神经网络更新参数的几种方法
梯度下降中,计算完各个参数的导数之后就需要更新参数值了,最常用的更新参数方法就是:
【SGD】:
- x += - learning_rate * dx
但是这种方法收敛速度非常慢,其实除了这个更新参数的方法,还有很多的方法可以进行参数更新。
【Momentum update】:
这个方法对于深度学习的网络参数更新往往有不错的效果。本质意思是,在更新新的参数的时候需要考虑前一个时刻的“惯性”,其更新参数如下:
- # Momentum update
- v = mu * v - learning_rate * dx # integrate velocity
- x += v # integrate position
上面计算方法和下面的等价(其中的ρ等价于上面的mu):

其中一般的,v初始为0,mu是优化参数,一般初始化参数为0.9,当使用交叉验证的时候,参数mu一般设置成[0.5,0.9,0.95,0.99],在开始训练的时候,梯度下降较快,可以设置mu为0.5,在一段时间后逐渐变慢了,mu可以设置为0.9、0.99。也正是因为有了“惯性”,这个比SGD会稳定一些。
【Nesterov Momentum】
这是一个和上面的Momentum update有点不一样的方法,这种方法最近得到了较为广泛的运用,对于凸函数,它有更为快的收敛速度。
计算公式:
- x_ahead = x + mu * v
- # evaluate dx_ahead (the gradient at x_ahead instead of at x)
- v = mu * v - learning_rate * dx_ahead
- x += v
其基本思路如下:(参考自各种优化方法的比较)
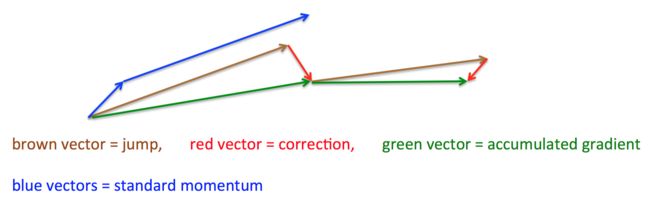
首先,按照原来的更新方向更新一步(x_ahead,也就是棕色线),然后在该位置计算梯度值(也就是dx_ahead,红色线),然后用这个梯度值修正最终的更新方向(绿色线)。上图中描述了两步的更新示意图,其中蓝色线是标准momentum更新路径
【Adagrad】
adagrad是一种自适应学习率的更新方法,计算方法如下:
- <strong># Assume the gradient dx and parameter vector x
- cache += dx**2
- x += - learning_rate * dx / (np.sqrt(cache) + eps)</strong>
这个方法其实是动态更新学习率的方法,其中cache将每个梯度的平方和相加,而更新学习率的本质是,如果求得梯度距离越大,那么学习率就变慢,而eps是一个平滑的过程,取值通常在(10^-4~10^-8 之间)
【RMSprop】
RMSpro是还没有发布的方法,但是已经使用的额相当广泛,其和Adagrad的方法差不多,计算方法如下:
- <strong>cache = decay_rate * cache + (1 - decay_rate) * dx**2
- x += - learning_rate * dx / (np.sqrt(cache) + eps)</strong>
其中,decay_rate取值通常在[0.9,0.99,0.999]
【Adam】
adam现在已经被广泛运用了,adam的更新参数方法如下:
- <strong>m = beta1*m + (1-beta1)*dx
- v = beta2*v + (1-beta2)*(dx**2)
- x += - learning_rate * m / (np.sqrt(v) + eps)</strong>
m,v一般初始化为0,而这篇论文中,eps取值为1e-8 beta1=0.9 beta2=0.9999
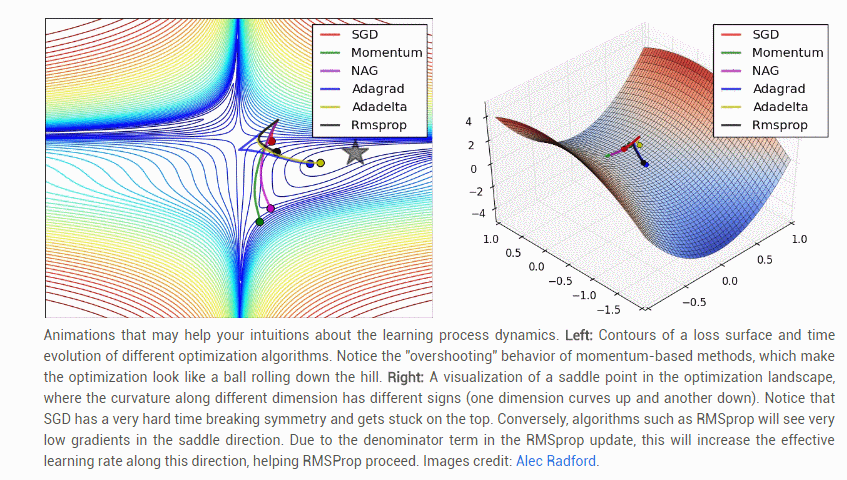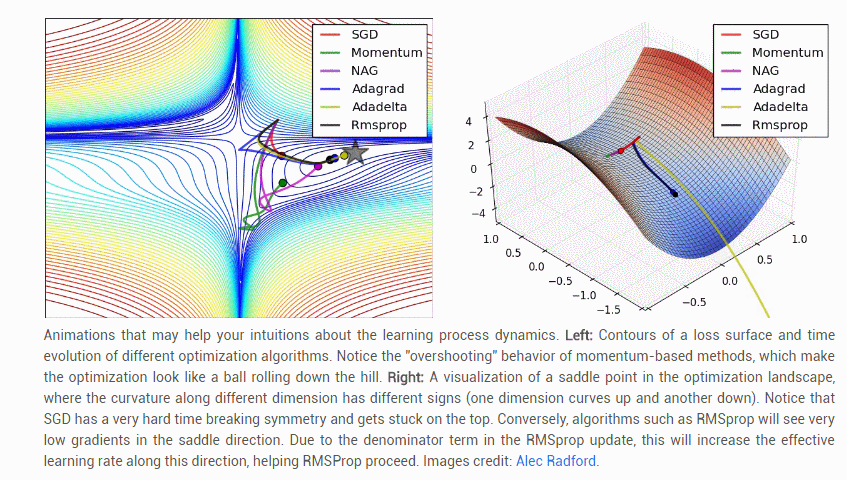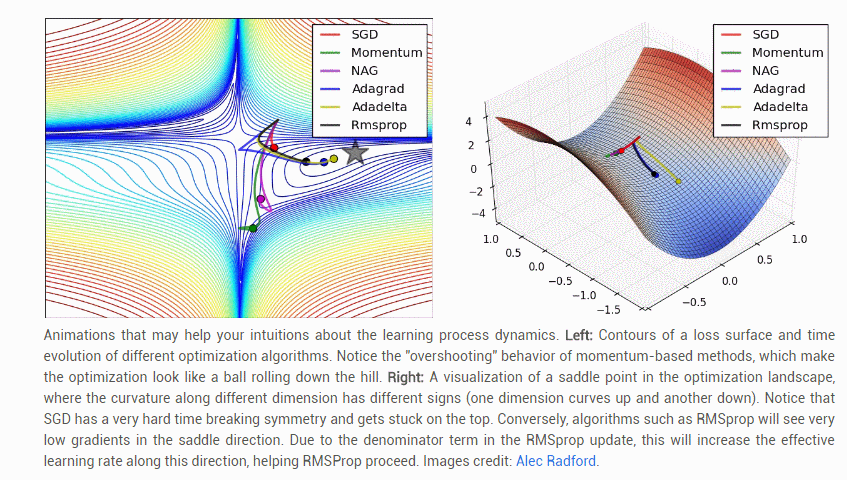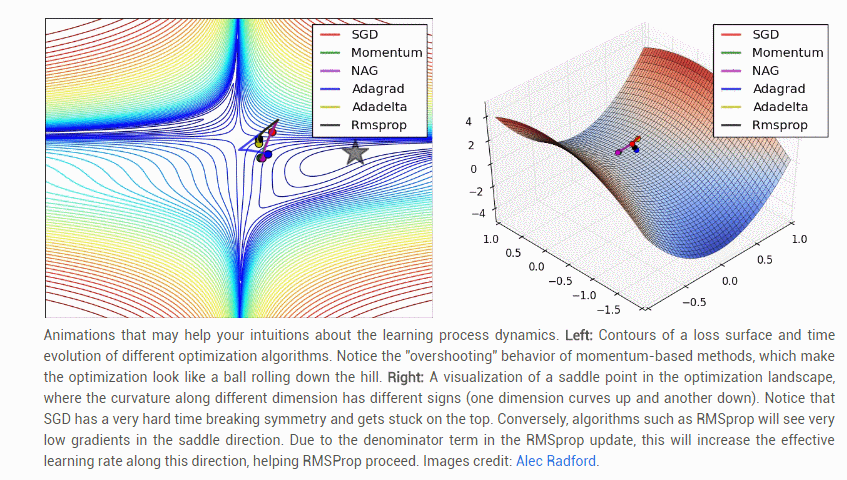
【几种常见参数更新方法的比较】: