《算法图解》第四章——快速排序
书中言:快速排序使用分而治之的策略,是一种优雅的排序算法。深以为然~
第四章:1.介绍了分而治之的思想;2.介绍与解释了快速排序;3.填了大O表示法的坑
- 分而治之
分而治之:一种著名的递归式问题解决方法。
讲述三个例子来引入该思想。1.农场主分割田,要求将地皮均匀地分成方块,且分出的方块尽可能大;2.求一个数字数组的元素之和;3.男猪脚:快速排序
-
找出基线条件,条件必须尽可能简单
-
不断将问题分解或者缩小规模,直到符合基线条件
分田的例子中,将一条边是另一条边的整数倍作为基线条件,递归条件为最小边是所切割的最大正方形边。具体看书很容易明白。
第二个例子相当于用递归的思想写出求和公式sum。作者是如何思考的,先找基线条件,他以经验告诉我们,一般数组类的问题,其基线条件都为数组为空或者为只包含一个元素。见下图:
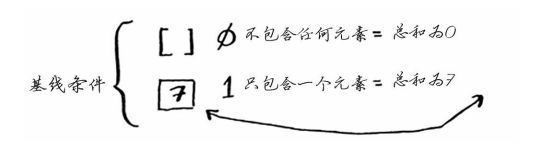
如何找递归条件不断把问题循环下去,把问题慢慢分解呢?我们想到达到基线条件时数组最多为一个元素,那上一轮递归中呢?那得至少是两个元素吧,姑且算作两个,那再上一轮至少得是3个......我们想到了,每次递归我都摘出来一个数,也就是取出一个数,那么让其他数组去进行下面的递归。摘出来的那个数一般取第一个幸运儿[0]。

整个函数运行过程,题为计算数组或者列表[2,4,6]的和:

下面是书中分而治之的几个练习题代码:
#用递归写求和公式
def func(a):
if len(a) == 0: #基线条件
return 0 #返回数字0
return a[0] + func(a[1:])# 递归条件 a[1:]第2个元素排列到最后一个元素
a=[1,2,3]
print(func(a))
# 6
#递归写一个 计算列表包含的元素数
def func(a):
if a == []: #基线条件
return 0
return 1 + func(a[1:]) #递归条件
a = [1,2,3]
print(func(a))
# 3
#递归:找出列表最大数字
#下列代码使用了列表推导式
def Max(list):
if len(list) == 2:
return list[0] if list[0]>list[1] else list[1] #基线条件:只剩两个,比大小就行
snb_max = Max(list[1:])
return list[0] if list[0]>snb_max else snb_max
list = [2,3,4,5]
print(Max(list))
- 快速排序
还是一组数组,既然是数组那么,上述D&C讨论的基线条件也应该成立:当数组为空或者只有一个元素。然后件问题缩小,有了前文的铺垫,摘出一个元素作为基准值,当然他可以是任意一个元素,我们默认第一个或者最后一个,此处记一个伏笔*,此为递归条件。好了下面,才是快速排序的精髓:
1.选出基准值
2.将数组分成两个子数组:小于基准值的a和大于基准值的b
3.对剩下来的两个数组a,b进行快速排序
快速排序的要点就是:找基准,分数组,小数组左边站,大数组右边站,如此往复最终完成排序。就是这么简单!
#采用了列表推导式
def func(list):
if len(list) < 2: #基线条件
return list
per = list[0]
low =[ i for i in list[1:] if i<=per ]
greater =[i for i in list[1:] if i > per]
return func(low) + [per] +func(greater)
#上述等价,列表推导式简洁啊,python的精髓
def func(list):
if len(list) < 2:
return list
else:
per = list[0]
low, great = [],[]
for i in list[1:]:
if i <= per :
low.append(i)
else:
great.append(i)
return func(low) + [per] + func(great)
list = [2,1,4,5]
print(func(list))
- 再谈大O表示法
这部分,也参考了算法导论里面的知识与其他博主。这部分书中总结下来有两个部分:
1.细究大O里面的o(n)
2.平均情况与最糟糕情况
1:
引一条经验规则:c < log2N < n < n * Log2N < n^2 < n^3 < 2^n < 3^n < n!
其中c是一个常量,如果一个算法的复杂度为c 、 log2N 、n 、 n*log2N ,那么这个算法时间效率比较高 ,如果是 2^n , 3^n ,n!,那么稍微大一些的n就会令这个算法不能动了,居于中间的几个则差强人意。
书中举了例子,选择排序运行时间O(n^2),有一种叫合并排序的算法运行时间总是O( n * Log2N),根据规则合并排序要比起选择要快;本章谈到的快速排序平均时间O( n * Log2N),最糟时间O( n^2),这里把疑问带到第二部分。
之后书中写了两个函数,都是让其遍历一个列表的元素并打印他们,唯一区别的是第二个函数在打印每个元素之前都会休眠1s。两者算法一样,看样子运行速度应该是一样的,作者给出了答案:前者没有休眠的更快。给出了O(n)中的n=c*n,c指的是算法所需的固定时间,被称为常量。聪明的你根据前面的经验规则可以知道,这个常量c对同样的算法复杂度影响比较大,如两个函数第一个c为10ms,第二个c为1s,所以前者速度快些。对于不是同一量级复杂度的,书中以简单查找和二分查找作对比,c的作用简直不值一提。
本小节就说了两个事:同一算法复杂度才谈常量c;不是同一复杂度看经验表排序。
2.
前文有两个坑,没填上。一个*和平均,最糟复杂度。
第二部分讲的就是这个内容。本节书中引快速排序的例子,快速排序有平均与最糟时间。分别是什么呢?先给我们看了最糟糕排序时间。

如图,每次都选取第一个元素为基准值,每次快速排序确实也分成了两个数组,其中有一个数组每次都为空。如此往复,栈的高度达到了8,也可也说选取第一个元素为基准值进行排序,总共有八层 ,最后达到基线条件完成排序。这是最糟情况,栈长为O(n)
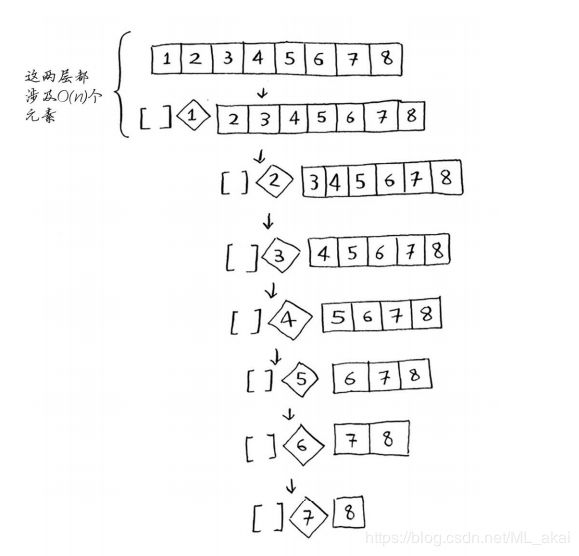
这种情况调用栈的每一层都遍历了所有元素,操作时间O(n)。因此最糟糕情况的时间复杂度就有了简单的表达:O=O(n)*O(n)=n^2
接着就是理想最优情况:

基准值每次取中间,栈的高度为4,即层数为4。调用栈少了一半,栈高O(log2n),而每一层他也都是遍历了所有元素,对所有元素操作时间也为O(n)。那么该平均情况时间复杂度:O=O(log2n)*O(n)=O(n*log2n)
最优的时间复杂度其实也就是平均复杂度时间,当你每次随机取基准值的时候,他的复杂度也就是平均复杂度了。(最糟糕复杂度有两个特定条件:1.有序;2.取首或尾元素。其实就两种情况)
- 本章书中小结
1.D&C将问题逐步分解。使用D&C处理列表时,基线条件很可能是空数组或只包含一个元素的数组。
2.实现快速排序时,请随机地选择用作基准值的元素。快速排序的平均运行时间为O(n log n)。
3.大O表示法中的常量有时候事关重大,这就是快速排序比合并排序快的原因所在。
4. 比较简单查找和二分查找时,常量几乎无关紧要,因为列表很长时,O(log n)的速度比O(n)快得多。
如有错误,欢迎指正!