[Mitchell 机器学习读书笔记]——人工神经网络
1、简介
神经网络学习方法对于逼近实数值、离散值或向量值的目标函数提供了一种健壮性很强的方法。在现实中,学习解释复杂的现实世界中的传感器数据,人工神经网络(Artificial Neural Networks,ANN )是最有效的方法。反向学习传播算法已经在很多领域中取得了成功,比如学习识别手写字符、学习识别口语和学习识别人脸。
人工神经网络的研究在一定程度上受到生物学的启发,因为生物学的学习系统是由相互连接的神经元组成的异常复杂的网络,人工神经网络大体相似,也是由一系列简单的单元相互密集连接构成的,其中每一个单元有一定数量的实值输入,并产生单一的实数输出,而输入可能来自其他单元的输出,输出也可能称为其他单元的输入。
一般来说,ANN研究领域有两个目标:
1、使用ANN研究和模拟生物学习过程;
2、获得高效的机器学习算法,而不管这种算法是否反映了生物过程。
机器学习中一般是研究第二个目标。
2、神经网络表示
![[Mitchell 机器学习读书笔记]——人工神经网络_第1张图片](http://img.e-com-net.com/image/info5/db011fb5d3ba4b26902025e44b3c31b1.jpg)
如上图,中间的隐藏节点(Hidden)接收每个Inpu节点t的输入,产生的输出称为Output节点的输入,最后通过Output节点对应产生相应的输出值,最后根据这些输出来得到最后的结果。当然,这只是ANN的一种常用表示模型,即2层模型,还有1层、3层等模型,更多层的模型不常见,每一层的节点数目也不是固定的。有些模型还具备有环的特征。
3、神经网络的适用问题
ANN学习适用于这些问题:训练集合为含有噪声的复杂传感器数据,例如来自摄像机和麦克风的数据。也适用于需要较多符号表示的问题,如 前一篇文章提到的决策树学习任务。在这种情况下ANN和决策树学习经常产生精度大体相当的结果。
反向传播算法是最常用的ANN学习技术,它适合具有以下特征的问题:
- 实例是很多“属性--值”对表示的;
- 目标函数的输出可能是离散值、实数值或者由若干实数属性或离散属性组成的向量;
- 训练数据可能包含错误;
- 可容忍长时间的训练;
- 可能需要快速求出目标函数值;(这一点和前面一点要注意一下,尽管ANN的学习时间相对较长,但是学习好构成网络后,来求后续的实例是非常快速的)
- 人类能否理解学到的目标函数是不重要的。(这一点我认为可能是人类还不知道目标函数大概是什么,或许目标函数)
4、感知器
一种类型的ANN系统是以被称为感知器的单元为基础的,如果感知器以一个实数值向量作为输入,然后计算这些输入的线性组合,然后当结果大于某个阈值的时候,就输出1,否则输出-1,结构如下图所示:
![[Mitchell 机器学习读书笔记]——人工神经网络_第2张图片](http://img.e-com-net.com/image/info5/df4f76fcc84041fd95eafe1a960b587f.png)
其中:
 表示对于实数向量的线性组合,X_T代表实数向量,W代表权值,即每个输入x_i对于输出的贡献率。sgn(·)是一个符号函数。
表示对于实数向量的线性组合,X_T代表实数向量,W代表权值,即每个输入x_i对于输出的贡献率。sgn(·)是一个符号函数。
现在已经很清楚了,感知器的作用相当于一个布尔函数,将各个输入的值加权组合输出-1或1。
学习一个感知器意味着选择权值w_0,w_1,……,w_n的值(注意:图中的下标是从1到n+1),所以感知器要学习的候选假设空间就是所有可能的实数权值向量的集合。
4.1 感知器的表征能力
感知器可以看作是n维实例空间(即点空间)中的超平面决策面。对于超平面的一侧的实例,感知器输出1,对于另一侧的实例输出为-1,如下图:
![[Mitchell 机器学习读书笔记]——人工神经网络_第3张图片](http://img.e-com-net.com/image/info5/953863fe62364a36bda60bb046554b0e.png)
这种可以被分割的称为线性可分样例集合,还有线性不可分的样例集合,如下图:
![[Mitchell 机器学习读书笔记]——人工神经网络_第4张图片](http://img.e-com-net.com/image/info5/ae6289b2898e4cb6aa7013da8cfa8a74.png)
前面说过,感知器相当于一个布尔函数,此外,还有一个特点,感知器可以表示所有的原子布尔函数:与、或、与非、或非等,但是还是有些布尔函数不能表示,抑或就是其中之一,如上图所示,这个是不能被感知器表示出来的,但是所有的布尔函数可以表示成基于这些原子函数的互连单元的某个网络,实际上,仅用两层深度的感知器网络就可以表示所有的布尔函数,实际应用中,研究的最多也是由多个感知器组成的多层网络。
4.2
感知器训练法则
这里的学习任务是决定一个权向量,可以使感知器对于给定的训练样例输出正确的1或-1。
为了得到可接受的权向量,一种办法是从随机的权值开始,然后反复的应用这个感知器到每个训练样例,只要它将样例错误分类就修改权值,重复这个过程,重复这个过程,直到正确分类,每一步根据
感知器训练法则来修改权值,法则如下:
其中:
这里的 t 是当前训练样例的目标输出,o 是感知器的输出,
![]() 是一个正的常数称为学习速率,作用是缓和每一步调整权的程度,通常比较小,而且有时会使其随着权调整的次数增加而衰减。
是一个正的常数称为学习速率,作用是缓和每一步调整权的程度,通常比较小,而且有时会使其随着权调整的次数增加而衰减。
这个法则为什么能够成功收敛到正确的权值呢?
我们假设一下几种情况:
- 训练样本集已经被正确分类,这时,( t - o)是0,这使
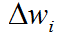 为0,权值没有修改;
为0,权值没有修改; - 当目标输出是1,但是感知器却输出-1,这个时候就要使感知器输出1,而不是-1了,所以权值修改后的
 要增大,如果xi > 0就要增大wi,这时因为(t - o)、x_i、
要增大,如果xi > 0就要增大wi,这时因为(t - o)、x_i、都>0 ,所以,wi是增大的,同理xi < 0时也会使
增大; - 当目标输出是-1,但是感知器却输出+1的原理同上一步。
上面能够收敛到正确分类的权向量,前提是训练样例线性可分,如果线性不可分,那么就不能保证训练过程收敛。
4.3 梯度下降和delta法则
对于线性不可分的样例,另一个训练法则可以克服这个不足,称为delta法则,对于线性不可分的样本,delta法则会收敛到目标概念的最佳近似。
delta法则的关键思想是使用
梯度下降来搜索可能的权向量的假设空间。最好把delta法则理解为一个无阈值的感知器,也就是一个线性单元,它输出如下:
这样,线性单元对应于感知器的第一阶段,不带阈值。
为了说明学到的权向量对于样例划分的正确性,我们需要定义一个标准来衡量,这个标准称作训练误差,一般的定义如下:

其中:D为训练样本集合,t_d为d的目标输出,o_d为线性单元对于样例d输出。
所以,对于越靠近目标概念的权向量,t_d 和 o_d 越接近,E(w)也会越小,这样寻找最优权向量可以转化到最小化 E 函数上来,E是一个关于W变量的函数。
E函数的可是化如下,取w_1、w_2,即W是二维向量,
![[Mitchell 机器学习读书笔记]——人工神经网络_第5张图片](http://img.e-com-net.com/image/info5/5c8a74721c994eaf995dde869473fd87.png)
对于线性可分样例集合来说,上面图一定有一个全局最小点。我们通过梯度下降搜索确定一个最小化E的权向量W,梯度下降从任意初始权向量开始,然后以很小的步伐反复修改这个向量,每一步都沿误差曲面产生最陡峭下降的方向修改权向量,直到得到全局最小误差点。
E相对于W的梯度,记作
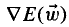
这样:

所以,梯度下降的训练法则是:
其中:
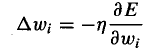
我们计算得到:

其中x_id表示训练样例d的一个输入分量x_i。结合以上几个式子,就可以得到梯度下降权值更新法则:
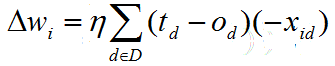
一个改进是随着迭代次数增加,减少
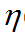 。
。
随机梯度下降:
因为上面的更新,需要计算所有实例的和然后更新权值,如果样例很多,计算过程会很慢。所以,一个常见的梯度下降变体(随机梯度下降)被提出了,大体上没有变化,只是根据以下公式来更新权值:

随机梯度下降可被看做为每个单独的训练样例d定义不同的误差函数:

标准的梯度下降和随机的梯度下降的关键区别:
- 标准的梯度下降是在权值更新前对所有的样例汇总误差,而随机梯度下降的权值是通过考查每个训练实例来更新的;
- 标准的梯度下降在每一步需要更多的计算,标准的梯度下降使用真正的梯度,对于每一次权值更新经常使用比随机梯度下降大的步长;
- 如果E有多个局部极小值,随机的梯度下降有可能避免陷入这些局部极小值中。
注意随机梯度下降和感知器训练法则的那个变化量表达式是一样的,考虑背后的原因?
感知器训练法则经过有限次的迭代,收敛到一个能理想分类训练数据的假设,但条件是样例线性可分。增量法则收敛到最小误差假设,可能需要极长的时间,但无论训练样例是否线性可分都会收敛。
5、多层网络和反向传播算法
![[Mitchell 机器学习读书笔记]——人工神经网络_第6张图片](http://img.e-com-net.com/image/info5/7efcf9f5a7844e7188fce7ec92fb810f.jpg)
因为单个感知器只能表示线性决策面,在前面感知器的基础上提出的反向传播的多层网络则可以表示数目繁多的函数、曲面。这里的反向传播主要的意思是层与层之间的反馈作用,前面一层会影响后一层的权向量取值。非线性曲面对于样例的划分比简单的线性划分更准确,如下图:
![[Mitchell 机器学习读书笔记]——人工神经网络_第7张图片](http://img.e-com-net.com/image/info5/58a08b18b9dd4ee997a021c801b4c432.png)
如果这里采用线性划分,不可能将样例划分出来。
实际应用中,基本上都是从多层网络来考虑设计算法。多层网络的每个单元就是类似于前面介绍过的感知器。因为多个线性函数的连接还是线性函数,而我们需要输出是输入的非线性函数,而且输出函数是可微的,一种称为sigma函数可以满足这个条件,这个函数类似于感知器,但它是基于一个平滑的可微阈值函数。下图表示了sigmoid单元:
![[Mitchell 机器学习读书笔记]——人工神经网络_第8张图片](http://img.e-com-net.com/image/info5/2a59593dd1e340318138f4c38c1d4908.png)
与感知器类似,sigmoid单元先计算它的输入的线性组合,然后应用到一个阈值到此结果。然而,对于sigmoid单元,阈值输出是输入的连续函数。sigmoid 计算输出的公式为:
其中:
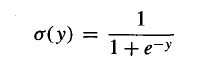
sigmoid函数就是我们平常看到的logistic函数。它的输出范围是0到1。当然,还有很多其它函数可以代替sigmoid函数,只要满足前面所说的非线性、可微条件即可。
对于多层网路来说,学习权向量的方法还是试图最小化网络输出值和目标值之间的误差平方,重新定义如下的误差平方和:

其中:outputs是网络输出单元的集合,t_kd和o_kd是与训练样例d和第k个输出单元的输出值。
在多层网络中,误差曲面可能有多个局部极小值,这意味着梯度下降仅能保证收敛到局部极小值,而未必得到全局最小的误差。但是,在实际中,发现对于很多应用反向传播算法都产生了出色的结果。
包含两层的sigmoid单元的反向传播算法如下:
![[Mitchell 机器学习读书笔记]——人工神经网络_第9张图片](http://img.e-com-net.com/image/info5/9c88ef85e1d84b338a2a5f80720ec34b.png)
6、小结
- 人工神经网络学习为学习实数值和向量值函数提供了一种实际的方法,对于连续的和离散的属性都可以使用,并且对训练数据中的噪声有很好的健壮性;
- 反向传播算法考虑的假设空间是固定连接的有权网络所能表示的所有函数的空间;
- 反向传播算法使用梯度下降方法搜索可能假设的空间,迭代减少网络的误差以拟合训练数据。
参考网址:
http://en.wikipedia.org/wiki/Artificial_neural_network
http://www.peltarion.com/doc/index.php?title=Applications_of_adaptive_systems
http://www.dkriesel.com/en/science/neural_networks
(
本文参考Mitchell的《机器学习》第四章,是为读书笔记)