ListView的优化
首先来了解一下ListView的工作原理
ListView 针对每个item,要求 adapter “返回一个视图” (getView),也就是说ListView在开始绘制的时候,系统首先调用getCount()函数,根据他的返回值得到ListView的长度,然后根据这个长度,调用getView()一行一行的绘制ListView的每一项。如果你的getCount()返回值是0的话,列表一行都不会显示,如果返回1,就只显示一行。返回几则显示几行。如果我们有几千几万甚至更多的item要显示怎么办?为每个Item创建一个新的View?不可能!!!实际上Android早已经缓存了这些视图,大家可以看下下面这个截图来理解下,这个图是解释ListView工作原理的最经典的图了大家可以收藏下,不懂的时候拿来看看,加深理解,其实Android中有个叫做Recycler的构件,顺带列举下与Recycler相关的已经由Google做过N多优化过的东东比如:AbsListView.RecyclerListener、ViewDebug.RecyclerTraceType等等,要了解的朋友自己查下,不难理解,下图是ListView加载数据的工作原理(原理图看不清楚的点击后看大图):
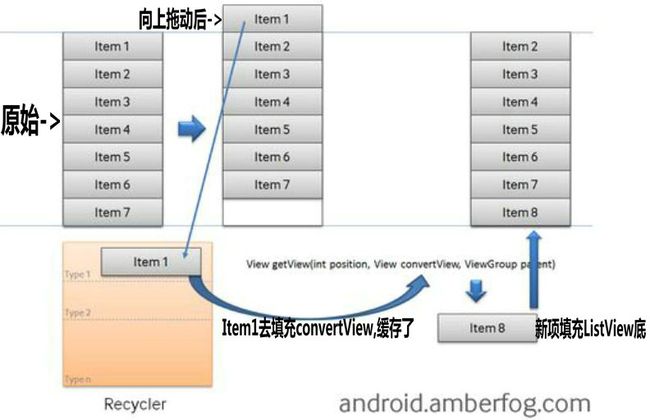
1、如果你有几千几万甚至更多的选项(item)时,其中只有可见的项目存在内存(内存内存哦,说的优化就是说在内存中的优化!!!)中,其他的在Recycler中
2、ListView先请求一个type1视图(getView)然后请求其他可见的项目。convertView在getView中是空(null)的
3、当item1滚出屏幕,并且一个新的项目从屏幕低端上来时,ListView再请求一个type1视图。convertView此时不是空值了,它的值是item1。你只需设定新的数据然后返回convertView,不必重新创建一个视图
一 复用convertView, 使用ViewHolder减少findViewById的次数
1、优化一:复用convertView
Android系统本身为我们考虑了ListView的优化问题,在复写的Adapter的类中,比较重要的两个方法是getCount()和getView()。界面上有多少个条显示,就会调用多少次的getView()方法;因此如果在每次调用的时候,如果不进行优化,每次都会使用View.inflate(….)的方法,都要将xml文件解析,并显示到界面上,这是非常消耗资源的:因为有新的内容产生就会有旧的内容销毁,所以,可以复用旧的内容。
优化:
在getView()方法中,系统就为我们提供了一个复用view的历史缓存对象convertView,当显示第一屏的时候,每一个item都会新创建一个view对象,这些view都是可以被复用的;如果每次显示一个view都要创建一个,是非常耗费内存的;所以为了节约内存,可以在convertView不为null的时候,对其进行复用
public View getView(int position, View convertView, ViewGroup parent) {
if(convertView == null)
{
convertView = mInflater.inflate(R.layout.list_item, null);
}
ImageView img = (ImageView)convertView.findViewById(R.id.img);
TextView title = (TextView)convertView.findViewById(R.id.title);
TextView info = (TextView)ConvertView.findViewById(R.id.info);
img.setImageResource(R.drawable.ic_launcher);
title.setText("Hello");
info.setText("world");
return convertView;
}
2、优化二:缓存item条目的引用——ViewHolder
findViewById()这个方法是比较耗性能的操作,因为这个方法要找到指定的布局文件,进行不断地解析每个节点:从最顶端的节点进行一层一层的解析查询,找到后在一层一层的返回,如果在左边没找到,就会接着解析右边,并进行相应的查询,直到找到位置。因此可以对findViewById进行优化处理,需要注意的是:
》》》》特点:xml文件被解析的时候,只要被创建出来了,其孩子的id就不会改变了。根据这个特点,可以将孩子id存入到指定的集合中,每次就可以直接取出集合中对应的元素就可以了。
优化:
在创建view对象的时候,减少布局文件转化成view对象的次数;即在创建view对象的时候,把所有孩子全部找到,并把孩子的引用给存起来
①定义存储控件引用的类ViewHolder
这里的ViewHolder类需要不需要定义成static,根据实际情况而定,如果item不是很多的话,可以使用,这样在初始化的时候,只加载一次,可以稍微得到一些优化
不过,如果item过多的话,建议不要使用。因为static是Java中的一个关键字,当用它来修饰成员变量时,那么该变量就属于该类,而不是该类的实例。所以用static修饰的变量,它的生命周期是很长的,如果用它来引用一些资源耗费过多的实例(比如Context的情况最多),这时就要尽量避免使用了。
class ViewHolder{
//定义item中相应的控件
}
②创建自定义的类:ViewHolder holder = null;
③将子view添加到holder中:
在创建新的listView的时候,创建新的ViewHolder,把所有孩子全部找到,并把孩子的引用给存起来
通过view.setTag(holder)将引用设置到view中
源码:
protected Object mTag;--->mTag为成员变量
public void setTag(final Object tag) {
mTag = tag;
}
当convertView为空时,用setTag()方法为每个View绑定一个存放控件的ViewHolder对象。当convertView不为空,重复利用已经创建的view的时候,使用getTag()方法获取绑定的ViewHolder对象,这样就避免了findViewById对控件的层层查询,而是快速定位到控件。
完整的官方例子中convertView 也是避免inflating View。然后把对底下的控件引用存在ViewHolder里面,再用convertView.setTag(holder)把它放在view里,下次就可以用(ViewHolder) convertView.getTag()直接取了。
public Object getTag() {
return mTag;
}
④在复用listView中的条目的时候,通过view.getTag( )获取引用(需要强转)
//在外面先定义,ViewHolder静态类
static class ViewHolder
{
public ImageView img;
public TextView title;
public TextView info;
}
//然后重写getView
@Override
public View getView(int position, View convertView, ViewGroup parent) {
ViewHolder holder;
if(convertView == null)
{
holder = new ViewHolder();
convertView = mInflater.inflate(R.layout.list_item, null);
holder.img = (ImageView)convertView.findViewById(R.id.img);
holder.title = (TextView)convertView.findViewById(R.id.title);
holder.info = (TextView)convertView.findViewById(R.id.info);
convertView.setTag(holder);
}else
{
holder = (ViewHolder)convertView.getTag();
}
holder.img.setImageResource(R.drawable.ic_launcher);
holder.title.setText("Hello");
holder.info.setText("World");
}
return convertView;
}
二 ListView中数据的分批及分页加载:
需求:ListView有一万条数据,如何显示;如果将十万条数据加载到内存,很消耗内存
解决办法:
优化查询的数据:先获取几条数据显示到界面上
进行分批处理---优化了用户体验
进行分页处理---优化了内存空间
说明:
一般数据都是从数据库中获取的,实现分批(分页)加载数据,就需要在对应的DAO中有相应的分批(分页)获取数据的方法,如findPartDatas ()
1、准备数据:
在dao中添加分批加载数据的方法:findPartDatas ()
在适配数据的时候,先加载第一批的数据,需要加载第二批的时候,设置监听检测何时加载第二批
2、设置ListView的滚动监听器:setOnScrollListener(new OnScrollListener{….})
①、在监听器中有两个方法:滚动状态发生变化的方法(onScrollStateChanged)和listView被滚动时调用的方法(onScroll)
②、在滚动状态发生改变的方法中,有三种状态:
手指按下移动的状态: SCROLL_STATE_TOUCH_SCROLL: // 触摸滑动
惯性滚动(滑翔(flgin)状态): SCROLL_STATE_FLING: // 滑翔
静止状态: SCROLL_STATE_IDLE: // 静止
3、对不同的状态进行处理:
分批加载数据,只关心静止状态:关心最后一个可见的条目,如果最后一个可见条目就是数据适配器(集合)里的最后一个,此时可加载更多的数据。在每次加载的时候,计算出滚动的数量,当滚动的数量大于等于总数量的时候,可以提示用户无更多数据了。
三 复杂ListView的处理:(待进一步总结)
说明:
listView的界面显示是通过getCount和getView这两个方法来控制的
getCount:返回有多少个条目
getView:返回每个位置条目显示的内容
提供思路:
对于含有多个类型的item的优化处理:由于ListView只有一个Adapter的入口,可以定义一个总的Adapter入口,存放各种类型的Adapter
1、定义两个(或多个)集合
每个集合中存入的是对应不同类型的内容(这里为:用户程序(userAppinfos)和系统程序的集合(systemAppinfos))
2、在初始化数据(填充数据)中初始化两个集合
如,此处是在fillData方法中初始化
3、在数据适配器中,复写对应的方法
getCount():计算所有需要显示的条目个数,这里包括listView和textView
getView():对显示在不同位置的条目进行if处理
4、数据类型的判断
需要注意的是,在复用view的时候,需要对convertView进行类型判断,是因为这里含有各种不同类型的view,在view滚动显示的时候,对于不同类型的view不能复用,所有需要判断
四 ListView中图片的优化:详看OOM异常中图片的优化
1、处理图片的方式:
如果自定义Item中有涉及到图片等等的,一定要狠狠的处理图片,图片占的内存是ListView项中最恶心的,处理图片的方法大致有以下几种:
①、不要直接拿路径就去循环decodeFile();使用Option保存图片大小、不要加载图片到内存去
②、拿到的图片一定要经过边界压缩
③、在ListView中取图片时也不要直接拿个路径去取图片,而是以WeakReference(使用WeakReference代替强引用。
比如可以使用WeakReference mContextRef)、SoftReference、WeakHashMap等的来存储图片信息,是图片信息不是图片哦!
④、在getView中做图片转换时,产生的中间变量一定及时释放
2、异步加载图片基本思想:
1)、 先从内存缓存中获取图片显示(内存缓冲)
2)、获取不到的话从SD卡里获取(SD卡缓冲)
3)、都获取不到的话从网络下载图片并保存到SD卡同时加入内存并显示(视情况看是否要显示)
原理:
优化一:先从内存中加载,没有则开启线程从SD卡或网络中获取,这里注意从SD卡获取图片是放在子线程里执行的,否则快速滑屏的话会不够流畅。
优化二:与此同时,在adapter里有个busy变量,表示listview是否处于滑动状态,如果是滑动状态则仅从内存中获取图片,没有的话无需再开启线程去外存或网络获取图片。
优化三:ImageLoader里的线程使用了线程池,从而避免了过多线程频繁创建和销毁,有的童鞋每次总是new一个线程去执行这是非常不可取的,好一点的用的AsyncTask类,其实内部也是用到了线程池。在从网络获取图片时,先是将其保存到sd卡,然后再加载到内存,这么做的好处是在加载到内存时可以做个压缩处理,以减少图片所占内存。
Tips:这里可能出现图片乱跳(错位)的问题:
图片错位问题的本质源于我们的listview使用了缓存convertView,假设一种场景,一个listview一屏显示九个item,那么在拉出第十个item的时候,事实上该item是重复使用了第一个item,也就是说在第一个item从网络中下载图片并最终要显示的时候,其实该item已经不在当前显示区域内了,此时显示的后果将可能在第十个item上输出图像,这就导致了图片错位的问题。所以解决之道在于可见则显示,不可见则不显示。在ImageLoader里有个imageViews的map对象,就是用于保存当前显示区域图像对应的url集,在显示前判断处理一下即可。
3、内存缓冲机制:
首先限制内存图片缓冲的堆内存大小,每次有图片往缓存里加时判断是否超过限制大小,超过的话就从中取出最少使用的图片并将其移除。
当然这里如果不采用这种方式,换做软引用也是可行的,二者目的皆是最大程度的利用已存在于内存中的图片缓存,避免重复制造垃圾增加GC负担;OOM溢出往往皆因内存瞬时大量增加而垃圾回收不及时造成的。只不过二者区别在于LinkedHashMap里的图片缓存在没有移除出去之前是不会被GC回收的,而SoftReference里的图片缓存在没有其他引用保存时随时都会被GC回收。所以在使用LinkedHashMap这种LRU算法缓存更有利于图片的有效命中,当然二者配合使用的话效果更佳,即从LinkedHashMap里移除出的缓存放到SoftReference里,这就是内存的二级缓存。
本例采用的是LRU算法,先看看MemoryCache的实现
public class MemoryCache {
private static final String TAG = "MemoryCache";
// 放入缓存时是个同步操作
// LinkedHashMap构造方法的最后一个参数true代表这个map里的元素将按照最近使用次数由少到多排列,即LRU
// 这样的好处是如果要将缓存中的元素替换,则先遍历出最近最少使用的元素来替换以提高效率
private Map<String, Bitmap> cache = Collections
.synchronizedMap(new LinkedHashMap<String, Bitmap>(10, 1.5f, true));
// 缓存中图片所占用的字节,初始0,将通过此变量严格控制缓存所占用的堆内存
private long size = 0;// current allocated size
// 缓存只能占用的最大堆内存
private long limit = 1000000;// max memory in bytes
public MemoryCache() {
// use 25% of available heap size
setLimit(Runtime.getRuntime().maxMemory() / 10);
}
public void setLimit(long new_limit) {
limit = new_limit;
Log.i(TAG, "MemoryCache will use up to " + limit / 1024. / 1024. + "MB");
}
public Bitmap get(String id) {
try {
if (!cache.containsKey(id))
return null;
return cache.get(id);
} catch (NullPointerException ex) {
return null;
}
}
public void put(String id, Bitmap bitmap) {
try {
if (cache.containsKey(id))
size -= getSizeInBytes(cache.get(id));
cache.put(id, bitmap);
size += getSizeInBytes(bitmap);
checkSize();
} catch (Throwable th) {
th.printStackTrace();
}
}
/**
* 严格控制堆内存,如果超过将首先替换最近最少使用的那个图片缓存
*
*/
private void checkSize() {
Log.i(TAG, "cache size=" + size + " length=" + cache.size());
if (size > limit) {
// 先遍历最近最少使用的元素
Iterator<Entry<String, Bitmap>> iter = cache.entrySet().iterator();
while (iter.hasNext()) {
Entry<String, Bitmap> entry = iter.next();
size -= getSizeInBytes(entry.getValue());
iter.remove();
if (size <= limit)
break;
}
Log.i(TAG, "Clean cache. New size " + cache.size());
}
}
public void clear() {
cache.clear();
}
/**
* 图片占用的内存
*<ahref="\"http://www.eoeandroid.com/home.php?mod=space&uid=2768922\"" target="\"_blank\"">@Param</a> bitmap
* @return
*/
long getSizeInBytes(Bitmap bitmap) {
if (bitmap == null)
return 0;
return bitmap.getRowBytes() * bitmap.getHeight();
}
}
五 ListView的其他优化:
1、尽量避免在BaseAdapter中使用static 来定义全局静态变量:
static是Java中的一个关键字,当用它来修饰成员变量时,那么该变量就属于该类,而不是该类的实例。所以用static修饰的变量,它的生命周期是很长的,如果用它来引用一些资源耗费过多的实例(比如Context的情况最多),这时就要尽量避免使用了。
2、尽量使用getApplicationContext:
如果为了满足需求下必须使用Context的话:Context尽量使用Application Context,因为Application的Context的生命周期比较长,引用它不会出现内存泄露的问题
3、尽量避免在ListView适配器中使用线程:
因为线程产生内存泄露的主要原因在于线程生命周期的不可控制。之前使用的自定义ListView中适配数据时使用AsyncTask自行开启线程的,这个比用Thread更危险,因为Thread只有在run函数不结束时才出现这种内存泄露问题,然而AsyncTask内部的实现机制是运用了线程执行池(ThreadPoolExcutor),这个类产生的Thread对象的生命周期是不确定的,是应用程序无法控制的,因此如果AsyncTask作为Activity的内部类,就更容易出现内存泄露的问题。解决办法如下:
①、将线程的内部类,改为静态内部类。
②、在线程内部采用弱引用保存Context引用
六 补充内容:
如果一个listView不做任何的优化,而且有很多的条目,当我们快速的拖动listView的界面的时候,就不断的GCGC(Garbage Collection )垃圾回收,当GC到某个时候就会(OOM)outofmemory内存溢出,应用程序也就会随之挂掉,产生这个问题的原因是什么呢?我们知道listView的特点是每产生一个条目就会调用一次getView方法,如果我们不进行优化,每一次调用都要执行getView方法中的所有语句,而且会在最上面的条目移出界面的时候回收掉这个对象,这样是比较浪费资源的。
这时候我们就会想,如果在条目移出界面的时候不对它进行回收,而是拿回来再次使用,这样不就优化了ListView的效率了吗?幸好,一向给力的谷歌工程师为我们提供了ListView自身的缓存机制,它会缓存条目中的一个条目,当界面最上方的这个条目显示完成之后,就会出现一个缓存条目,也就是BaseView中getView方法中的convertView ,convertView的作用其实就是一个已经被系统回收的历史缓存View对象,我们可以利用这个对象就没有必要再重新去xml文件中去解析布局了。判断传进来的参数convertView是否为null,如果为null就创建convertView并返回,如果不为null,则直接使用。这是第一种优化方法,简单的说就是复用历史缓存的View对象,减少view对象创建的次数。
第二种优化方法是减少findViewById()的次数,findViewById是一个相对比较耗性能的操作,因为每次在getVIew的时候,都需要重新的findViewById,重新找到控件,然后进行控件的赋值以及事件相应设置。这样其实在做重复的事情,因为的getView中,其实包含有这些控件,而且这些控件的id还都是一样的,也就是其实只要在view中findViewById一次,后面无需要每次都要findViewById了。解决这个问题的方法就是把item里面的控件封装成一个javaBean,当item条目被加载的时候就去找到对应的控件 。
前两种优化方式是最一般的优化,一般我们使用listView的时候都会用到这两个优化方法,但是只有这两种方式还远远不够,比如当listView的View对象中有图片资源的时候,就会占用大量的内存,这样就很容易造成内存溢出,对于这种情况有两种优化方法,分批加载和分页加载,我把这两种方法看成是利用时间不同的优化和利用空间的不同的优化。分批加载,我们每次只加载一定数量,就像是在不同的时间段加载一次。而分页加载,就像是把一定数量的条目放在不同的空间,利用这两种思想来实现分批加载和分页加载。
分批加载主要解决的是用户体验的问题,如果数据量过大,用户等待的时间就会很长,而且也会出现Anr异常。比如我们要从数据库中读取100条数据,如果一次性读取,就需要很长的时间,但是这时我们修改sql语句,指定从那一条开始获取数据,一共获取多少数据,sql语句是:
"selectphone,mode from blacknumber limit ? Offset ?",new String[]{String.valueOfa(maxNumber),String.valueOf(StateIndex)}
新获取的数据加到集合的末尾即可。
说分页加载,它的实现思路是这样的,实现OnScrollListener接口,重写onScrollStateChanged和onScroll方法,使用onScroll方法实现“滑动”后处理检查是否还有新纪录,如果有,调用addFooterView,添加记录到adapter,adapter调用notifyDataSetChanged更新数据;如果没有新纪录了,把自定义的mFooterView去掉,使用onScrollStateChanged可以检测是否滚到最后一行且停止滚到然后执行加载。
还有一种优化方式是利用图片异步加载的方法,实现思路是:
1.先从内存缓存中获取图片显示(内存缓冲)
2.获取不到的话从SD卡里获取(SD卡缓冲,从SD卡获取图片是放在子线程里执行的,否则快速划瓶的话会不够流畅)
3.都获取不到的话从网络下载图片并保存到SD卡同时加入内存并显示(视情况看是否要显示)
我们在使用listview的时候可能会出现图片乱跳(错位)的问题:
图片错位问题的本质源于我们的listview使用了缓存convertView,假设一种场景,一个listview一屏显示九个item,那么在拉出第十个item的时候,事实上该item是重复使用了第一个item,也就是说在第一个item从网络中下载图片并最终要显示的时候,其实该item已经不在当前显示区域内了,此时显示的后果将可能在第十个item上输出图像,这就导致了图片错位的问题。所以解决之道在于可见则显示,不可见则不显示。在ImageLoader里有个imageViews的map对象,就是用于保存当前显示区域图像对应的url集,在显示前判断处理一下即可。