int x, int y) { return (x <= y ? y : x); }
- // main function:
- // takes a double color image and a bin size
- // returns HOG features
- mxArray *process(const mxArray *mximage, const mxArray *mxsbin) {
- double *im = (double *)mxGetPr(mximage);
- const int *dims = mxGetDimensions(mximage);
- if (mxGetNumberOfDimensions(mximage) != 3 ||
- dims[2] != 3 ||
- mxGetClassID(mximage) != mxDOUBLE_CLASS)
- mexErrMsgTxt("Invalid input");
- int sbin = (int)mxGetScalar(mxsbin);
- // memory for caching orientation histograms & their norms
- int blocks[2];
- blocks[0] = (int)round((double)dims[0]/(double)sbin);//行
- blocks[1] = (int)round((double)dims[1]/(double)sbin);//列
- double *hist = (double *)mxCalloc(blocks[0]*blocks[1]*18, sizeof(double));//只需要计算18bin,9bin的推
- double *norm = (double *)mxCalloc(blocks[0]*blocks[1], sizeof(double));
- // memory for HOG features
- int out[3];//size
- out[0] = max(blocks[0]-2, 0);//减去2干嘛??
- out[1] = max(blocks[1]-2, 0);
- out[2] = 27+4;
- mxArray *mxfeat = mxCreateNumericArray(3, out, mxDOUBLE_CLASS, mxREAL);//特征,size=out
- double *feat = (double *)mxGetPr(mxfeat);
- int visible[2];
- visible[0] = blocks[0]*sbin;
- visible[1] = blocks[1]*sbin;
- //先列再行
- for (int x = 1; x < visible[1]-1; x++) {
- for (int y = 1; y < visible[0]-1; y++) {
- // first color channel
- double *s = im + min(x, dims[1]-2)*dims[0] + min(y, dims[0]-2);//在im中的位置
- double dy = *(s+1) - *(s-1);
- double dx = *(s+dims[0]) - *(s-dims[0]); //坐标系是一样的,c和matlab的存储顺序不一样
- double v = dx*dx + dy*dy;
- // second color channel
- s += dims[0]*dims[1];
- double dy2 = *(s+1) - *(s-1);
- double dx2 = *(s+dims[0]) - *(s-dims[0]);
- double v2 = dx2*dx2 + dy2*dy2;
- // third color channel
- s += dims[0]*dims[1];
- double dy3 = *(s+1) - *(s-1);
- double dx3 = *(s+dims[0]) - *(s-dims[0]);
- double v3 = dx3*dx3 + dy3*dy3;
- // pick channel with strongest gradient,计算v
- if (v2 > v) {
- v = v2;
- dx = dx2;
- dy = dy2;
- }
- if (v3 > v) {
- v = v3;
- dx = dx3;
- dy = dy3;
- }
- // snap to one of 18 orientations,就算角度best_o
- double best_dot = 0;
- int best_o = 0;
- for (int o = 0; o < 9; o++) {
- // (sinθ)^2+(cosθ)^2 =1
- // max cosθ*dx+ sinθ*dy 对其求导,可得极大值 θ = arctan dy/dx
- double dot = uu[o]*dx + vv[o]*dy;
- if (dot > best_dot) {
- best_dot = dot;
- best_o = o;
- } else if (-dot > best_dot) {
- best_dot = -dot;
- best_o = o+9;
- }
- }
- // add to 4 histograms around pixel using linear interpolation
- double xp = ((double)x+0.5)/(double)sbin - 0.5;
- double yp = ((double)y+0.5)/(double)sbin - 0.5;
- int ixp = (int)floor(xp);
- int iyp = (int)floor(yp);
- double vx0 = xp-ixp;
- double vy0 = yp-iyp;
- double vx1 = 1.0-vx0;
- double vy1 = 1.0-vy0;
- v = sqrt(v);
- //左上角
- if (ixp >= 0 && iyp >= 0) {
- *(hist + ixp*blocks[0] + iyp + best_o*blocks[0]*blocks[1]) +=
- vx1*vy1*v;
- }
- //右上角
- if (ixp+1 < blocks[1] && iyp >= 0) {
- *(hist + (ixp+1)*blocks[0] + iyp + best_o*blocks[0]*blocks[1]) +=
- vx0*vy1*v;
- }
- //左下角
- if (ixp >= 0 && iyp+1 < blocks[0]) {
- *(hist + ixp*blocks[0] + (iyp+1) + best_o*blocks[0]*blocks[1]) +=
- vx1*vy0*v;
- }
- //右下角
- if (ixp+1 < blocks[1] && iyp+1 < blocks[0]) {
- *(hist + (ixp+1)*blocks[0] + (iyp+1) + best_o*blocks[0]*blocks[1]) +=
- vx0*vy0*v;
- }
- }
- }
- // compute energy in each block by summing over orientations
- //计算每一个cell的 sum( ( v(oi)+v(oi+9) )^2 ),oi=0..8
- for (int o = 0; o < 9; o++) {
- double *src1 = hist + o*blocks[0]*blocks[1];
- double *src2 = hist + (o+9)*blocks[0]*blocks[1];
- double *dst = norm;
- double *end = norm + blocks[1]*blocks[0];
- while (dst < end) {
- *(dst++) += (*src1 + *src2) * (*src1 + *src2);
- src1++;
- src2++;
- }
- }
- // compute features
- for (int x = 0; x < out[1]; x++) {
- for (int y = 0; y < out[0]; y++) {
- double *dst = feat + x*out[0] + y;
- double *src, *p, n1, n2, n3, n4;
- p = norm + (x+1)*blocks[0] + y+1;//右下角的constrain insensitive sum
- n1 = 1.0 / sqrt(*p + *(p+1) + *(p+blocks[0]) + *(p+blocks[0]+1) + eps);
- p = norm + (x+1)*blocks[0] + y;//右边
- n2 = 1.0 / sqrt(*p + *(p+1) + *(p+blocks[0]) + *(p+blocks[0]+1) + eps);
- p = norm + x*blocks[0] + y+1;//下边
- n3 = 1.0 / sqrt(*p + *(p+1) + *(p+blocks[0]) + *(p+blocks[0]+1) + eps);
- p = norm + x*blocks[0] + y;//自己
- n4 = 1.0 / sqrt(*p + *(p+1) + *(p+blocks[0]) + *(p+blocks[0]+1) + eps);
- double t1 = 0;
- double t2 = 0;
- double t3 = 0;
- double t4 = 0;
- // contrast-sensitive features
- src = hist + (x+1)*blocks[0] + (y+1);
- for (int o = 0; o < 18; o++) {
- double h1 = min(*src * n1, 0.2);//截短
- double h2 = min(*src * n2, 0.2);
- double h3 = min(*src * n3, 0.2);
- double h4 = min(*src * n4, 0.2);
- *dst = 0.5 * (h1 + h2 + h3 + h4);//求和
- t1 += h1;
- t2 += h2;
- t3 += h3;
- t4 += h4;
- dst += out[0]*out[1];//下一个bin
- src += blocks[0]*blocks[1];
- }
- // contrast-insensitive features
- src = hist + (x+1)*blocks[0] + (y+1);
- for (int o = 0; o < 9; o++) {
- double sum = *src + *(src + 9*blocks[0]*blocks[1]);
- double h1 = min(sum * n1, 0.2);
- double h2 = min(sum * n2, 0.2);
- double h3 = min(sum * n3, 0.2);
- double h4 = min(sum * n4, 0.2);
- *dst = 0.5 * (h1 + h2 + h3 + h4);
- dst += out[0]*out[1];
- src += blocks[0]*blocks[1];
- }
- // texture features
- *dst = 0.2357 * t1;
- dst += out[0]*out[1];
- *dst = 0.2357 * t2;
- dst += out[0]*out[1];
- *dst = 0.2357 * t3;
- dst += out[0]*out[1];
- *dst = 0.2357 * t4;
- }
- }
- mxFree(hist);
- mxFree(norm);
- return mxfeat;
- }
- // matlab entry point
- // F = features(image, bin)
- // image should be color with double values
- void mexFunction(int nlhs, mxArray *plhs[], int nrhs, const mxArray *prhs[]) {
- if (nrhs != 2)
- mexErrMsgTxt("Wrong number of inputs");
- if (nlhs != 1)
- mexErrMsgTxt("Wrong number of outputs");
- plhs[0] = process(prhs[0], prhs[1]);
- }
dt.cc
- #include <math.h>
- #include <sys/types.h>
- #include "mex.h"
- #define int32_t int
- /*
- * Generalized distance transforms.
- * We use a simple nlog(n) divide and conquer algorithm instead of the
- * theoretically faster linear method, for no particular reason except
- * that this is a bit simpler and I wanted to test it out.
- *
- * The code is a bit convoluted because dt1d can operate either along
- * a row or column of an array.
- */
- static inline int square(int x) { return x*x; }
- // dt helper function
- void dt_helper(double *src, double *dst, int *ptr, int step,
- int s1, int s2, int d1, int d2, double a, double b) {
- if (d2 >= d1) {
- int d = (d1+d2) >> 1;
- int s = s1;
- for (int p = s1+1; p <= s2; p++)
- if (src[s*step] + a*square(d-s) + b*(d-s) >
- src[p*step] + a*square(d-p) + b*(d-p))
- s = p;
- dst[d*step] = src[s*step] + a*square(d-s) + b*(d-s);
- ptr[d*step] = s;
- dt_helper(src, dst, ptr, step, s1, s, d1, d-1, a, b);
- dt_helper(src, dst, ptr, step, s, s2, d+1, d2, a, b);
- }
- }
- // dt of 1d array
- void dt1d(double *src, double *dst, int *ptr, int step, int n,
- double a, double b) {
- dt_helper(src, dst, ptr, step, 0, n-1, 0, n-1, a, b);
- }
- // matlab entry point
- // [M, Ix, Iy] = dt(vals, ax, bx, ay, by)
- void mexFunction(int nlhs, mxArray *plhs[], int nrhs, const mxArray *prhs[]) {
- if (nrhs != 5)
- mexErrMsgTxt("Wrong number of inputs");
- if (nlhs != 3)
- mexErrMsgTxt("Wrong number of outputs");
- if (mxGetClassID(prhs[0]) != mxDOUBLE_CLASS)
- mexErrMsgTxt("Invalid input");
- const int *dims = mxGetDimensions(prhs[0]);
- double *vals = (double *)mxGetPr(prhs[0]);
- double ax = mxGetScalar(prhs[1]);
- double bx = mxGetScalar(prhs[2]);
- double ay = mxGetScalar(prhs[3]);
- double by = mxGetScalar(prhs[4]);
- mxArray *mxM = mxCreateNumericArray(2, dims, mxDOUBLE_CLASS, mxREAL);
- mxArray *mxIx = mxCreateNumericArray(2, dims, mxINT32_CLASS, mxREAL);
- mxArray *mxIy = mxCreateNumericArray(2, dims, mxINT32_CLASS, mxREAL);
- double *M = (double *)mxGetPr(mxM);
- int32_t *Ix = (int32_t *)mxGetPr(mxIx);
- int32_t *Iy = (int32_t *)mxGetPr(mxIy);
- double *tmpM = (double *)mxCalloc(dims[0]*dims[1], sizeof(double)); // part map
- int32_t *tmpIx = (int32_t *)mxCalloc(dims[0]*dims[1], sizeof(int32_t));
- int32_t *tmpIy = (int32_t *)mxCalloc(dims[0]*dims[1], sizeof(int32_t));
- for (int x = 0; x < dims[1]; x++)
- dt1d(vals+x*dims[0], tmpM+x*dims[0], tmpIy+x*dims[0], 1, dims[0], ay, by);
- for (int y = 0; y < dims[0]; y++)
- dt1d(tmpM+y, M+y, tmpIx+y, dims[0], dims[1], ax, bx);
- // get argmins and adjust for matlab indexing from 1
- for (int x = 0; x < dims[1]; x++) {
- for (int y = 0; y < dims[0]; y++) {
- int p = x*dims[0]+y;
- Ix[p] = tmpIx[p]+1;
- Iy[p] = tmpIy[tmpIx[p]*dims[0]+y]+1;
- }
- }
- mxFree(tmpM);
- mxFree(tmpIx);
- mxFree(tmpIy);
- plhs[0] = mxM;
- plhs[1] = mxIx;
- plhs[2] = mxIy;
- }
DPM(Defomable Parts Model) 源码分析-训练(三)
原文:http://blog.csdn.net/ttransposition/article/details/12954631
DPM(Defomable Parts Model)原理
首先调用格式:
example:
pascal('person', 2); % train and evaluate a 2 component person model
pascal_train.m
- function model = pascal_train(cls, n) % n=2
- % model = pascal_train(cls)
- % Train a model using the PASCAL dataset.
- globals;
- %----------读取正负样本-----------------------
- % pos.im,neg.im存储了图像路径,pos.x1..pos.y2为box,负样本无box
- [pos, neg] = pascal_data(cls);
- % 按照长宽比,分成等量的两部分? 即将 component label 固定,phase2时,该值为latent variable。 spos为索引
- spos = split(pos, n);
- % -----------phase 1 : train root filters using warped positives & random negatives-----------
- try
- load([cachedir cls '_random']);
- catch
- % -----------------------------phas 1--------------------------------
- % 初始化 rootfilters
- for i=1:n
- models{i} = initmodel(spos{i});
- %---------train-------------
- % model.rootfilters{i}.w
- % model.offsets{i}.w
- models{i} = train(cls, models{i}, spos{i}, neg, 1, 1, 1, 1, 2^28);
- end
- save([cachedir cls '_random'], 'models');
- end
- % -----------------phase2-------------------------------------------
- % :merge models and train using latent detections & hard negatives
- try
- load([cachedir cls '_hard']);
- catch
- model = mergemodels(models);
- model = train(cls, model, pos, neg(1:200), 0, 0, 2, 2, 2^28, true, 0.7);
- save([cachedir cls '_hard'], 'model');
- end
- %----------------phase 3----------------------------------------------
- % add parts and update models using latent detections & hard negatives.
- try
- load([cachedir cls '_parts']);
- catch
- for i=1:n
- model = addparts(model, i, 6);
- end
- % use more data mining iterations in the beginning
- model = train(cls, model, pos, neg(1:200), 0, 0, 1, 4, 2^30, true, 0.7);
- model = train(cls, model, pos, neg(1:200), 0, 0, 6, 2, 2^30, true, 0.7, true);
- save([cachedir cls '_parts'], 'model');
- end
- % update models using full set of negatives.
- try
- load([cachedir cls '_mine']);
- catch
- model = train(cls, model, pos, neg, 0, 0, 1, 3, 2^30, true, 0.7, true, ...
- 0.003*model.numcomponents, 2);
- save([cachedir cls '_mine'], 'model');
- end
- % train bounding box prediction
- try
- load([cachedir cls '_final']);
- catch
- % 论文中说用最小二乘,怎么直接相除了,都不考虑矩阵的奇异性
- model = trainbox(cls, model, pos, 0.7);
- save([cachedir cls '_final'], 'model');
- end
initmodel.m
- function model = initmodel(pos, sbin, size)
- % model = initmodel(pos, sbin, size)
- % Initialize model structure.
- %
- % If not supplied the dimensions of the model template are computed
- % from statistics in the postive examples.
- %
- % This should be documented! :-)
- % model.sbin 8
- % model.interval 10
- % model.numblocks phase 1 :单独训练rootfilter时为2,offset,rootfilter;phase 2,为 4
- % model.numcomponents 1
- % model.blocksizes (1)=1,(2)= root.h*root.w/2*31
- % model.regmult 0,1
- % model.learnmult 20,1
- % model.maxsize root 的size
- % model.minsize
- % model.rootfilters{i}
- % .size 以sbin为单位,尺寸为综合各样本的h/w,area计算出来的
- % .w
- % .blocklabel blocklabel是为编号,offset(2),rootfilter(2),partfilter(12 or less),def (12 same as part)虽然意义不同但是放在一起统一编号
- % model.partfilters{i}
- % .w
- % .blocklabel
- % model.defs{i}
- % .anchor
- % .w
- % .blocklabel
- % model.offsets{i}
- % .w 0
- % .blocklabel 1
- % model.components{i}
- % .rootindex 1
- % .parts{j}
- % .partindex
- % .defindex
- % .offsetindex 1
- % .dim 2 + model.blocksizes(1) + model.blocksizes(2)
- % .numblocks 2
- % pick mode of aspect ratios
- h = [pos(:).y2]' - [pos(:).y1]' + 1;
- w = [pos(:).x2]' - [pos(:).x1]' + 1;
- xx = -2:.02:2;
- filter = exp(-[-100:100].^2/400); % e^-25,e^25
- aspects = hist(log(h./w), xx); %
- aspects = convn(aspects, filter, 'same');
- [peak, I] = max(aspects);
- aspect = exp(xx(I)); %滤波后最大的h/w,作为最典型的h/w
- % pick 20 percentile area
- areas = sort(h.*w);
- area = areas(floor(length(areas) * 0.2)); % 比它大的,可以缩放,比该尺寸小的呢?
- area = max(min(area, 5000), 3000); %限制在 3000-5000
- % pick dimensions
- w = sqrt(area/aspect);
- h = w*aspect;
- % size of HOG features
- if nargin < 4
- model.sbin = 8;
- else
- model.sbin = sbin;
- end
- % size of root filter
- if nargin < 5
- model.rootfilters{1}.size = [round(h/model.sbin) round(w/model.sbin)];
- else
- model.rootfilters{1}.size = size;
- end
- % set up offset
- model.offsets{1}.w = 0;
- model.offsets{1}.blocklabel = 1;
- model.blocksizes(1) = 1;
- model.regmult(1) = 0;
- model.learnmult(1) = 20;
- model.lowerbounds{1} = -100;
- % set up root filter
- model.rootfilters{1}.w = zeros([model.rootfilters{1}.size 31]);
- height = model.rootfilters{1}.size(1);
- % root filter is symmetricf
- width = ceil(model.rootfilters{1}.size(2)/2); % ??? /2
- model.rootfilters{1}.blocklabel = 2;
- model.blocksizes(2) = width * height * 31;
- model.regmult(2) = 1;
- model.learnmult(2) = 1;
- model.lowerbounds{2} = -100*ones(model.blocksizes(2),1);
- % set up one component model
- model.components{1}.rootindex = 1;
- model.components{1}.offsetindex = 1;
- model.components{1}.parts = {};
- model.components{1}.dim = 2 + model.blocksizes(1) + model.blocksizes(2);
- model.components{1}.numblocks = 2;
- % initialize the rest of the model structure
- model.interval = 10;
- model.numcomponents = 1;
- model.numblocks = 2;
- model.partfilters = {};
- model.defs = {};
- model.maxsize = model.rootfilters{1}.size;
- model.minsize = model.rootfilters{1}.size;
learn.cc
- #include <stdio.h>
- #include <stdlib.h>
- #include <string.h>
- #include <math.h>
- #include <sys/time.h>
- #include <errno.h>
- /*
- * Optimize LSVM objective function via gradient descent.
- *
- * We use an adaptive cache mechanism. After a negative example
- * scores beyond the margin multiple times it is removed from the
- * training set for a fixed number of iterations.
- */
- // Data File Format
- // EXAMPLE*
- //
- // EXAMPLE:
- // long label ints
- // blocks int
- // dim int
- // DATA{blocks}
- //
- // DATA:
- // block label float
- // block data floats
- //
- // Internal Binary Format
- // len int (byte length of EXAMPLE)
- // EXAMPLE <see above>
- // unique flag byte
- // number of iterations
- #define ITER 5000000
- // small cache parameters
- #define INCACHE 3
- #define WAIT 10
- // error checking
- #define check(e) \
- (e ? (void)0 : (printf("%s:%u error: %s\n%s\n", __FILE__, __LINE__, #e, strerror(errno)), exit(1)))
- // number of non-zero blocks in example ex
- #define NUM_NONZERO(ex) (((int *)ex)[labelsize+1])
- // float pointer to data segment of example ex
- #define EX_DATA(ex) ((float *)(ex + sizeof(int)*(labelsize+3)))
- // class label (+1 or -1) for the example
- #define LABEL(ex) (((int *)ex)[1])
- // block label (converted to 0-based index)
- #define BLOCK_IDX(data) (((int)data[0])-1)
- int labelsize;
- int dim;
- // comparison function for sorting examples
- // 参见 http://blog.sina.com.cn/s/blog_5155e8d401009145.html
- int comp(const void *a, const void *b) {
- // sort by extended label first, and whole example second...
- //逐字节比较的,当buf1<buf2时,返回值<0,当buf1=buf2时,返回值=0,当buf1>buf2时,返回值>0
- // 先比较这五个量 [label id level x y],也就是说按照 样本类别->id->level->x->y排序样本
- int c = memcmp(*((char **)a) + sizeof(int),
- *((char **)b) + sizeof(int),
- labelsize*sizeof(int));// 5
- if (c) //label 不相等
- return c;
- // labels are the same ,怎么可能会一样呢 id在正负样本集内从1开始是递增的啊 phase 2 阶段同一张图片产生的样本,id都是一样的
- int alen = **((int **)a);
- int blen = **((int **)b);
- if (alen == blen) //长度一样
- return memcmp(*((char **)a) + sizeof(int),
- *((char **)b) + sizeof(int),
- alen); //真霸气,所有字节都比较……
- return ((alen < blen) ? -1 : 1);//按长度排序
- }
- // a collapsed example is a sequence of examples
- struct collapsed {
- char **seq;
- int num;
- };
- // set of collapsed examples
- struct data {
- collapsed *x;
- int num;
- int numblocks;
- int *blocksizes;
- float *regmult;
- float *learnmult;
- };
- // seed the random number generator with the current time
- void seed_time() {
- struct timeval tp;
- check(gettimeofday(&tp, NULL) == 0);
- srand48((long)tp.tv_usec);
- }
- static inline double min(double x, double y) { return (x <= y ? x : y); }
- static inline double max(double x, double y) { return (x <= y ? y : x); }
- // gradient descent
- //---------------参照论文公式17 后的步骤---------------------------------------
- void gd(double C, double J, data X, double **w, double **lb) {
- // C=0.0002, J=1, X, w==0, lb==-100);
- //
- int num = X.num; //组数
- // state for random permutations
- int *perm = (int *)malloc(sizeof(int)*X.num);
- check(perm != NULL);
- // state for small cache
- int *W = (int *)malloc(sizeof(int)*num);
- check(W != NULL);
- for (int j = 0; j < num; j++)
- W[j] = 0;
- int t = 0;
- while (t < ITER) { // 5000000 ,霸气……
- // pick random permutation
- for (int i = 0; i < num; i++) //组数
- perm[i] = i;
- //-------打乱顺序-----
- // 论文中是随机选择一个样本,这里是随机排好序,再顺序取。
- // 类似于随机取,但是这里能保证取到全部样本,避免单个样本重复被抽到,重复作用
- for (int swapi = 0; swapi < num; swapi++) {
- int swapj = (int)(drand48()*(num-swapi)) + swapi; //drand48 产生 0-1之间的均匀分布
- int tmp = perm[swapi];
- perm[swapi] = perm[swapj];
- perm[swapj] = tmp;
- }
- // count number of examples in the small cache
- int cnum = 0; //下面的循环部分的实际循环次数
- for (int i = 0; i < num; i++) {
- if (W[i] <= INCACHE) // 3
- cnum++;
- }
- //-------------------------------------------------------
- for (int swapi = 0; swapi < num; swapi++) {
- // select example
- int i = perm[swapi];
- collapsed x = X.x[i];
- // skip if example is not in small cache
- //负样本分对一次+1,分错一次清为0
- //连续三次都分对了,那么这个样本很有可能是 easy 样本
- //直接让他罚停四次迭代
- if (W[i] > INCACHE) { //3
- W[i]--;
- continue;
- }
- // learning rate
- double T = t + 1000.0; //学习率,直接1/t太大了
- double rateX = cnum * C / T;
- double rateR = 1.0 / T;
- if (t % 10000 == 0) {
- printf(".");
- fflush(stdout); //清除文件缓冲区,文件以写方式打开时将缓冲区内容写入文件
- }
- t++;
- // compute max over latent placements
- // -----step 3----
- int M = -1;
- double V = 0;
- // 组内循环,选择 Zi=argmax β*f 即文中的第3部
- // 训练rootfiter时,x.num=1,因为随机产生的负样本其id不同
- for (int m = 0; m < x.num; m++) {
- double val = 0;
- char *ptr = x.seq[m];
- float *data = EX_DATA(ptr); //特征数据的地址 第9个数据开始,
- //后面跟着是 block1 label | block2 data|block2 lable | block2 data
- // 1 | 1 | 2 | h*w/2*31个float
- int blocks = NUM_NONZERO(ptr); // phase 1,phase 2 : 2 个,offset,rootfilter
- for (int j = 0; j < blocks; j++) {
- int b = BLOCK_IDX(data); //
- data++;
- for (int k = 0; k < X.blocksizes[b]; k++)//(1)=1,(2)= root.h*root.w/2*31
- val += w[b][k] * data[k]; //第一次循环是0
- data += X.blocksizes[b];
- }
- if (M < 0 || val > V) {
- M = m;
- V = val;
- }
- }
- // update model
- //-----step.4 也算了step.5 的一半 ---------------
- // 梯度下降,减小 w
- for (int j = 0; j < X.numblocks; j++) {// 2
- double mult = rateR * X.regmult[j] * X.learnmult[j]; // 0,1 20,1,1/T,对于block2,学习率at就是 1/t,block 1 为0
- for (int k = 0; k < X.blocksizes[j]; k++) {
- w[j][k] -= mult * w[j][k]; //不管是分对了,还是分错了,都要减掉 at*β,见公式17下的4,5
- }
- }
- char *ptr = x.seq[M];
- int label = LABEL(ptr);
- //----step.5----------分错了,往梯度的负方向移动
- if (label * V < 1.0)
- {
- W[i] = 0;
- float *data = EX_DATA(ptr);
- int blocks = NUM_NONZERO(ptr);
- for (int j = 0; j < blocks; j++) {
- int b = BLOCK_IDX(data);
- // yi*cnum * C / T*1,见论文中 公式16,17
- double mult = (label > 0 ? J : -1) * rateX * X.learnmult[b];
- data++;
- for (int k = 0; k < X.blocksizes[b]; k++)
- w[b][k] += mult * data[k];
- data += X.blocksizes[b];
- }
- } else if (label == -1)
- {
- if (W[i] == INCACHE) //3
- W[i] = WAIT; //10
- else
- W[i]++;
- }
- }
- // apply lowerbounds
- for (int j = 0; j < X.numblocks; j++) {
- for (int k = 0; k < X.blocksizes[j]; k++) {
- w[j][k] = max(w[j][k], lb[j][k]);
- }
- }
- }
- free(perm);
- free(W);
- }
- // score examples
- double *score(data X, char **examples, int num, double **w) {
- double *s = (double *)malloc(sizeof(double)*num);
- check(s != NULL);
- for (int i = 0; i < num; i++) {
- s[i] = 0.0;
- float *data = EX_DATA(examples[i]);
- int blocks = NUM_NONZERO(examples[i]);
- for (int j = 0; j < blocks; j++) {
- int b = BLOCK_IDX(data);
- data++;
- for (int k = 0; k < X.blocksizes[b]; k++)
- s[i] += w[b][k] * data[k];
- data += X.blocksizes[b];
- }
- }
- return s;
- }
- // merge examples with identical labels
- void collapse(data *X, char **examples, int num) {
- //&X, sorted, num_unique
- collapsed *x = (collapsed *)malloc(sizeof(collapsed)*num);
- check(x != NULL);
- int i = 0;
- x[0].seq = examples;
- x[0].num = 1;
- for (int j = 1; j < num; j++) {
- if (!memcmp(x[i].seq[0]+sizeof(int), examples[j]+sizeof(int),
- labelsize*sizeof(int))) {
- x[i].num++; //如果label 五个量相同
- } else {
- i++;
- x[i].seq = &(examples[j]);
- x[i].num = 1;
- }
- }
- X->x = x;
- X->num = i+1;
- }
- //调用参数 C=0.0002, J=1, hdrfile, datfile, modfile, inffile, lobfile
- int main(int argc, char **argv) {
- seed_time();
- int count;
- data X;
- // command line arguments
- check(argc == 8);
- double C = atof(argv[1]);
- double J = atof(argv[2]);
- char *hdrfile = argv[3];
- char *datfile = argv[4];
- char *modfile = argv[5];
- char *inffile = argv[6];
- char *lobfile = argv[7];
- // read header file
- FILE *f = fopen(hdrfile, "rb");
- check(f != NULL);
- int header[3];
- count = fread(header, sizeof(int), 3, f);
- check(count == 3);
- int num = header[0]; //正负样本总数
- labelsize = header[1]; // labelsize = 5; [label id level x y]
- X.numblocks = header[2]; // 2
- X.blocksizes = (int *)malloc(X.numblocks*sizeof(int)); //(1)=1,(2)= root.h*root.w/2*31
- count = fread(X.blocksizes, sizeof(int), X.numblocks, f);
- check(count == X.numblocks);
- X.regmult = (float *)malloc(sizeof(float)*X.numblocks); //0 ,1
- check(X.regmult != NULL);
- count = fread(X.regmult, sizeof(float), X.numblocks, f);
- check(count == X.numblocks);
- X.learnmult = (float *)malloc(sizeof(float)*X.numblocks);//20, 1
- check(X.learnmult != NULL);
- count = fread(X.learnmult, sizeof(float), X.numblocks, f);
- check(count == X.numblocks);
- check(num != 0);
- fclose(f);
- printf("%d examples with label size %d and %d blocks\n",
- num, labelsize, X.numblocks);
- printf("block size, regularization multiplier, learning rate multiplier\n");
- dim = 0;
- for (int i = 0; i < X.numblocks; i++) {
- dim += X.blocksizes[i];
- printf("%d, %.2f, %.2f\n", X.blocksizes[i], X.regmult[i], X.learnmult[i]);
- }
- // ---------------从 datfile 读取 正负 examples----------------
- // examples [i] 存储了第i个样本的信息 长度为 1 int + 7 int +dim 个float + 1 byte
- // 1 int legth 样本包括信息头在内的总字节长度
- // 7 int [1/-1 id 0 0 0 2 dim] ,id为样本编号,[label id level centry_x centry_y],2是block个数
- // dim float feature,dim=2+1+root.h*root.w/2*31,意义如下
- // block1 label | block2 data|block2 lable | block2 data
- // 1 | 1 | 2 | h*w/2*31个float
- // 1 byte unique=0
- f = fopen(datfile, "rb");
- check(f != NULL);
- printf("Reading examples\n");
- //+,-example数据
- char **examples = (char **)malloc(num*sizeof(char *));
- check(examples != NULL);
- for (int i = 0; i < num; i++) {
- // we use an extra byte in the end of each example to mark unique
- // we use an extra int at the start of each example to store the
- // example's byte length (excluding unique flag and this int)
- //[legth label id level x y unique] unique=0
- int buf[labelsize+2];
- //写入时的值为[1/-1 i 0 0 0 2 dim]
- count = fread(buf, sizeof(int), labelsize+2, f);
- check(count == labelsize+2);
- // byte length of an example's data segment
- //---前面七个是头,后面dim个float是样本特征数据,dim=2+1+root.h*root.w/2*31
- int len = sizeof(int)*(labelsize+2) + sizeof(float)*buf[labelsize+1];
- // memory for data, an initial integer, and a final byte
- examples[i] = (char *)malloc(sizeof(int)+len+1);
- check(examples[i] != NULL);
- // set data segment's byte length
- ((int *)examples[i])[0] = len;
- // set the unique flag to zero
- examples[i][sizeof(int)+len] = 0;
- // copy label data into example
- for (int j = 0; j < labelsize+2; j++)
- ((int *)examples[i])[j+1] = buf[j];
- // read the rest of the data segment into the example
- count = fread(examples[i]+sizeof(int)*(labelsize+3), 1,
- len-sizeof(int)*(labelsize+2), f);
- check(count == len-sizeof(int)*(labelsize+2));
- }
- fclose(f);
- printf("done\n");
- // sort
- printf("Sorting examples\n");
- char **sorted = (char **)malloc(num*sizeof(char *));
- check(sorted != NULL);
- memcpy(sorted, examples, num*sizeof(char *));
- //qsort 库函数,真正的比较函数为 comp
- //从小到大,快速排序
- //依次按照 样本类别->id->level->cx->cy 排序样本
- //如果前面五个量都一样……
- //1.等长度,比较所有字节;
- //2.谁长谁小,长度不同是因为不同的component的 尺寸不一致
- qsort(sorted, num, sizeof(char *), comp);
- printf("done\n");
- // find unique examples
- // 唯一的样本,unique flag=1,
- // 相同的样本第一个样本的unique flag为1,其余为0 ,有的样本的位置被,unique替代了,但是并没有完全删除掉
- int i = 0;
- int len = *((int *)sorted[0]); //负样本的第一个
- sorted[0][sizeof(int)+len] = 1; // unique flag 置 1
- for (int j = 1; j < num; j++) {
- int alen = *((int *)sorted[i]);
- int blen = *((int *)sorted[j]);
- if (alen != blen || memcmp(sorted[i] + sizeof(int), sorted[j] + sizeof(int), alen)) //component不同 || 不同样本
- {
- i++;
- sorted[i] = sorted[j];
- sorted[i][sizeof(int)+blen] = 1; //标记为 unique
- }
- }
- int num_unique = i+1;
- printf("%d unique examples\n", num_unique);
- // -------------------collapse examples----------------
- // 前面是找完全不一样的样本,这里是分组
- // label 的五个量 [label id level centry_x centry_y] 相同的分为一组,在detect时,写入了datfile
- // 负样本的 cx,cy都是相对于整张图片的,正样本是相对于剪切后的图像
- // 前面五个全相同,
- // 对于phase1 不可能,因为正负样本的id都不相同
- // 对于phase2 正样本只保留了最有可能是正样本的样本,只有一种情况,
- // rootfilter1,rootfilter2在同一张图片(id相同),检测出来的 Hard负样本 的cx,cy相同,因此一组最多应该只能出现2个 (待验证)
- // 原因是此时的latent variable 为(cx,cy,component),上述情况相下,我们只能保留component1或者component2
- // 后续训练时,这两个量是连续使用的,为什么呢??
- // collapse.seq(char **) 记录了每一组的第一个样本
- // collapse.num 每组的个数
- // X.num 组数
- // X.x=&collapse[0],也就是第一个 collapse的地址
- collapse(&X, sorted, num_unique);
- printf("%d collapsed examples\n", X.num);
- // initial model
- // 读modfile文件,得到w的初始值。phase 1 初始化为全 0,phase 2 为上一次训练的结果……
- double **w = (double **)malloc(sizeof(double *)*X.numblocks);//2
- check(w != NULL);
- f = fopen(modfile, "rb");
- for (int i = 0; i < X.numblocks; i++) {
- w[i] = (double *)malloc(sizeof(double)*X.blocksizes[i]); //(1)=1,(2)= root.h*root.w/2*31
- check(w[i] != NULL);
- count = fread(w[i], sizeof(double), X.blocksizes[i], f);
- check(count == X.blocksizes[i]);
- }
- fclose(f);
- // lower bounds
- // 读lobfile文件,初始化为全 滤波器参数下线-100 ……
- double **lb = (double **)malloc(sizeof(double *)*X.numblocks);
- check(lb != NULL);
- f = fopen(lobfile, "rb");
- for (int i = 0; i < X.numblocks; i++) {
- lb[i] = (double *)malloc(sizeof(double)*X.blocksizes[i]);
- check(lb[i] != NULL);
- count = fread(lb[i], sizeof(double), X.blocksizes[i], f);
- check(count == X.blocksizes[i]);
- }
- fclose(f);
- printf("Training");
- //-------------------------------- train -------------------------------
- //-----梯度下降发训练参数 w,参见论文 公式17 后面的步骤
- gd(C, J, X, w, lb);
- printf("done\n");
- // save model
- printf("Saving model\n");
- f = fopen(modfile, "wb");
- check(f != NULL);
- // 存储 block1,block2的训练结果,w
- for (int i = 0; i < X.numblocks; i++) {
- count = fwrite(w[i], sizeof(double), X.blocksizes[i], f);
- check(count == X.blocksizes[i]);
- }
- fclose(f);
- // score examples
- // ---所有的样本都的得分,没有乘以 label y
- printf("Scoring\n");
- double *s = score(X, examples, num, w);
- // ---------Write info file-------------
- printf("Writing info file\n");
- f = fopen(inffile, "w");
- check(f != NULL);
- for (int i = 0; i < num; i++) {
- int len = ((int *)examples[i])[0];
- // label, score, unique flag
- count = fprintf(f, "%d\t%f\t%d\n", ((int *)examples[i])[1], s[i],
- (int)examples[i][sizeof(int)+len]);
- check(count > 0);
- }
- fclose(f);
- printf("Freeing memory\n");
- for (int i = 0; i < X.numblocks; i++) {
- free(w[i]);
- free(lb[i]);
- }
- free(w);
- free(lb);
- free(s);
- for (int i = 0; i < num; i++)
- free(examples[i]);
- free(examples);
- free(sorted);
- free(X.x);
- free(X.blocksizes);
- free(X.regmult);
- free(X.learnmult);
- return 0;
- }