基于baseline、svd和stochastic gradient descent的个性化推荐系统
文章主要介绍的是koren 08年发的论文[1], 2.3部分内容(其余部分会陆续补充上来)。
koren论文中用到netflix 数据集, 过于大, 在普通的pc机上运行时间很长很长。考虑到写文章目地主要是已介绍总结方法为主,所以采用Movielens 数据集。
变量介绍

部分变量介绍可以参看《基于baseline和stochastic gradient descent的个性化推荐系统》
文章中,将介绍两种方法实现的简易个性化推荐系统,用RMSE评价标准,对比这两个方法的实验结果。
(1) svd + stochstic gradient descent 方法来实现系统。
(2) baseline + svd + stochastic gradient descent 方法来实现系统。
注:
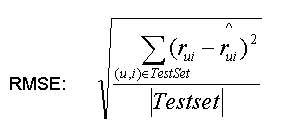
方法1: svd + stochastic gradient descent
svd:
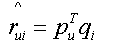
cost function:
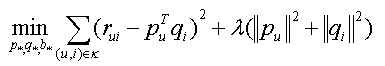
梯度变化(利用stochastic gradient descent算法使上述的目标函数值,在设定的迭代次数内,降到最小)
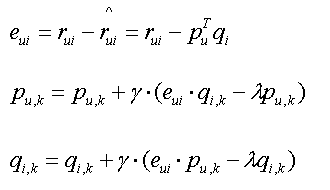
方法1,具体代码实现
- '''''
- Created on Dec 13, 2012
- @Author: Dennis Wu
- @E-mail: [email protected]
- @Homepage: http://blog.csdn.net/wuzh670
- Data set download from : http://www.grouplens.org/system/files/ml-100k.zip
- '''
- from operator import itemgetter, attrgetter
- from math import sqrt
- import random
- def load_data():
- train = {}
- test = {}
- filename_train = 'data/ua.base'
- filename_test = 'data/ua.test'
- for line in open(filename_train):
- (userId, itemId, rating, timestamp) = line.strip().split('\t')
- train.setdefault(userId,{})
- train[userId][itemId] = float(rating)
- for line in open(filename_test):
- (userId, itemId, rating, timestamp) = line.strip().split('\t')
- test.setdefault(userId,{})
- test[userId][itemId] = float(rating)
- return train, test
- def calMean(train):
- stat = 0
- num = 0
- for u in train.keys():
- for i in train[u].keys():
- stat += train[u][i]
- num += 1
- mean = stat*1.0/num
- return mean
- def initialFeature(feature, userNum, movieNum):
- random.seed(0)
- user_feature = {}
- item_feature = {}
- i = 1
- while i < (userNum+1):
- si = str(i)
- user_feature.setdefault(si,{})
- j = 1
- while j < (feature+1):
- sj = str(j)
- user_feature[si].setdefault(sj,random.uniform(0,1))
- j += 1
- i += 1
- i = 1
- while i < (movieNum+1):
- si = str(i)
- item_feature.setdefault(si,{})
- j = 1
- while j < (feature+1):
- sj = str(j)
- item_feature[si].setdefault(sj,random.uniform(0,1))
- j += 1
- i += 1
- return user_feature, item_feature
- def svd(train, test, userNum, movieNum, feature, user_feature, item_feature):
- gama = 0.02
- lamda = 0.3
- slowRate = 0.99
- step = 0
- preRmse = 1000000000.0
- nowRmse = 0.0
- while step < 100:
- rmse = 0.0
- n = 0
- for u in train.keys():
- for i in train[u].keys():
- pui = 0
- k = 1
- while k < (feature+1):
- sk = str(k)
- pui += user_feature[u][sk] * item_feature[i][sk]
- k += 1
- eui = train[u][i] - pui
- rmse += pow(eui,2)
- n += 1
- k = 1
- while k < (feature+1):
- sk = str(k)
- user_feature[u][sk] += gama*(eui*item_feature[i][sk] - lamda*user_feature[u][sk])
- item_feature[i][sk] += gama*(eui*user_feature[u][sk] - lamda**item_feature[i][sk])
- k += 1
- nowRmse = sqrt(rmse*1.0/n)
- print 'step: %d Rmse: %s' % ((step+1), nowRmse)
- if (nowRmse < preRmse):
- preRmse = nowRmse
- gama *= slowRate
- step += 1
- return user_feature, item_feature
- def calRmse(test, user_feature, item_feature, feature):
