solr入门之搜索建议的拼音转换工具
上篇博客中我们确定了搜索建议的具体方案,该方案中涉及到一个将汉字转换为拼音的问题.这里我们主要讲解这个问题.使用pinyin4j来完成.
2. 下载解压后的目录结构及说明如下
- doc : pinyin4j的api文档
- lib : pinyin4j的jar包
- src : pinyin4j的源代码
- CHANGELOG.txt : pinyin4j的版本更新日志
- COPYING.txt : LICENSE说明
- README.txt : pinyin4j的概要介绍
3. 源码解析
net/sourceforge/pinyin4j
ChineseToPinyinResource:读取/pinyindb/unicode_to_hanyu_pinyin.txt
GwoyeuRomatzyhResource:读取/pinyindb/pinyin_gwoeu_mapping.xml
GwoyeuRomatzyhTranslator:汉语拼音转换为Gwoyeu拼音
PinyinRomanizationResource:读取/pinyindb/pinyin_mapping.xml
PinyinRomanizationType:定义汉语拼音的六种类型 (pinyin4j支持将汉字转化成六种拼音表示法。其对应关系是:汉语拼音-Hanyu Pinyin,通用拼音-Tongyong Pinyin, 威妥玛拼音(威玛拼法)-Wade-Giles Pinyin, 注音符号第二式-MPSII Pinyin, 耶鲁拼法-Yale Pinyin和国语罗马字-Gwoyeu Romatzyh)
PinyinRomanizationTranslator:拼音转换,convertRomanizationSystem(源拼音字符串,源拼音类型,目标拼音类型)
PinyinFormatter:汉语拼音格式化(如:根据提供的格式格式化拼音字符串;注音标等方法)
PinyinHelper:音标格式化方法类(六种拼音类型的获取方法等)
ResourceHelper:从classpath路径下读取文件流BufferedInputStream
TextHelper:获取汉语拼音中拼音或音调数字
extractToneNumber返回音调数字,如输入:luan4 返回:4
extractPinyinString返回汉语拼音前的拼音,如输入:luan4 返回:luan
/format
HanyuPinyinCaseType:定义汉语拼音大小写类型(控制生成的拼音是以大写方式显示还是以小写方式显示)
- LOWERCASE :guó
- UPPERCASE :GUÓ
HanyuPinyinToneType:定义汉语拼音声调类型
- WITH_TONE_NUMBER(以数字代替声调) : zhong1 zhong4
- WITHOUT_TONE (无声调) : zhong zhong
- WITH_TONE_MARK (有声调) : zhōng zhòng
HanyuPinyinVCharType:定义汉语拼音字符u的类型(碰到unicode 的ü 、v 和 u时的显示方式)
- WITH_U_AND_COLON : lu:3
- WITH_V : lv3
- WITH_U_UNICODE : lü3
HanyuPinyinOutputFormat:拼音格式类型构造类
/exception 异常类
BadHanyuPinyinOutputFormatCombination:拼音格式化组合错误异常,如一下组合:
LOWERCASE-WITH_V-WITH_TONE_MARK LOWERCASE-WITH_U_UNICODE-WITH_TONE_MARK
UPPERCASE-WITH_V-WITH_TONE_MARK UPPERCASE-WITH_U_UNICODE-WITH_TONE_MARK
其主要思路:
1)先通过汉字字符的unicode编码从unicode_to_hanyu_pinyin.txt找到对应的带声调数字的拼音
2)根据给定的输出格式化要求对该带声调的数字拼音进行格式化处理
3)在各个拼音之间可以相互转换:
根据pinyin_mapping.xml可以找到汉语拼音对应其他四种格式,如:
<item>
<Hanyu>a</Hanyu>
<Wade>a</Wade>
<MPSII>a</MPSII>
<Yale>a</Yale>
<Tongyong>a</Tongyong>
</item>
根据pinin_gwoyeu_mapping.xml可以找出汉语拼音与Gwoyeu不同声调对应的格式,如:
<item>
<Hanyu>a</Hanyu>
<Gwoyeu_I>a</Gwoyeu_I>
<Gwoyeu_II>ar</Gwoyeu_II>
<Gwoyeu_III>aa</Gwoyeu_III>
<Gwoyeu_IV>ah</Gwoyeu_IV>
<Gwoyeu_V>.a</Gwoyeu_V>
</item>
4. 字符串转化成拼音Java代码示例
public class Pinyin4jUtil {
/**
* 汉字转换位汉语拼音首字母,英文字符不变,特殊字符丢失 支持多音字,生成方式如(长沙市长:cssc,zssz,zssc,cssz)
*
* 这个方法不太符合我创建索引的要求---我要的是数组--自己重建一个
* @param chines
* 汉字
* @return 拼音 字符串
*/
public static String converterToFirstSpell(String chines) {
return parseTheChineseByObject(discountTheChinese(MinMethod(chines).toString()));
}
/**
*
* @描述:返回类型调整为数组
* @param chines
* @return
* @return String[]
* @exception
* @createTime:2016年3月22日
* @author: songqinghu
*/
public static Set<String> converterToFirstSpellToSet(String chines){
return parseTheChineseByObjectToSet(discountTheChinese(MinMethod(chines).toString()));
}
/**
*
* @描述:获取首字母方法抽取
* @param chines
* @return
* @return StringBuffer
* @exception
* @createTime:2016年3月22日
