PMML 标准介绍及其在数据挖掘任务中的应用
原文出处:http://www.ibm.com/developerworks/cn/xml/x-1107xuj/index.html
1. 背景
随着电子信息和计算机技术的快速发展,人类产生和搜集数据的能力获得了长足的发展。从商务、科学技术和政府部门等各行业的事务处理的计算机化,到消费数码产品、出版物和商品条码的广泛使用;从文本、语音、影像和卫星遥感系统等数据收集工具的进步,到全球信息系统万维网的普及,信息工作者已经淹没在数据和信息的汪洋大海中。如何从海量的数据提取出具有代表性的、事先未知的、但有具有潜在应用价值的知识模式,并能够按照商业应用目的进行分析和预测,就成为数据挖掘领域所要解决的主要问题。
数据挖掘任务主要由以下步骤组成:
- 定义数据字典:定义对分析问题有价值的数据变量。
- 预处理数据:通过对现有变量的衍生、映射、合并等操作,产生适合于建模的变量。
- 制定挖掘模式:指定数据挖掘建模过程处理异常值和缺失值的策略。
- 表示数据挖掘模型:记录模型的结构和参数等信息。
- 预测评价:将测试数据集应用于所获得的模型,以各种准则获得性能评。
PMML(Predictive Model Markup Language) 是一个开放的工业标准,它以 XML 为载体将上述数据挖掘任务标准化,可以把某一产品所创建的数据挖掘方案应用于任何其它遵从 PMML 标准的产品或平台中 , 而不需考虑分析和预测过程中的具体实现细节。使得模型的部署摆脱了模型开发和产品整合的束缚,为商业智能产品、数据仓库和云计算中的数据挖掘模型的应用环境开拓了新的篇章。
PMML 标准是数据挖掘过程的一个实例化标准,它按照数据挖掘任务执行过程,有序的定义了数据挖掘不同阶段的相关信息:
- 头信息
- 数据字典
- 数据转换
- 模型表示
- 预测评价
本章将结合数据挖掘任务步骤介绍 PMML 标准的不同模块及其功能。
2.1 头信息
一个 PMML 文件总是使用头信息作为开始,它主要用于记录产品、版权、建模时间等描述性信息。其语法如下:
清单 1. 头信息语法
<xs:element name="Header">
<xs:complexType>
<xs:sequence>
<xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded"/>
<xs:element minOccurs="0" ref="Application"/>
<xs:element minOccurs="0" maxOccurs="unbounded" ref="Annotation"/>
<xs:element minOccurs="0" ref="Timestamp"/>
</xs:sequence>
<xs:attribute name="copyright" type="xs:string" use="required"/>
<xs:attribute name="description" type="xs:string"/>
</xs:complexType>
</xs:element> |
其中:
- Header 是标识头信息部分的起始标记
- copyright 包含了所记录模型的版权信息
- description 包含可读的描述性信息
- Application 描述了生成本文件所含模型的软件产品。虽然 PMML 表示的是产品、平台无关的数据挖掘模型信息,但是了解建模产品的信息还是非常有意义的。
- Timestamp 记录了模型创建的时间。
以下是一段头信息的示例:
清单 2. 头信息示例
<Header copyright="(C) Copyright IBM Corp. 1994, 2011">
<Application name="IBM SPSS Modeler" version="14.1.0"/>
<Timestamp>Thu Jun 09 14:22:24 2011</Timestamp>
</Header> |
2.2 数据字典
数据是分析预测最主要的信息来源,PMML 标准指定了一系列的元素用于定义感兴趣的数据变量。数据字典即是在定义数据集中可能用于建模的数据变量过程中,详细指定了各变量的数据类型,操作类型和取值范围等数据属性信息,便于随后的数据变换,分析和建模。
清单 3 其中给出了一个名为 GENDER 的离散变量和一个名为 AGE 的连续变量是如何在数据字典中表示的。
清单 3. 数据字典示例
<DataDictionary>
<DataField name="GENDER" displayName="Gender" optype="categorical" dataType="string">
<Value value="f" displayValue="Female" property="valid"/>
<Value value="m" displayValue="Male" property="valid"/>
</DataField>
<DataField name="AGE" displayName="Age" optype="continuous" dataType="integer">
<Interval closure="closedClosed" leftMargin="0" rightMargin="100"/>
</DataField>
<!-- Other DataFields -->
</DataDictionary> |
从清单 3 中可以看出,定义数据变量的同时还可以指定数据有效值的范围。对于连续型变量 AGE,任何小于 0,大于 100 的取值在建模和预测的时候都将会被当成无效值。而对于离散型变量 GENDER 则罗列出其所有的有效值。
2.3 数据转换
一旦数据字典对数据集做出了定义,那么就可以在其之上进行各种数据转换的预处理操作。这是由于有时用户所提供的数据并不能直接用于建模,需要将原始的用户数据转换或映射成模型可以识别和使用的数据类型,这就需要使用数据转换来完成。譬如,神经网络模型内部仅能处理数值型的数据,如果用户数据中含有离散型数据,如性别包含“男”、“女”二值,那在建模前就需要将性别变量映射成 0 和 1 来分别表示“男”和“女”。
PMML 标准支持一些常用的数据转换预处理操作,并在此基础上支持使用函数表达式的转换。以下所列的是标准所定义的一些简单的数据转换操作:
- Normalization:将连续型或离散型变量转换成数值。常用于数据的归一化,或离散型变量的数值化。
- Discretization:将连续性变量转换成离散型变量。用于将数据分段表示,如将“AGE”按照“18<AGE<=45”、“45<AGE<59”和“60<=AGE”分段表示为青年、中年和老年。
- Value Mapping:将离散型变量映射成离散型变量。可以通过映射表给出数据的对应关系,如将“China”、“Korea”和“Japan”映射为“Asia”,将“USA”和“Canada”映射为“North America”。
- Functions:使用包含参数的函数生成新的数据变量。PMML 标准预定义一些常用的函数作为内建函数,同时支持用户通过内建函数构造自定义函数。
- Aggregation:对一个或多个数据变量进行聚合操作,对应于 SQL 中的 GROUP BY。支持求和,求平均,取最大值和最小值的操作。
清单 4 给出了一个使用 Discretization 的示例。通过两个给定的区间将连续型变量“Profit”转换成仅含“negative”和“positive”二值的离散变量。
清单 4. Discretization 示例
<Discretize field="Profit">
<DiscretizeBin binValue="negative">
<Interval closure="openOpen" rightMargin="0"/>
<!-- left margin is -infinity by default -->
</DiscretizeBin>
<DiscretizeBin binValue="positive">
<Interval closure="closedOpen" leftMargin="0"/>
<!-- right margin is +infinity by default -->
</DiscretizeBin>
</Discretize> |
清单 5 给出了一个使用 Functions 的示例,通过使用内建函数 if 和 isMissing 将变量“PREVEXP”中的缺失值替换为指定的均值。值得注意的是,替换了缺失值之后将产生一个新的变量“PREVEXP_without_missing”。
清单 5. Functions 示例
<DerivedField dataType="double" name="PREVEXP_without_missing"
optype="continuous">
<Apply function="if">
<Apply function="isMissing">
<FieldRef field="PREVEXP"/>
</Apply>
<Constant>mean</Constant>
<FieldRef field="PREVEXP"/>
</Apply>
</DerivedField> |
2.4 模型表示
预测模型是数据挖掘过程中最核心的部分。迄今为止,人们提出了许多的预测模型技术应用于不同的行业,但只用那些经实践证实并在数据挖掘领域被广泛采用的模型才能变成标准的一部分。目前 PMML 的最新版本是于 2009 年 6 月 16 日颁布的第四版,其中所支持的模型有:
- Association Model
- Clustering Model
- General Regression Model
- Mining Model
- Naive Bayes Model
- Neural Network
- Regression Model
- Rule Set Model
- Sequence Model
- Support Vector Machine Model
- Text Model
- Time Series Model
- Tree Model
这些模型都是帮助使用者从历史性的数据中提取出无法直观发现的,具有推广意义的数据模式。比如说 Association model,关联规则模型,常被用来发现大量交易数据中不同产品的购买关系和规则。使用其分析超市的销售单就可以发现,那些购买婴幼儿奶粉和护肤品的客户同时也会以较大的可能性去购买纸尿裤。这样有助于管理人员作出合理的商业决策,有导向的推动购物行为,比如将上述产品放在相邻的购物架上便于客户购买,从而产生更高的销售额。Tree model,树模型,也是很常用的模型,她采用类似树分支的结构将数据逐层划分成节点,而每个叶子节点就表示一个特别的类别。树模型受到应用领域广泛的欢迎,还有一个重要的原因就是她所做出的预测决策易于解释,能够快速推广。
上述的各种模型适用于不同的数据挖掘任务,按照其使用目的可以划分为不同的类别,PMML 的具体划分参见清单 6 所示:
清单 6. 模型功能划分
<xs:simpleType name="MINING-FUNCTION">
<xs:restriction base="xs:string">
<xs:enumeration value="associationRules"/>
<xs:enumeration value="sequences"/>
<xs:enumeration value="classification"/>
<xs:enumeration value="regression"/>
<xs:enumeration value="clustering"/>
<xs:enumeration value="timeSeries"/>
</xs:restriction>
</xs:simpleType> |
为了支持这些模型,PMML 标准提供了大量的语法来有针对性的表示不同的模型。由于不同的模型具有不同的结构和参数设置,涉及到模型的算法细节,这里不再一一详细介绍。
2.5 模型检验
如何评价所产生模型的预测分析能力呢?模型检验支持将模型应用于不用的数据集,并按照其所对应的功能给出相应的评价。Partition 可以用来将用户数据划分为不同的子集,如训练集,测试集和验证集。
针对预测型模型的质量评价,PMML 标准提供如下所示的功能:
清单 7. 预测模型质量评价
<xs:element name="PredictiveModelQuality">
<xs:complexType>
<xs:sequence>
<xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded"/>
<xs:element ref="ConfusionMatrix" minOccurs="0"/>
<xs:element ref="LiftData" minOccurs="0"/>
<xs:element ref="ROC" minOccurs="0"/>
</xs:sequence>
<xs:attribute name="targetField" type="xs:string" use="required"/>
<xs:attribute name="dataName" type="xs:string" use="optional"/>
<xs:attribute name="dataUsage" default="training">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="training"/>
<xs:enumeration value="test"/>
<xs:enumeration value="validation"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
<xs:attribute name="meanError" type="NUMBER" use="optional"/>
<xs:attribute name="meanAbsoluteError" type="NUMBER" use="optional"/>
<xs:attribute name="meanSquaredError" type="NUMBER" use="optional"/>
<xs:attribute name="r-squared" type="NUMBER" use="optional"/>
</xs:complexType>
</xs:element> |
其中,dataUsage 指明了模型所应用的数据子集,ConfusionMatrix 可以用于给出分类问题中正确预测和错误预测的概况,LiftData 提供了一种流行的预测模型质量显示方法。同时可以看到,模型预测结果的误差均值,误差绝对值均值等常用评价准则也包含在内。
针对聚类型模型的质量评价,PMML 标准提供如下所示的功能:
清单 8. 聚类模型质量评价
<xs:element name="ClusteringModelQuality">
<xs:complexType>
<xs:attribute name="dataName" type="xs:string" use="optional"/>
<xs:attribute name="SSE" type="NUMBER" use="optional"/>
<xs:attribute name="SSB" type="NUMBER" use="optional"/>
</xs:complexType>
</xs:element> |
其中,dataName 指明了模型质量信息的来源数据集,SSE 和 SSB 分别给出了聚类模型的类内和类间的欧式距离度量。
3. PMML 应用于预测分析
3.1 数据建模的应用实例
本节将结合数据挖掘任务的业务流程来具体介绍 PMML 标准的各部分。
现有用户所搜集的某公司员工的个人及工作相关信息,现通过对数据的定义、预处理、建模和评价等步骤,来演示 PMML 标准是如何规范数据挖掘任务流程的。本文所使用产品为 IBM SPSS Modeler 14.1,该产品通过一个可视化的界面,使用数据流的形式清晰地表示出数据挖掘的过程。数据挖掘的数据流如图 1 所示:
图 1. 数据挖掘的数据流表示
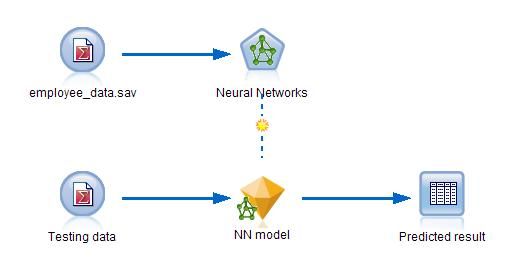
下面我们将按照该数据挖掘任务所对应的 PMML 文件来逐步介绍。
清单 9 包含了该文件的所支持的 PMML 标准的版本信息,生成此文件的产品名称,版本信息,以及模型生成时间。
清单 9. 头信息示例
<?xml version="1.0"?>
<PMML version="4.0">
<Header copyright="(C) Copyright IBM Corp. 1994, 2011">
<Application name="IBM SPSS Modeler" version="14.1.0"/>
<Timestamp>Thu Jun 09 14:22:24 2011</Timestamp>
</Header> |
首先需要依照原始数据定义数据字典,这往往需要借助于用户预定义的数据信息,或通过数据扫描得到所需的信息。数据字典中定义了原始数据中所包含的所有数据变量,以及它们的数据类型(分为字符型,整型,浮点型,布尔型,日期和时间等类型),操作类型(分为连续型,分类型和有序分类型),显示名称等。本例的数据字典请参考清单 10。
清单 10. 数据字典
<DataDictionary numberOfFields="9">
<DataField dataType="string" displayName="Gender" name="GENDER" optype="categorical">
<Value value="f"/>
<Value value="m"/>
</DataField>
<DataField dataType="dateDaysSince[1970]" displayName="Date of Birth" name="BDATE"
optype="continuous"/>
<DataField dataType="double" displayName="Current Salary" name="SALARY"
optype="continuous">
<Value displayValue="SALARY" property="missing" value="0"/>
</DataField>
<DataField dataType="double" displayName="Employment Category" name="JOBCAT"
optype="ordinal">
<Value value="1"/>
<Value value="2"/>
<Value value="3"/>
<Value displayValue="JOBCAT" property="missing" value="0"/>
</DataField> |
在清单 10 中,GENDER 是一个字符型的分类型变量,它包含 f 和 m 俩个值。而 BDATE 是一种日期型变量,它记录了从 1970 年 1 月 1 日起至某一日期的天数,如 1970 年 1 月 2 日则记为 1,1970 年 2 月 1 日则记为 31。double 型的数据变量 SALARY 和 JOBCAT 分别为连续型和分类型变量,它们都采用了 property="missing"标记出了所含的缺失值。
由于在数据中包含若干的连续型变量,而它们的取值范围会有较大的差异。比如员工的年薪值与其家庭所拥有的车辆数必定存在很大的差值。所以为了确保年薪这类具有较大取值范围的变量和拥有车辆数这类具有较小取值范围变量能够在建模的过程中被平等对待,就需要将连续型数据进行规范化。这种行为体现在 PMML 标准中就是数据转换。清单 11 列出了对变量 SALBEGIN 进行的数据转换操作。
清单 11. 数据转换用于连续型数据标准化
<DerivedField dataType="double" name="SALBEGINNorm" optype="continuous">
<NormContinuous field="SALBEGIN">
<LinearNorm norm="-0.999137918829862" orig="9000"/>
<LinearNorm norm="7.82547264192418" orig="79980"/>
</NormContinuous>
</DerivedField> |
产品中所使用的数据转换是利用原始数据的均值和方差的标准化操作。清单 11 中将其表示为线性映射的关系。
同时属于数据转换操作的还有针对分类型数据的编码。这是由于神经网络模型仅能支持数值变量的输入。所以有如清单 12 所示的编码过程的数据转换。
清单 12. 数据转换用于分类型数据编码操作
<DerivedField dataType="double" name="JOBCATValue0" optype="ordinal">
<NormDiscrete field="JOBCAT" value="1"/>
</DerivedField>
<DerivedField dataType="double" name="JOBCATValue1" optype="ordinal">
<NormDiscrete field="JOBCAT" value="2"/>
</DerivedField>
<DerivedField dataType="double" name="JOBCATValue2" optype="ordinal">
<NormDiscrete field="JOBCAT" value="3"/>
</DerivedField> |
从清单 12 中可以看出,JOBCAT 被按照取值的不同编码成三个数据变量。在后继的建模中,JOBCAT 将会被编码所得的 3 个变量所替代。
完成了数据的定义和预处理转换之后,就可以进行建模和模型表示了。本例中采用神经网络模型,利用员工的相关信息来分析预测其工作类型。首先定义模型的输入和输出项。详情请见清单 13。
清单 13. 模型参数定义
<NeuralNetwork activationFunction="radialBasis" functionName="classification">
<MiningSchema>
<MiningField name="EDUC" usageType="active"/>
<MiningField name="GENDER" usageType="active"/>
<MiningField name="JOBTIME" usageType="active"/>
<MiningField name="MINORITY" usageType="active"/>
<MiningField name="PREVEXP" usageType="active"/>
<MiningField name="SALARY" usageType="active"/>
<MiningField name="SALBEGIN" usageType="active"/>
<MiningField name="JOBCAT" usageType="predicted"/>
</MiningSchema> |
由于本例中所预测的是一个分类型变量 JOBCAT,所以例中模型为分类模型,使用 functionName="classification" 来标记。MiningSchema 包含模型的输入输出定义。
除此之外,PMML 文件中还包含了大量的模型结构信息。从清单 14 中可以看出,PMML 文件包含了神经网络模型的输入层,中间层以及输出层的结构和权值。由于我们这里主要介绍的是数据挖掘过程同 PMML 标准的结合,所以模型所特有的结构信息,就不在此做展开介绍。
清单 14. 模型结构定义
<NeuralNetwork activationFunction="radialBasis" algorithmName="RBF"
functionName="classification">
...
<NeuralInputs>
<NeuralInput id="0">
<DerivedField dataType="double" optype="continuous">
<FieldRef field="BDATENorm"/>
</DerivedField>
</NeuralInput>
<NeuralInput id="1">
<DerivedField dataType="double" optype="continuous">
<FieldRef field="EDUCValue0"/>
</DerivedField>
</NeuralInput>
...
<NeuralInput id="18">
<DerivedField dataType="double" optype="continuous">
<FieldRef field="SALBEGINNorm"/>
</DerivedField>
</NeuralInput>
</NeuralInputs>
<NeuralLayer activationFunction="radialBasis" normalizationMethod="simplemax"
numberOfNeurons="10">
<Neuron id="19" width="0.365222071288571">
<Con from="0" weight="0.971731403565473"/>
<Con from="1" weight="0"/>
...
<Con from="18" weight="-0.624873248444845"/>
</Neuron>
...
</NeuralLayer>
<NeuralLayer activationFunction="identity" numberOfNeurons="3">
<Neuron id="29">
<Con from="19" weight="0.994338072659398"/>
...
<Con from="28" weight="1.06547416303621"/>
</Neuron>
...
</NeuralLayer>
<NeuralOutputs>
<NeuralOutput outputNeuron="29">
<DerivedField dataType="double" optype="continuous">
<FieldRef field="JOBCATValue0"/>
</DerivedField>
</NeuralOutput>
<NeuralOutput outputNeuron="30">
<DerivedField dataType="double" optype="continuous">
<FieldRef field="JOBCATValue1"/>
</DerivedField>
</NeuralOutput>
<NeuralOutput outputNeuron="31">
<DerivedField dataType="double" optype="continuous">
<FieldRef field="JOBCATValue2"/>
</DerivedField>
</NeuralOutput>
</NeuralOutputs>
</NeuralNetwork> |
3.2 使用 PMML 进行预测分析
数据挖掘模型的一个很重要的应用就是预测。由于 PMML 是产品和平台无关的,所以使用某一产品获取到数据挖掘模型,可以将其部署到其他支持 PMML 标准的数据挖掘产品或平台中,从而利用具有相同数据字典的数据进行预测分析。利用这一特性,可以构建基于 PMML 标准的可分离的数据挖掘模型构造模块和预测模块。其框架如图 2 所示:
图 2. 数据挖掘建模与预测框架
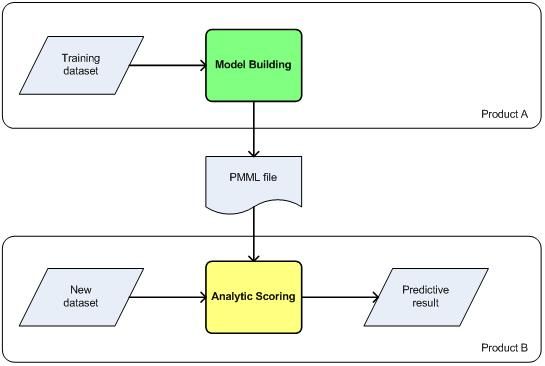
图 2 描述了一个基于 PMML 标准的数据挖掘建模与预测框架。其中建模和预测模块能够分别输出和解析 PMML 文件,而且这个两个模块可以位于不同产品或不同平台中。而针对预测模块又可以分为面向数据流的预测和面向数据库的预测。
面向数据的预测模块需要 PMML 解析器,能够从 PMML 文件中解析出第二章中介绍的数据挖掘各步骤中所需的信息。通过数据字典的定义,对待预测数据流进行所定义的数据转换,应用模型所对应的预测算法,获取到预测结果。
而面向数据库的预测,从 PMML 文件中解析出所需的数据字典,数据转换和模型信息后,对应的模型预测算法将会被表达为数据库所能支持的 SQL 语句等,利用数据库的运算功能完成预测。
4. 基于 PMML 的可视化
数据可视化是通过直观的图形方法,将从数据中抽取出来的感兴趣模式信息进行视觉展示,扩展了对数据的表达和理解能力,从而能够更加深入的剖析数据,揭示数据中的内在本质以及规律。PMML 标准涵盖了数据、转换处理和模型的摘要信息,是理想的可视化数据来源。本章就针对基于 PMML 标准的可视化进行介绍、分类和举例。
同样利用数据挖掘任务的不同阶段,可以将给予 PMML 的可视化分为以下几类:
- 数据可视化
- 模型可视化
- 验证信息可视化
4.1 数据可视化
数据的可视化是指针对数据集信息的可视化表达。
数据挖掘模型中,众多数据变量对预测的重要性是商业应用中一个很重要的度量和参考信息。一个数据变量的重要性值,importance,记录在 MiningSchema 中,可作为可视化的数据源。清单 15 给出了 3.1 中所给实例的 PMML 文件中的数据变量重要性信息。
清单 15. 数据变量的重要性
<MiningSchema>
<MiningField importance="0.0414229101626078" name="BDATE"/>
<MiningField importance="0.0516963786504862" name="EDUC"/>
<MiningField importance="0.0280299186962596" name="GENDER"/>
<MiningField importance="0.0220071243554219" name="JOBTIME"/>
<MiningField importance="0.0287157228769955" name="MINORITY"/>
<MiningField importance="0.157114511185484" name="PREVEXP"/>
<MiningField importance="0.339952578793498" name="SALARY"/>
<MiningField importance="0.331060855279247" name="SALBEGIN"/>
<MiningField name="JOBCAT" usageType="predicted"/>
</MiningSchema> |
可使用条状图或饼图来显示变量的重要性。图 3 是一个条状图示例。
图 3. 变量重要性
从图 3 可以看出,对员工工作类型影响最大的变量是员工的当前工资值和起始工资值,之后依次是工作经验,教育水平等等。重要性的图形展示可以帮助用户直观地理解数据,为特征筛选等操作提供参考。
4.2 模型可视化
不同的数据挖掘模型,都有其自身的结构特点。借助 PMML 标准中模型的结构化信息,可以将抽象模型形象的表示出来,便于展示数据挖掘所提取出的模式信息。
神经网络模型具有层次的网状结构,清单 14 给出了一个神经网络模型的具体 PMML 表示。其中定义了神经网络输入层,中间层和输出层,及其各层对应的权重参数。这些信息就可以直观展示为类似于图 4 中的模型结构示例。
图 4. 神经网络模型数据结构示意图
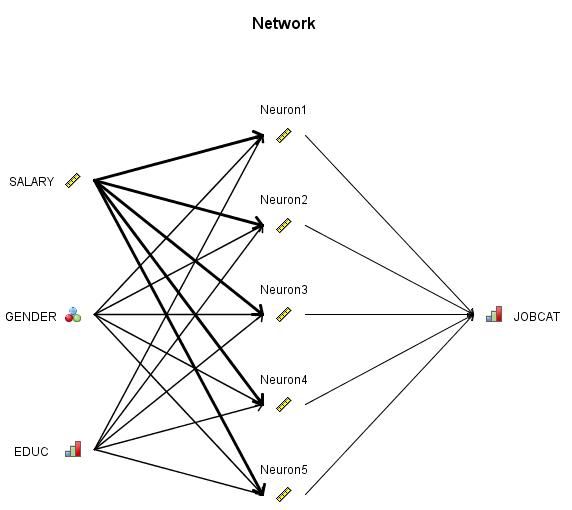
图 4 描述了一个三层神经网络的结构。其中有包括 3 个输入项的输入层,1 个输出项的输出层,以及 5 个神经元的中间层。依据 3.1 节及清单 12 中的介绍,分类型变量在构建神经网络模型前要进行编码操作,从而图 4 的结构可以进一步表达成编码之后的神经网络结构,如图 5 所示:
图 5. 神经网络模型结点结构示意图
图 5 描述了一个三层神经网络的实际运算结构图。对比图 4,在具有相同层数之外,输入和输出层给出了实际的结点个数,而结点之间的连线通过色彩的变化显示出了权系数的大小。实际的神经网络运算中,待预测数据首先编码输入到输入层中各结点,之后按照图示连线的箭头方向和强弱,进行神经传导和激活运算,最终通过输出层所获得的信息得到最终预测结果。
同样的,树模型(Tree model)也具有非常强的层次结构信息。同样使用上例中的数据构建树模型,得到 PMML 表示其结构如下:
清单 16. 模型结构表示
<TreeModel algorithmName="jobcat" functionName="classification">
...
<Node id="0" recordCount="346" score="1">
<True/>
<Node id="1" recordCount="289" score="1">
<SimplePredicate field="SALBEGIN" operator="lessOrEqual" value="20775"/>
<Node id="3" recordCount="261" score="1">
<SimplePredicate field="PREVEXP" operator="lessOrEqual" value="278"/>
</Node>
<Node id="4" recordCount="28" score="1">
<SimplePredicate field="PREVEXP" operator="greaterThan" value="278"/>
<Node id="9" recordCount="16" score="1">
<SimplePredicate field="SALARY" operator="lessOrEqual" value="28350"/>
</Node>
<Node id="10" recordCount="12" score="2">
<SimplePredicate field="SALARY" operator="greaterThan" value="28350"/>
</Node>
</Node>
</Node>
<Node id="2" recordCount="57" score="3">
<SimplePredicate field="SALBEGIN" operator="greaterThan" value="20775"/>
</Node>
</Node>
</TreeModel> |
其结构可以以一棵树的生长形式来形象的表示,如图 6:
图 6. 树模型结构示意图
从图 6 可以看出,建模过程中发现采用变量 SALBEGIN 对整个数据集进行分类是最具代表性的,所以被选为树的根节点,并且以 20775.00 为分界点可将整个数据集分为两个子集 Node 1 和 Node 2。Node 2 数据集中,大部分样本都属于第三类。而 Node 1 中的数据又可按 PREVEXP 的值以 278 为分界点分为两支。后继的生长过程类推。
这样的结构展示,清晰的描述了树模型建模过程所提取出的数据模式信息,使用户能形象的了解所用的数据。
4.3 验证信息可视化
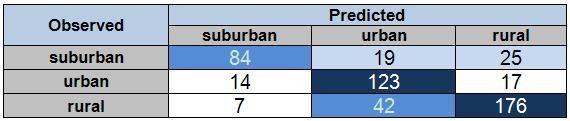
当所需预测的数据变量是分类型变量时,confusion matrix 可以用来展示其分类准确度。
现有一个用来预测居民所属地区的分类模型,建模后对训练样本集进行预测可得到其 confusion matrix 如图 7 所示:
图 7. Confusion matrix 示例
清单 17 是其在 PMML 中的片段:
清单 17. Confusion matrix 片段
...
<ConfusionMatrix>
<ClassLabels>
<Array type="string" n="3">suburban urban rural</Array>
</ClassLabels>
<Matrix>
<Array type="int" n="3"> 84 19 25</Array>
<Array type="int" n="3"> 14 123 17</Array>
<Array type="int" n="3"> 7 42 176</Array>
</Matrix>
</ConfusionMatrix>
... |
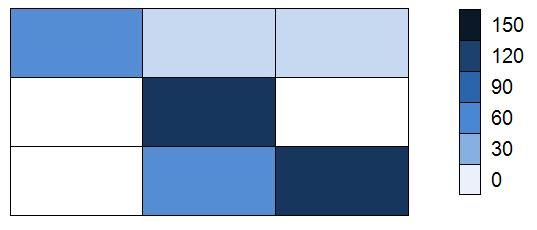
从 Confusion matrix 中可以看出,84 名 suburban 居民被正确的预测为 suburban,而 42 名 rural 名居民被错误的预测为 urban。对角线上的元素是正确预测的记录,而非对角线上的元素都是错误的预测结果。所以还可以通过热图为用户提供更加直观的展示,如图 8 所示。
图 8. 热图示例
以上探讨了有关 PMML 的数据可视化、模型可视化以及验证信息的可视化,并给出了相应的示例说明。PMML 标准所包含的信息纷繁复杂,支持的模型种类也多种多样并在不断的丰富中,本章所讨论的内容仅是其冰山一角,希望能起到些许的借鉴意义。
5. 总结与展望
PMML 是一种平台无关的统计和数据挖掘模型表示标准。PMML 标准通过对商业数据挖掘任务各部分的标准化定义,提供了统计和数据挖掘模型的共享基础和有效存储方式,使得在某一产品或平台中的数据挖掘模型能够被部署到其他支持 PMML 标准的产品或平台上。同时其使用 XML 格式,易于编辑和检查。但是 PMML 标准也有其局限性,它未能将模型与数据真正实现分离,而业内通用程度有待进一步发掘。伴随着数据挖掘行业的快速发展,有新的功能和需求不断被提出,比如最近邻模型和时间序列模型,这就需要 PMML 标准能够及时的扩展新的模型和诊断方法。我们也期待具有更强功能的 PMML 标准的推出,及其在数据挖掘领域中更加广泛的使用。
参考资料
学习
- XML 新手入门 获得学习 XML 所需的资源。
- developerWorks XML 专区:在 XML 专区获取提高您的专业技能所需的资源。查看 XML 技术库,获得广泛的技术文章和技巧、教程、标准和 IBM 红皮书。
- IBM XML 认证:了解如何才能成为一名 IBM 认证的 XML 和相关技术的开发人员。
- developerWorks 技术活动 和 网络广播:随时关注技术的最新进展。
- developerWorks 播客:收听针对软件开发人员的有趣访谈和讨论。
- developerWorks 按需演示:观看演示,包括面向初学者的产品安装和设置演示,以及为经验丰富的开发人员提供的高级功能。
获得产品和技术
- IBM 产品评估试用版:下载或 探索 IBM SOA Sandbox 中的在线试用软件,并尝试使用来自 DB2®、Lotus®、Rational®、Tivoli® 和 WebSphere® 的应用程序开发工具和中间件产品。
讨论
- 参与论坛讨论。
- XML 专区讨论论坛:参与任何一个 XML 相关讨论。
- developerWorks 社区:查看开发人员推动的博客、论坛、组和 wikis,并与其他 developerWorks 用户交流。
关于作者
许晶,Functional Designer,于 2007 年加入 IBM SPSS Advanced Analytics 团队,从事统计与数据挖掘产品的开发。