- rmse = 0.0
- n = 0
- for u in test.keys():
- for i in test[u].keys():
- pui = 0
- k = 1
- while k < (feature+1):
- sk = str(k)
- pui += user_feature[u][sk] * item_feature[i][sk]
- k += 1
- eui = pui - test[u][i]
- rmse += pow(eui,2)
- n += 1
- rmse = sqrt(rmse*1.0 / n)
- return rmse;
- if __name__ == "__main__":
- # load data
- train, test = load_data()
- print 'load data success'
- # initial user and item feature, respectly
- user_feature, item_feature = initialFeature(100, 943, 1682)
- print 'initial user and item feature, respectly success'
- # baseline + svd + stochastic gradient descent
- user_feature, item_feature = svd(train, test, 943, 1682, 100, user_feature, item_feature)
- print 'svd + stochastic gradient descent success'
- # compute the rmse of test set
- print 'the Rmse of test test is: %s' % calRmse(test, user_feature, item_feature, 100)
方法2:baseline + svd + stochastic gradient descent
baseline + svd:
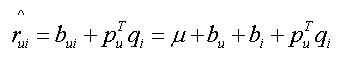
object function:
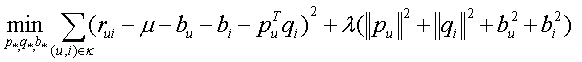
梯度变化(利用stochastic gradient descent算法使上述的目标函数值,在设定的迭代次数内,降到最小)
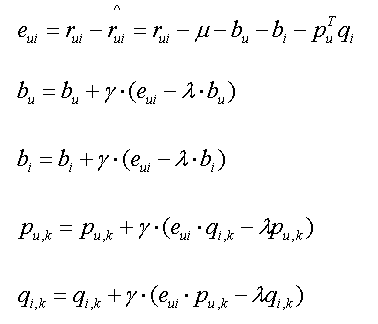
方法2: 具体代码实现
- '''''
- Created on Dec 13, 2012
- @Author: Dennis Wu
- @E-mail: [email protected]
- @Homepage: http://blog.csdn.net/wuzh670
- Data set download from : http://www.grouplens.org/system/files/ml-100k.zip
- '''
- from operator import itemgetter, attrgetter
- from math import sqrt
- import random
- def load_data():
- train = {}
- test = {}
- filename_train = 'data/ua.base'
- filename_test = 'data/ua.test'
- for line in open(filename_train):
- (userId, itemId, rating, timestamp) = line.strip().split('\t')
- train.setdefault(userId,{})
- train[userId][itemId] = float(rating)
- for line in open(filename_test):
- (userId, itemId, rating, timestamp) = line.strip().split('\t')
- test.setdefault(userId,{})
- test[userId][itemId] = float(rating)
- return train, test
- def calMean(train):
- stat = 0
- num = 0
- for u in train.keys():
- for i in train[u].keys():
- stat += train[u][i]
- num += 1
- mean = stat*1.0/num
- return mean
- def initialBias(train, userNum, movieNum, mean):
- bu = {}
- bi = {}
- biNum = {}
- buNum = {}
- u = 1
- while u < (userNum+1):
- su = str(u)
- for i in train[su].keys():
- bi.setdefault(i,0)
- biNum.setdefault(i,0)
- bi[i] += (train[su][i] - mean)
- biNum[i] += 1
- u += 1
- i = 1
- while i < (movieNum+1):
- si = str(i)
- biNum.setdefault(si,0)
- if biNum[si] >= 1:
- bi[si] = bi[si]*1.0/(biNum[si]+25)
- else:
- bi[si] = 0.0
- i += 1
- u = 1
- while u < (userNum+1):
- su = str(u)
- for i in train[su].keys():
- bu.setdefault(su,0)
- buNum.setdefault(su,0)
- bu[su] += (train[su][i] - mean - bi[i])
- buNum[su] += 1
- u += 1
- u = 1
- while u < (userNum+1):
- su = str(u)
- buNum.setdefault(su,0)
- if buNum[su] >= 1:
- bu[su] = bu[su]*1.0/(buNum[su]+10)
- else:
- bu[su] = 0.0
- u += 1
- return bu,bi
- def initialFeature(feature, userNum, movieNum):
- random.seed(0)
- user_feature = {}
- item_feature = {}
- i = 1
- while i < (userNum+1):
- si = str(i)
- user_feature.setdefault(si,{})
- j = 1
- while j < (feature+1):
- sj = str(j)
- user_feature[si].setdefault(sj,random.uniform(0,1))
- j += 1
- i += 1
- i = 1
- while i < (movieNum+1):
- si = str(i)
- item_feature.setdefault(si,{})
- j = 1
- while j < (feature+1):
- sj = str(j)
- item_feature[si].setdefault(sj,random.uniform(0,1))
- j += 1
- i += 1
- return user_feature, item_feature
- def svd(train, test, mean, userNum, movieNum, feature, user_feature, item_feature, bu, bi):
- gama = 0.02
- lamda = 0.3
- slowRate = 0.99
- step = 0
- preRmse = 1000000000.0
- nowRmse = 0.0
- while step < 100:
- rmse = 0.0
- n = 0
- for u in train.keys():
- for i in train[u].keys():
- pui = 1.0 * (mean + bu[u] + bi[i])
- k = 1
- while k < (feature+1):
- sk = str(k)
- pui += user_feature[u][sk] * item_feature[i][sk]
- k += 1
- eui = train[u][i] - pui
- rmse += pow(eui,2)
- n += 1
- bu[u] += gama * (eui - lamda * bu[u])
- bi[i] += gama * (eui - lamda * bi[i])
- k = 1
- while k < (feature+1):
- sk = str(k)
- user_feature[u][sk] += gama*(eui*item_feature[i][sk] - lamda*user_feature[u][sk])
- item_feature[i][sk] += gama*(eui*user_feature[u][sk] - lamda*item_feature[i][sk])
- k += 1
- nowRmse = sqrt(rmse*1.0/n)
- print 'step: %d Rmse: %s' % ((step+1), nowRmse)
- if (nowRmse < preRmse):
- preRmse = nowRmse
- gama *= slowRate
- step += 1
- return user_feature, item_feature, bu, bi
- def calRmse(test, bu, bi, user_feature, item_feature, mean, feature):
- rmse = 0.0
- n = 0
- for u in test.keys():
- for i in test[u].keys():
- pui = 1.0 * (mean + bu[u] + bi[i])
- k = 1
- while k < (feature+1):
- sk = str(k)
- pui += user_feature[u][sk] * item_feature[i][sk]
- k += 1
- eui = pui - test[u][i]
- rmse += pow(eui,2)
- n += 1
- rmse = sqrt(rmse*1.0 / n)
- return rmse;
- if __name__ == "__main__":
- # load data
- train, test = load_data()
- print 'load data success'
- # Calculate overall mean rating
- mean = calMean(train)
- print 'Calculate overall mean rating success'
- # initial user and item Bias, respectly
- bu, bi = initialBias(train, 943, 1682, mean)
- print 'initial user and item Bias, respectly success'
- # initial user and item feature, respectly
- user_feature, item_feature = initialFeature(100, 943, 1682)
- print 'initial user and item feature, respectly success'
- # baseline + svd + stochastic gradient descent
- user_feature, item_feature, bu, bi = svd(train, test, mean, 943, 1682, 100, user_feature, item_feature, bu, bi)
- print 'baseline + svd + stochastic gradient descent success'
- # compute the rmse of test set
- print 'the Rmse of test test is: %s' % calRmse(test, bu, bi, user_feature, item_feature, mean, 100)
实验参数设置:
![]()
(gama = 0.02 lamda =0.3)
feature = 100 maxstep = 100 slowRate = 0.99(随着迭代次数增加,梯度下降幅度越来越小)
方法1结果:Rmse of test set : 1.00422938926
方法2结果:Rmse of test set : 0.963661477881
REFERENCES
1.Y. Koren. Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model. Proc. 14th ACM SIGKDD Int. Conf. On Knowledge Discovery and Data Mining (KDD’08), pp. 426–434, 2008.
2. Y.Koren. The BellKor Solution to the Netflix Grand Prize 2009
转载请注明:转自 zh's note http://blog.csdn.net/wuzh670/