二分图匹配(匈牙利算法)
【书本上的算法往往讲得非常复杂,我计划用一个幽默的例子来描述算法的流程】
匈牙利算法是由匈牙利数学家Edmonds于1965年提出,因而得名。匈牙利算法是基于Hall定理中充分性证明的思想,它是部图匹配最常见的算法,该算法的核心就是寻找增广路径,它是一种用增广路径求二分图最大匹配的算法。
一.先上基本概念:
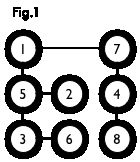
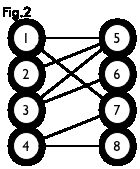
二分图:简单来说,如果图中点可以被分为两组,并且使得所有边都跨越组的边界,则这就是一个二分图。准确地说:把一个图的顶点划分为两个不相交集 U U 和 V V ,使得每一条边都分别连接 U U、 V V中的顶点。如果存在这样的划分,则此图为一个二分图。二分图的一个等价定义是:不含有「含奇数条边的环」的图。图 1 是一个二分图。为了清晰,我们以后都把它画成图 2 的形式。
匹配:在图论中,一个「匹配」(matching)是一个边的集合,其中任意两条边都没有公共顶点。例如,图 3、图 4 中红色的边就是图 2 的匹配。
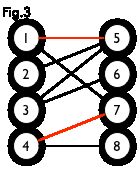
我们定义匹配点、匹配边、未匹配点、非匹配边,它们的含义非常显然。例如图 3 中 1、4、5、7 为匹配点,其他顶点为未匹配点;1-5、4-7为匹配边,其他边为非匹配边。
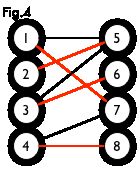
最大匹配:一个图所有匹配中,所含匹配边数最多的匹配,称为这个图的最大匹配。图 4 是一个最大匹配,它包含 4 条匹配边。
完美匹配:如果一个图的某个匹配中,所有的顶点都是匹配点,那么它就是一个完美匹配。图 4 是一个完美匹配。显然,完美匹配一定是最大匹配(完美匹配的任何一个点都已经匹配,添加一条新的匹配边一定会与已有的匹配边冲突)。但并非每个图都存在完美匹配。
举例来说:如下图所示,如果在某一对男孩和女孩之间存在相连的边,就意味着他们彼此喜欢。是否可能让所有男孩和女孩两两配对,使得每对儿都互相喜欢呢?图论中,这就是完美匹配问题。如果换一个说法:最多有多少互相喜欢的男孩/女孩可以配对儿?这就是最大匹配问题。

算法的思路是不停的找增广路径, 并增加匹配的个数,增广路径顾名思义是指一条可以使匹配数变多的路径,在匹配问题中,增广路径的表现形式是一条"交错路径",也就是说这条由图的边组成的路径, 它的第一条边是目前还没有参与匹配的,第二条边参与了匹配,第三条边没有..最后一条边没有参与匹配,并且始点和终点还没有被选择过。这样交错进行,显然他有奇数条边。那么对于这样一条路径,我们可以将第一条边改为已匹配,第二条边改为未匹配...以此类推。也就是将所有的边进行"反色",容易发现这样修改以后,匹配仍然是合法的,但是匹配数增加了一对。另外,单独的一条连接两个未匹配点的边显然也是交错路径。可以证明。当不能再找到增广路径时,就得到了一个最大匹配,这也就是匈牙利算法的思路。
看完上面的叙述,初学者肯定会感觉头皮发麻,别担心,让我们看一个幽默的例子:
通过数代人的努力,你终于赶上了剩男剩女的大潮,假设你是一位光荣的新世纪媒人,在你的手上有N个剩男,M个剩女,每个人都可能对多名异性有好感(![]() -_-||暂时不考虑特殊的性取向),如果一对男女互有好感,那么你就可以把这一对撮合在一起,现在让我们无视掉所有的单相思(好忧伤的感觉
-_-||暂时不考虑特殊的性取向),如果一对男女互有好感,那么你就可以把这一对撮合在一起,现在让我们无视掉所有的单相思(好忧伤的感觉![]() ),你拥有的大概就是下面这样一张关系图,每一条连线都表示互有好感。
),你拥有的大概就是下面这样一张关系图,每一条连线都表示互有好感。
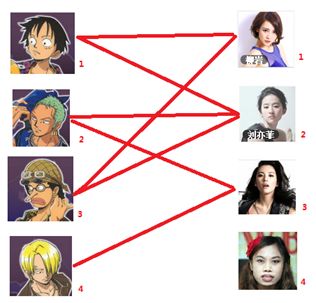
本着救人一命,胜造七级浮屠的原则,你想要尽可能地撮合更多的情侣,匈牙利算法的工作模式会教你这样做:
===============================================================================
一: 先试着给1号男生找妹子,发现第一个和他相连的1号女生还名花无主,got it,连上一条蓝线
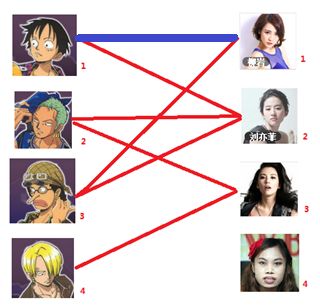
===============================================================================
二:接着给2号男生找妹子,发现第一个和他相连的2号女生名花无主,got it
===============================================================================
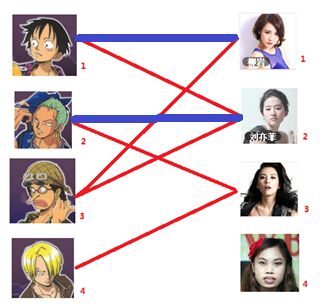
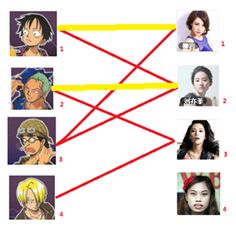
三:接下来是3号男生,很遗憾1号女生已经有主了,怎么办呢?
我们试着给之前1号女生匹配的男生(也就是1号男生)另外分配一个妹子。
(黄色表示这条边被临时拆掉)
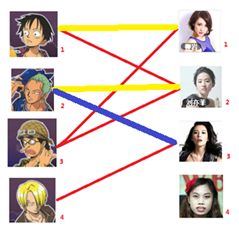
与1号男生相连的第二个女生是2号女生,但是2号女生也有主了,怎么办呢?我们再试着给2号女生的原配(![]()
![]() )重新找个妹子(注意这个步骤和上面是一样的,这是一个递归的过程)
)重新找个妹子(注意这个步骤和上面是一样的,这是一个递归的过程)
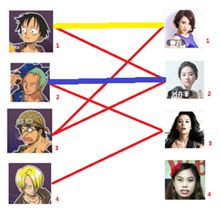
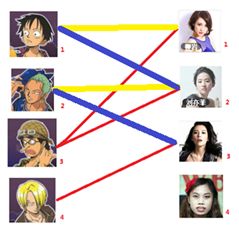
此时发现2号男生还能找到3号女生,那么之前的问题迎刃而解了,回溯回去
2号男生可以找3号妹子~~~ 1号男生可以找2号妹子了~~~ 3号男生可以找1号妹子
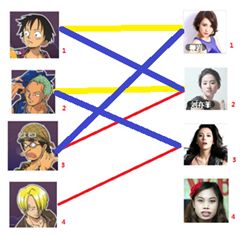
所以第三步最后的结果就是:
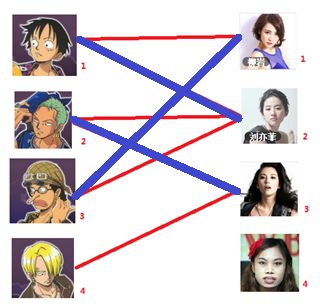
===============================================================================
四: 接下来是4号男生,很遗憾,按照第三步的节奏我们没法给4号男生腾出来一个妹子,我们实在是无能为力了……
===============================================================================
其原则大概是:有机会上,没机会创造机会也要上
三.贴代码:
1.邻接矩阵
bool dfs(int x)
{
int i,j;
for (j=1;j<=m;j++)
{ //扫描每个妹子
if (map[x][j] && !book[j])
//如果有暧昧并且还没有标记过(这里标记的意思是这次查找曾试图改变过该妹子的归属问题,但是没有成功,所以就不用瞎费工夫了)
{
book[j]=1;
if (match[j]==0 || dfs(match[j])) {
//名花无主或者能腾出个位置来,这里使用递归
match[j]=x;//编号为j的girl是编号为x的boy的了。
return true;
}
}
}
return false;
}
for (i=1;i<=n;i++) //一共有n个boy,从第一个开始解决情感问题
{
memset(book,0,sizeof(book)); //这个在每一步中清空
if (dfs(i))
cnt++;
}
2.邻接表:
bool dfs(int x)
{
for(int y=0;y<map[x].size();y++)//push_back是从零下标开始的;
{
if(map[x][y]&&!book[map[x][y]])
{
book[map[x][y]]=1;
if(!match[map[x][y]]||dfs(match[map[x][y]]))//名花为主,或者尝试抢一抢
{
match[map[x][y]]=x;
return true;
}
}
}
return false;
}
<span style="white-space:pre"> </span>memset(map,0,sizeof(map));
memset(match,0,sizeof(match));
ans=0;
scanf("%d%d",&n,&m);
int x,y;
while(m--)
{
scanf("%d%d",&x,&y);
map[x].push_back(y);
}
for(int i=1;i<=n;i++)//从第一个男孩起解决情感问题
{
memset(book,0,sizeof(book));
if(dfs(i))
ans++;
}
printf("%d\n",ans);