* @author: songqinghu
*/
public static StringBuffer MinMethod(String chines){
StringBuffer pinyinName = new StringBuffer();
char[] nameChar = chines.toCharArray();
HanyuPinyinOutputFormat defaultFormat = new HanyuPinyinOutputFormat();
defaultFormat.setCaseType(HanyuPinyinCaseType.LOWERCASE);
defaultFormat.setToneType(HanyuPinyinToneType.WITHOUT_TONE);
for (int i = 0; i < nameChar.length; i++) {
if (nameChar[i] > 128) { //char中1-127对应特殊字符和数字,字母
try {
// 取得当前汉字的所有全拼
String[] strs = PinyinHelper.toHanyuPinyinStringArray(
nameChar[i], defaultFormat);
if (strs != null) {
for (int j = 0; j < strs.length; j++) {
// 取首字母
pinyinName.append(strs[j].charAt(0));
if (j != strs.length - 1) {
pinyinName.append(",");
}
}
}
// else {
// pinyinName.append(nameChar[i]);
// }
} catch (BadHanyuPinyinOutputFormatCombination e) {
e.printStackTrace();
}
} else {
pinyinName.append(nameChar[i]);
}
pinyinName.append(" ");
}
return pinyinName;
}
/**
* 汉字转换位汉语全拼,英文字符不变,特殊字符丢失
* 支持多音字,生成方式如(重当参:zhongdangcen,zhongdangcan,chongdangcen
* ,chongdangshen,zhongdangshen,chongdangcan)
* 不符合 我的要求---重新写一个返回值为Set<String>类型
* @param chines
* 汉字
* @return 拼音
*/
public static String converterToSpell(String chines) {
// return pinyinName.toString();
return parseTheChineseByObject(discountTheChinese(midConoverterToSpell(chines).toString()));
}
/**
*
* @描述:返回值为set
* @param chines
* @return
* @return Set<String>
* @exception
* @createTime:2016年3月22日
* @author: songqinghu
*/
public static Set<String> converterToSpellToSet(String chines){
return parseTheChineseByObjectToSet(discountTheChinese(midConoverterToSpell(chines).toString()));
}
/**
* @描述:方法抽取
* @param chines
* @return
* @return StringBuffer
* @exception
* @createTime:2016年3月22日
* @author: songqinghu
*/
private static StringBuffer midConoverterToSpell(String chines){
StringBuffer pinyinName = new StringBuffer();
char[] nameChar = chines.toCharArray();
HanyuPinyinOutputFormat defaultFormat = new HanyuPinyinOutputFormat();
defaultFormat.setCaseType(HanyuPinyinCaseType.LOWERCASE);
defaultFormat.setToneType(HanyuPinyinToneType.WITHOUT_TONE);
for (int i = 0; i < nameChar.length; i++) {
if (nameChar[i] > 128) {
try {
// 取得当前汉字的所有全拼
String[] strs = PinyinHelper.toHanyuPinyinStringArray(
nameChar[i], defaultFormat);
if (strs != null) {
for (int j = 0; j < strs.length; j++) {
pinyinName.append(strs[j]);
if (j != strs.length - 1) {
pinyinName.append(",");
}
}
}
} catch (BadHanyuPinyinOutputFormatCombination e) {
e.printStackTrace();
}
} else {
pinyinName.append(nameChar[i]);
}
pinyinName.append(" ");
}
return pinyinName;
}
/**
* 去除多音字重复数据
*
* @param theStr
* @return
*/
private static List<Map<String, Integer>> discountTheChinese(String theStr) {
// 去除重复拼音后的拼音列表
List<Map<String, Integer>> mapList = new ArrayList<Map<String, Integer>>();
// 用于处理每个字的多音字,去掉重复
Map<String, Integer> onlyOne = null;
String[] firsts = theStr.split(" ");
// 读出每个汉字的拼音
for (String str : firsts) {
onlyOne = new Hashtable<String, Integer>();
String[] china = str.split(",");
// 多音字处理
for (String s : china) {
Integer count = onlyOne.get(s);
if (count == null) {
onlyOne.put(s, new Integer(1));
} else {
onlyOne.remove(s);
count++;
onlyOne.put(s, count);
}
}
mapList.add(onlyOne);
}
return mapList;
}
/**
* 解析并组合拼音,对象合并方案(推荐使用)
*
* @return
*/
private static String parseTheChineseByObject(
List<Map<String, Integer>> list) {
Map<String, Integer> first = MinparseTheChineseByObject(list);
String returnStr = "";
if (first != null) {
// 遍历取出组合字符串
for (String str : first.keySet()) {
returnStr += (str + ",");
}
}
if (returnStr.length() > 0) {
returnStr = returnStr.substring(0, returnStr.length() - 1);
}
return returnStr;
}
/**
* 解析并组合拼音,对象合并方案(推荐使用)---返回set<String>
*
* @return
*/
private static Set<String> parseTheChineseByObjectToSet(
List<Map<String, Integer>> list) {
Map<String, Integer> first = MinparseTheChineseByObject(list);
Set<String> result = null;
if (first != null && first.keySet().size()>0) {
// 遍历取出组合字符串
result = first.keySet();
}
return result;
}
/**
*
* @描述:方法抽取
* @param list
* @return
* @return Map<String,Integer>
* @exception
* @createTime:2016年3月22日
* @author: songqinghu
*/
private static Map<String,Integer> MinparseTheChineseByObject(
List<Map<String, Integer>> list){
Map<String, Integer> first = null; // 用于统计每一次,集合组合数据
// 遍历每一组集合
for (int i = 0; i < list.size(); i++) {
// 每一组集合与上一次组合的Map
Map<String, Integer> temp = new Hashtable<String, Integer>();
// 第一次循环,first为空
if (first != null) {
// 取出上次组合与此次集合的字符,并保存
for (String s : first.keySet()) {
for (String s1 : list.get(i).keySet()) {
String str = s + s1;
temp.put(str, 1);
}
}
// 清理上一次组合数据
if (temp != null && temp.size() > 0) {
first.clear();
}
} else {
for (String s : list.get(i).keySet()) {
String str = s;
temp.put(str, 1);
}
}
// 保存组合数据以便下次循环使用
if (temp != null && temp.size() > 0) {
first = temp;
}
}
return first;
}
}
方法Demo
public static void addDocumentAndPY() throws SolrServerException, Exception{
SolrClient solrClient = new HttpSolrClient("http://localhost:8983/solr/group");
Collection<SolrInputDocument> docs = new ArrayList<SolrInputDocument>();
List<String> words = new ArrayList<String>();
words.add("测试");
int i = 0;
for (String word : words) {
SolrInputDocument doc = new SolrInputDocument();
doc.addField("groupId", i+"");
doc.addField("categoryName", word);
//需要对工具类进行改写--返回的是多值的时候需要进行数组的切分 确保可以使用 xxx* 进行匹配
Set<String> lengths = Pinyin4jUtil.converterToSpellToSet(word);
Set<String> shorts = Pinyin4jUtil.converterToFirstSpellToSet(word);
for (String py : shorts) {
doc.addField("pinyin", py);
}
for (String py : lengths) {
doc.addField("pinyin", py);
}
i++;
docs.add(doc);
System.out.println(word + " length : " + lengths + " shorts: "+ shorts);
}
solrClient.add(docs);
System.out.println("索引建立结束");
}
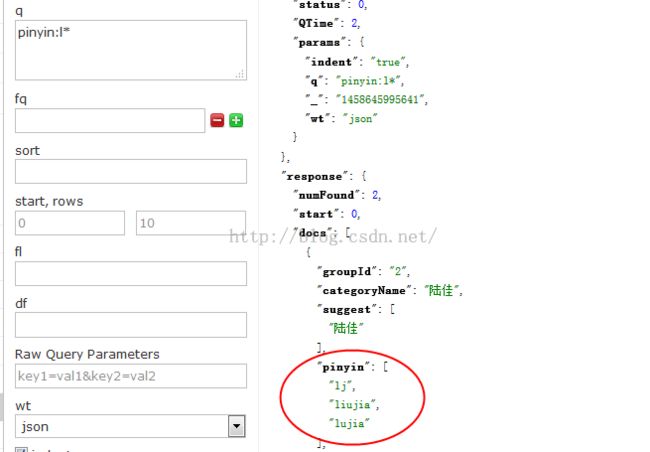
最后截图留念: