Theano-Deep Learning Tutorials 笔记:Multilayer Perceptron
教程地址:http://www.deeplearning.net/tutorial/mlp.html
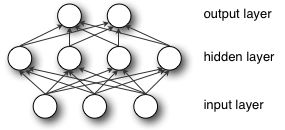
这节实现一个多层感知器,就3层,输入到隐藏层用非线性变换把输入映射到线性可分的空间,隐藏层到输入层其实是一个softmax(当最后一层的激活函数使用sigmoid函数时)。
1.The Model
,D是输入的维数,L是输出的维数。
s为hidden layer的激活函数,G为output layer的激活函数,激活函数选择可以是sigmoid和tanh,这里选的是tanh。
网络参数为 ,依然是使用Stochastic Gradient Descent with minibatches来训练,会用到神经网络训练的核心算法backpropagation
algorithm,在UFLDL教程中有详细介绍:http://deeplearning.stanford.edu/wiki/index.php/%E5%8F%8D%E5%90%91%E4%BC%A0%E5%AF%BC%E7%AE%97%E6%B3%95
2.Going from logistic regression to MLP
把隐藏层实现,再在后(上)面加一层之前实现的softmax层,就实现了3层感知器。
class HiddenLayer(object):
def __init__(self, rng, input, n_in, n_out, W=None, b=None,
activation=T.tanh):
"""
Typical hidden layer of a MLP: units are fully-connected and have
sigmoidal activation function. Weight matrix W is of shape (n_in,n_out)
and the bias vector b is of shape (n_out,).
NOTE : The nonlinearity used here is tanh
Hidden unit activation is given by: tanh(dot(input,W) + b)
:type rng: numpy.random.RandomState
:param rng: a random number generator used to initialize weights
:type input: theano.tensor.dmatrix
:param input: a symbolic tensor of shape (n_examples, n_in)
:type n_in: int
:param n_in: dimensionality of input
:type n_out: int
:param n_out: number of hidden units
:type activation: theano.Op or function
:param activation: Non linearity to be applied in the hidden
layer
"""
self.input = input
初始参数是通过均匀分布的随机采样得到:激活函数为tanh时,W从采样;激活函数是sigmoid时,从采样,其中是第 i-1 层神经元数量,是第 i 层神经元的数量。b初值为0。
这样初始化的作用:This initialization ensures that, early in training, each neuron operates in a regime of its activation function where information can easily be propagated both upward (activations flowing from inputs to outputs) and backward (gradients flowing from outputs to inputs).
训练神经网络时,初值其实很重要,好的初值可以更容易地收敛到更好的解,而不是被困在局部极值点。
# `W` is initialized with `W_values` which is uniformely sampled
# from sqrt(-6./(n_in+n_hidden)) and sqrt(6./(n_in+n_hidden))
# for tanh activation function
# the output of uniform if converted using asarray to dtype
# theano.config.floatX so that the code is runable on GPU
# Note : optimal initialization of weights is dependent on the
# activation function used (among other things).
# For example, results presented in [Xavier10] suggest that you
# should use 4 times larger initial weights for sigmoid
# compared to tanh
# We have no info for other function, so we use the same as
# tanh.
if W is None:
W_values = numpy.asarray(
rng.uniform(
low=-numpy.sqrt(6. / (n_in + n_out)),
high=numpy.sqrt(6. / (n_in + n_out)),
size=(n_in, n_out)
),
dtype=theano.config.floatX
)
if activation == theano.tensor.nnet.sigmoid:
W_values *= 4
W = theano.shared(value=W_values, name='W', borrow=True)
if b is None:
b_values = numpy.zeros((n_out,), dtype=theano.config.floatX)
b = theano.shared(value=b_values, name='b', borrow=True)
self.W = W
self.b = b
activation function默认为tanh,计算隐藏层输出:
lin_output = T.dot(input, self.W) + self.b
self.output = (
lin_output if activation is None
else activation(lin_output)
)
如前面所说,多层感知器可以分成一个隐藏层后面加上一个softmax层(之前Classifying MNIST digits using Logistic Regression已经实现过):
class MLP(object):
"""Multi-Layer Perceptron Class
A multilayer perceptron is a feedforward artificial neural network model
that has one layer or more of hidden units and nonlinear activations.
Intermediate layers usually have as activation function tanh or the
sigmoid function (defined here by a ``HiddenLayer`` class) while the
top layer is a softmax layer (defined here by a ``LogisticRegression``
class).
"""
def __init__(self, rng, input, n_in, n_hidden, n_out):
"""Initialize the parameters for the multilayer perceptron
:type rng: numpy.random.RandomState
:param rng: a random number generator used to initialize weights
:type input: theano.tensor.TensorType
:param input: symbolic variable that describes the input of the
architecture (one minibatch)
:type n_in: int
:param n_in: number of input units, the dimension of the space in
which the datapoints lie
:type n_hidden: int
:param n_hidden: number of hidden units
:type n_out: int
:param n_out: number of output units, the dimension of the space in
which the labels lie
"""
# Since we are dealing with a one hidden layer MLP, this will translate
# into a HiddenLayer with a tanh activation function connected to the
# LogisticRegression layer; the activation function can be replaced by
# sigmoid or any other nonlinear function
self.hiddenLayer = HiddenLayer(
rng=rng,
input=input,
n_in=n_in,
n_out=n_hidden,
activation=T.tanh
)
# The logistic regression layer gets as input the hidden units
# of the hidden layer
self.logRegressionLayer = LogisticRegression(
input=self.hiddenLayer.output,
n_in=n_hidden,
n_out=n_out
)
为防止过拟合等原因,加上参数正则化项,L1 and L2 regularization:
# L1 norm ; one regularization option is to enforce L1 norm to
# be small
self.L1 = (
abs(self.hiddenLayer.W).sum()
+ abs(self.logRegressionLayer.W).sum()
)
# square of L2 norm ; one regularization option is to enforce
# square of L2 norm to be small
self.L2_sqr = (
(self.hiddenLayer.W ** 2).sum()
+ (self.logRegressionLayer.W ** 2).sum()
)
# negative log likelihood of the MLP is given by the negative
# log likelihood of the output of the model, computed in the
# logistic regression layer
self.negative_log_likelihood = (
self.logRegressionLayer.negative_log_likelihood
)
# same holds for the function computing the number of errors
self.errors = self.logRegressionLayer.errors
# the parameters of the model are the parameters of the two layer it is
# made out of
self.params = self.hiddenLayer.params + self.logRegressionLayer.params
关注下 self.params,定义在class LogisticRegression(object):中,self.params = [self.W, self.b]。
训练依然是stochastic gradient descent with mini-batches。损失函数中加入了L1,L2正则化项,L1_reg and L2_reg 觉得正则化项所占权重。
# the cost we minimize during training is the negative log likelihood of
# the model plus the regularization terms (L1 and L2); cost is expressed
# here symbolically
cost = (
classifier.negative_log_likelihood(y)
+ L1_reg * classifier.L1
+ L2_reg * classifier.L2_sqr
)
训练过程的代码与上一节基本一样,就参数数目不一样,Theano又直接用自己的黑科技直接求导了,这里没有体现出反向传播算法,所以用Theano写网络还是没有用matlab一点一点写更能体会细节。
# compute the gradient of cost with respect to theta (sotred in params)
# the resulting gradients will be stored in a list gparams
gparams = [T.grad(cost, param) for param in classifier.params]
# specify how to update the parameters of the model as a list of
# (variable, update expression) pairs
# given two lists of the same length, A = [a1, a2, a3, a4] and
# B = [b1, b2, b3, b4], zip generates a list C of same size, where each
# element is a pair formed from the two lists :
# C = [(a1, b1), (a2, b2), (a3, b3), (a4, b4)]
updates = [
(param, param - learning_rate * gparam)
for param, gparam in zip(classifier.params, gparams)
]
# compiling a Theano function `train_model` that returns the cost, but
# in the same time updates the parameter of the model based on the rules
# defined in `updates`
train_model = theano.function(
inputs=[index],
outputs=cost,
updates=updates,
givens={
x: train_set_x[index * batch_size: (index + 1) * batch_size],
y: train_set_y[index * batch_size: (index + 1) * batch_size]
}
)
3.Tips and Tricks for training MLPs
There are several hyper-parameters in the above code, which are not (and, generally speaking, cannot be) optimized by gradient descent. Strictly speaking, finding an optimal set of values for these hyper-parameters is not a feasible problem.
First, we can’t simply optimize each of them independently.
Second, we cannot readily apply gradient techniques that we described previously (partly because some parameters are discrete values and others are real-valued). T
hird, the optimization problem is not convex and finding a (local) minimum would involve a non-trivial amount of work.
A very good overview of these tricks can be found in Efficient BackProp
Nonlinearity
非线性激活函数一般选用sigmoid和tanh函数,函数最好是关于原点对称,这是因为:they tend to produce zero-mean inputs to the next layer (which is a desirable property).
根据经验, 收敛性更好。
Weight initialization
At initialization we want the weights to be small enough around the origin so that the activation function operates in its linear regime, where gradients are the largest.
Other desirable properties, especially for deep networks, are to conserve variance of the activation as well as variance of back-propagated gradients from layer to layer. This allows information to flow well upward and downward in the network and reduces discrepancies(差异) between layers.
for tanh and ![]() for sigmoid.(在前文2中介绍过)
for sigmoid.(在前文2中介绍过)
Learning rate
(1)固定学习率:Rule of thumb: try several log-spaced values () and narrow the (logarithmic) grid search to the region where you obtain the lowest validation error.
(2)随时间(迭代次数)减小的学习率:One simple rule for doing that is ,![]() 是初始值(可以用(1)中方法选取),决定学习率的衰减率(typically, a smaller positive number, and smaller),是迭代次数。
是初始值(可以用(1)中方法选取),决定学习率的衰减率(typically, a smaller positive number, and smaller),是迭代次数。
Number of hidden units
hyper-parameter取什么值和数据集的关系很大,输入数据的分布越复杂,网络就该越复杂,神经元就该越多。
Regularization parameter
一般这样取值:L1/L2 regularization parameter are ![]() ,这两个参数的优化对性能提高不是特别显著。
,这两个参数的优化对性能提高不是特别显著。