SANAPHOR: Ontology-Based Coreference Resolution笔记
这篇文章是iswc(International Semantic Web Conference)2015年的论文。
里面好多NLP方面的基础知识。
要做笔记,就写在这里吧,方便以后查看。
暂时先写这么多吧(2016/4/13)
读了TRank,以及BLANC里面的metric。(2016/4/14)
ontology&entity&mention(这三个名词真是==)
本体&实体&提及
本体就是一个比较虚的东西,来自哲学概念,主要指的描述概念及概念之间关系的概念模型, 通过概念之间的关系来描述概念的语义。
实体就是mention指向的东西,具有实际的意义。
提及就是在文中提到的短语什么的。
总的来说就是一个文本中会有很多mention;这些mention可能指向同一个实体,或者不同的实体;然后这些实体可能都属于一个本体类别下(比如都属于语言学等等)。
DBpedia&Wikipedia&YAGO
<待补充>entity linking
实体连接:就是把mention连接到具体指的什么时实体上面去。最简单的,可以做一个字符串匹配,达到某一个阈值,就认为属于这个entity。
分为三步:mention detection, link generation, and disambiguation
涉及技术
LDA&Interger Linear Programming
<待补充>
TRank
是一个给实体类型排序的系统。具体详情
论文:TRank: Ranking Entity Types Using the Web of Data
文章出现三次对论文TRank的引用:
1)In the context of this paper, both NER and Entity Linking are prerequisites for coreference resolution as we take advantage of external knowledge to improve
the resolution of coreferences and hence must first identify and link as many entity mentions as possible to their counterparts in the knowledge base. Since,
however, those two tasks are not the focus of this work, we decided to use in this paper the TRank pipeline because of its simplicity and its good performance inpractice on our dataset (前言部分entity linking)
2)TRank is a system for ranking entity types given the textual context in which they appear(前言部分 entity types)
3)For the mentions linked in the previous step, we employ the mappings between DBPedia and YAGO ontologies provided by TRank Hierarchy to map DBPedia types to YAGO ones.(semantic annotation部分,semantic typing)
文章的4部分 Approaches to Entity Type Ranking
主体结构为:输入网页->利用NER选取出entity->得到entityURI->得到URI的所有types URI->排序type
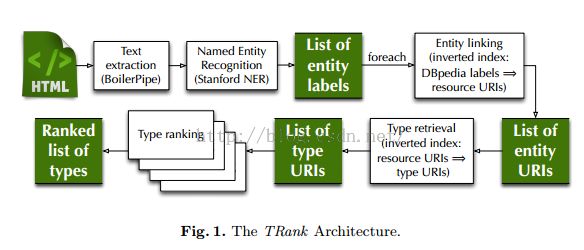
First,given a Web page (e.g., a news article), we identify entities mentioned in the textual content of the document using state-of-the-art NER focusing on persons,locations, and organizations.
Next, we use an inverted index constructed over DBpedia literals attached to its URIs and use the extracted entity as a query to the index to select the best-matching URI for that entity.
Then,given an entity URI, we retrieve (for example, thanks to a SPARQL query to a knowledge base) all the types attached to the entity.
Finally, our system produces a ranking of the resulting types based on the textual context where the entity has been mentioned
排序的方法:
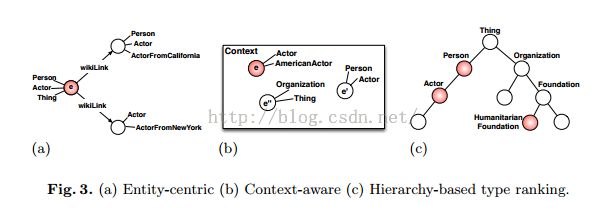
The proposed approaches for entity type ranking can be grouped in entity-centric, context-aware, and hierarchy-based
主要方法介绍:
Entity-Centric Ranking Approaches
PREQ:根据类型在背景知识库下面的频率(frequency),
WIKILINK:利用给定的实体和背景知识库的拓展实体的关系。对相邻实体进行计数,可以利用SPARQL来做。
LABEL:舍弃文本相似的方法,计算标签e与背景知识库中其他的标签的TF-IDF相似度来找到关联实体,使用最相关的实体来给e的类型排序。挑选出top-10个与e有最相似的标签的实体,基于frequency对实体排序。
Context-Aware Ranking Approaches
SAMETYPE:当相同的URI类型被e和e'使用的时候,或者e和e'有共同的标签的时候,是一个匹配。
PATH:利用类型层次和e出现的上下文。根据从root到t的路径的相似度来排序。
Hierarchy-Based Ranking Approaches
使用类型层次评估实体类型ti关联到实体e的深度来评价关联性。
ANCESTORS:how many ancestors of ti ∈ Te are also a type of e. That is, if Ancestors(ti) is the set of ancestors of ti in the integrated type hierarchy, then
we define the score of ti as the size of the set {tj|tj ∈ Ancestors(ti) ∧ tj ∈ Te}.
For example, in Figure 3c we rank first the type ‘Actor’ because ‘Person’ is its ancestor and it is also a type of e. On the other hand, the type ‘Humanitarian Foundation’ has a bigger depth but no ancestor which is also a type of e.
ANC_DEPTH:considers not just the number of such ancestors of ti but also their depth

使用训练集找到最好的方法来联合不同的技术,使用决策树和线性回归模型来联合排序的方法。决策树使用M5。
TF-IDF
TF词频(Term Frequency),表示词条在文档d中出现的频率
IDF逆向文件频率(Inverse Document Frequency)。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。这就是IDF的不足之处
词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)对于在某一特定文件里的词语来说,它的重要性可表示为:
![]()
式子中分子是该词在文件中的出现次数,而分母则是在文件中所有字词的出现次数之和。
逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到
![]()
|D|:语料库中的文件总数
:包含词语的文件数目(即的文件数目)如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用作为分母
TF-IDF
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语
Coreference Resolution&Anaphora Resolution
共指消解与指代消解
共指就是两个mention指向的同一个entity;e.g:iphone 和苹果手机(虽然貌似需要语言一样==)
指代就是后面的mention需要前面的mention来解析,存在一定的关系;e.g:(小明迟到了,这真是奇怪。”这“需要”小明“来解析,但是属于不同的entity,一个指的是一件事,一个指的是一个人)
两者的结合就是,后面的mention需要前面的mention来解析,并且两个mention指的是同一个entity。e.g:(还是前面的例子,小明迟到了,他不经常迟到的。”他“需要前面的”小明“来解析,而且两个都是指小明这个人)。
Metrics
这篇文章介绍了很多metric
BLANC: Implementing the Rand Index for Coreference Evaluation
<待补充>
Recall&Presicion&F1
召回率:Recall,又称“查全率”。
准确率:Precision,又称“精度”、“正确率”。
在一个大规模数据集合中检索文档时,可把集合中的所有文档分成四类:
相关的 不相关的
检索到的 A B
未检索到的 C D
A:检索到的,相关的 (搜到的也想要的)
B:检索到的,但是不相关的 (搜到的但没用的)
C:未检索到的,但却是相关的 (没搜到,然而实际上想要的)
D:未检索到的,也不相关的 (没搜到也没用的)
通常我们希望:数据库中相关的文档,被检索到的越多越好,这是追求“查全率”,即A/(A+C),越大越好。
同时我们还希望:检索到的文档中,相关的越多越好,不相关的越少越好,这是追求“准确率”,即A/(A+B),越大越好。
归纳如下:
召回率:检索到的相关文档 比 库中所有的相关文档
准确率:检索到的相关文档 比 所有被检索到的文档
“召回率”与“准确率”虽然没有必然的关系(从上面公式中可以看到),然而在大规模数据集合中,这两个指标却是相互制约的。
由于“检索策略”并不完美,希望更多相关的文档被检索到时,放宽“检索策略”时,往往也会伴随出现一些不相关的结果,从而使准确率受到影响。
而希望去除检索结果中的不相关文档时,务必要将“检索策略”定的更加严格,这样也会使有一些相关的文档不再能被检索到,从而使召回率受到影响。
凡是设计到大规模数据集合的检索和选取,都涉及到“召回率”和“准确率”这两个指标。而由于两个指标相互制约,我们通常也会根据需要为“检索策略”选择一个合适的度,不能太严格也不能太松,寻求在召回率和准确率中间的一个平衡点。这个平衡点由具体需求决定。
Recall:the ability to remember sth. that you have learned or sth.that has happened in the past.
Recall就是指:检索系统能“回忆”起那些事的多少细节,通俗来讲就是“回忆的能力”。能回忆起来的细节数除以 系统知道这件事的所有细节,就是“记忆率”,也就是recall——召回率。
F-Measure是Precision和Recall的加权调和平均:
F=(a*a+1)P*R/(a*a(P+R))
当a=1时,就是常见的F1
F1=2*P*R/(P+R)
可见,当F1较大时,实验结果比较理想
参考网址:
http://blog.sina.com.cn/s/blog_4a1853330100l4xw.html