Flink学习1-基础概念
Flink学习1-基础概念
系列文章目录
- Flink系列1-基础概念
- Flink系列2-安装和启动
- Flink系列3-API介绍
摘要
本文是作者学习Flink的一些文档整理、记录和心得体会,希望与大家共同学习探讨。
0x01 Flink简介
1.1 概念
Apache Flink是一个开源的分布式流式处理框架,高性能、高可用,他有强大的流式和批处理能力,通过语义保证数据处理精确性。流式处理方面,Flink能对有界、无界数据流做有状态的计算(stateful computations)。
1.2 特点
他有如下特点:
- 能同时支持高吞吐和低事件(亚秒级)延迟
- 基于数据流模型,支持DataStream API中的
event time和无序处理 - 优雅的Java和Scala API
- 跨不同时间语义(
event time,processing time)的弹性window(时间,计数,会话,自定义触发器) - 支持状态,Flink托管
- 具有Exactly Once处理保证的容错能力
- 支持window,如session, Tumbling, sliding window
- 流式程序中自然背压
- 批处理的lib包可支持图运算和机器学习;流式处理的lib支持复杂事件处理
- 内置支持DataSet(批处理)API中的迭代程序(BSP)
- 自定义内存管理,可在内存和核外数据处理算法之间实现高效,可靠的切换
- 可兼容Apache Hadoop MapReduce和Apache Storm
- 可集成YARN,HDFS,HBase和Apache Hadoop生态系统的其他组件
1.3 示例
1.3.1 流处理
下面这个例子展示了用scala语言写的一段对5秒时间窗口内的数据进行流式word count的流处理程序:
case class WordWithCount(word: String, count: Long)
val text = env.socketTextStream(host, port, '\n')
val windowCounts = text.flatMap { w => w.split("\\s") }
.map { w => WordWithCount(w, 1) }
.keyBy("word")
.timeWindow(Time.seconds(5))
.sum("count")
windowCounts.print()
1.3.2 批处理
下面这个例子展示了用scala语言写的对数据进行word count批处理程序:
case class WordWithCount(word: String, count: Long)
val text = env.readTextFile(path)
val counts = text.flatMap { w => w.split("\\s") }
.map { w => WordWithCount(w, 1) }
.groupBy("word")
.sum("count")
counts.writeAsCsv(outputPath)
1.4 Flink对比其他
- Storm
开发API较复杂,不支持状态托管, 用户必须自己处理状态持久化和一致性保证,如果某个挂了状态很难恢复 - JStorm
- 阿里巴巴fork,现在开始采用 flink的思想
- Spark Streaming
微批,非真正的实时流式处理 - Structured Streaming
同样是纯实时思想
0x02 Flink架构
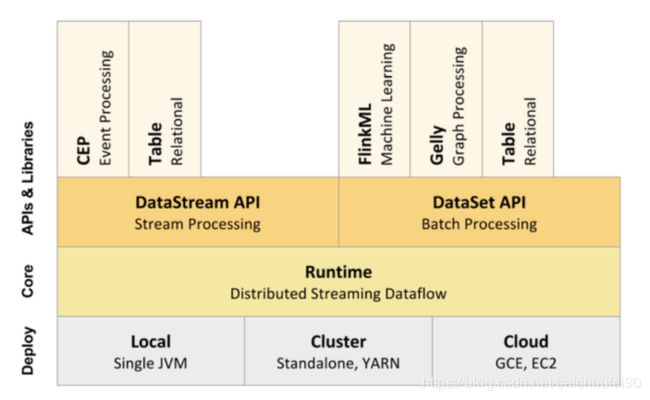
2.1 部署方式
- Local
单JVM,本地调试 - Cluster-Standalone
Flinke Standalone模式,不依赖其他资源 - Cluster-Yarn
最常用的模式,依赖Yarn - Cloud
0x03 Flink设计理念
3.1 处理无界和有界的数据
任何类型的数据都是作为事件流产生的,如信用卡交易、传感器数据、机器日志以及社交网站或者手机上的用户交互信息。数据可以分为无界和有界的。
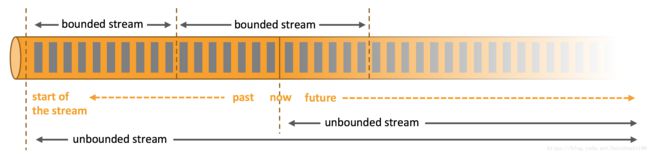
3.1.1 无界数据
无界数据有开端但没有定义结束。也就是说无界数据会源源不断的被生产,必须持续进行处理。处理无界数据通常要求以特定顺序(例如事件发生的顺序)摄取事件,以便能够推断出结果的完整性。
Flink通过时间和状态的精准控制能够在无界流上运行任何类型的应用程序。
3.1.2 有界数据
有界数据有明确的开始和结束。可以在处理计算有界数据前先摄取到所有数据。与无界数据不同,处理有界流不需要有序地摄取,因为可以始终对有界数据集进行排序。 有界流的处理也称为批处理。
Flink通过算法和数据结构来对有界流进行内部处理,这些算法和数据结构专门针对固定大小的数据集而设计,从而产生出色的性能。
3.2 Flink部署方式灵活
和Spark一样,Flink既能以StandAlone方式部署,又可以跑在YARN Mesos Kubernetes等资源调度器上。
Flink在这些RM上运行时,关于提交和控制一个Application的所有通讯手段都是REST请求。
Flink可以根据应用配置的并行性来识别出所需的资源并向RM申请。为了预防任务失败,Flink会在container失败时重新申请新的资源。
3.3 Flink可运行任意规模的应用
Flink被设计来可以高效地运行任意规模的有状态的流式应用。应用程序可以并行拆分为数千个任务分布在集群中,同时执行。理论上来讲应用可以用到无限的资源。而且,Flink可以轻松维护非常大的应用程序状态。 Flink异步、增量的检查点(checkpoint)算法可以确保对处理延迟的影响最小化,同时能保证精确一次性(exactly once)的状态一致性。
目前Flink应用广泛,很多公司使用它来处理巨大规模的应用,如:
- 处理万亿事件/天的应用
- 处理多个TB级的状态信息的应用
- 运行在数千个核上的应用
3.4 利用内存达到极致性能
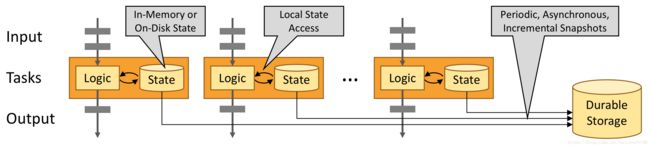
有状态的Flink应用程序针对本地状态访问进行了特别优化。任务状态信息始终保存在内存中或是在状态信息超过可用内存时存在在高效的位于磁盘的数据结构中。这样设计使得任务计算通常都是在内存中进行,延迟非常低。
前面说到过,Flink能保证就算出现故障时也拥有精准一次的状态一致性。Flink的处理方式是周期性异步的检查点来将本地状态持久化到存储。
0x04 Flink重要概念
在Flink流式处理框架中,有几个很重要的概念即streams,state,time。 下面我们解释下这几个基本概念,并会分析Flink怎么运用他们。
4.1 Streams
Stream流,就是流式处理中的基本概念。虽然流数据分为各种不同特征的类型,但是Flink可以巧妙高效的进行处理:
4.1.1 有界流和无界流
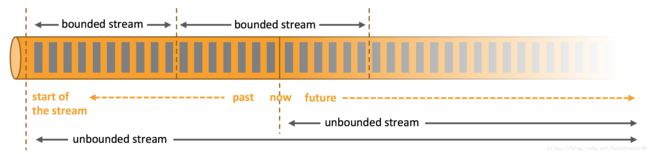
Flink的设计哲学最擅长于处理无界数据,但是对于有界数据也提供了高效的操作方式。
4.1.2 实时流和记录型流
一般来说处理这类流数据的方式有两种:
- 数据一旦生成就立刻实时处理
- 先将流数据持久化到存储系统(如文件系统等),稍后再处理它们。
4.2 State
每个有价值的流式应用一般都是有状态的。Flink中的状态是指中间状态,如算子的状态。该状态托管到Flink系统内部。对应无状态的就比如函数,输入到输出无状态。
Flink状态如下:
- Operator State
算子状态,一般存于内存 - Keyed State
根据状态的backend决定存储位置 - State Backend (rocksdb + hdfs)
rocksdb是本地的,再异步到HDFS
运行基本业务逻辑的任何应用程序都需要记下事件或中间结果,以便在以后的时间点访问它们:例如在收到下一个事件时或在特定持续时间之后。
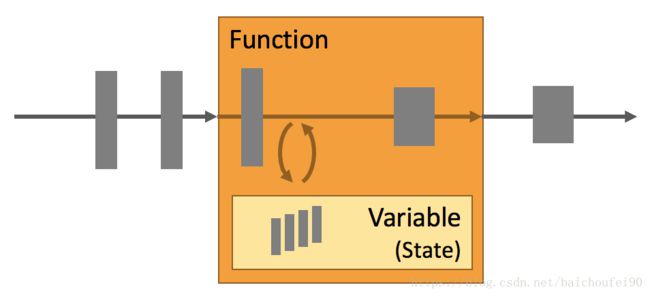
应用程序的State(状态)是很重要的一个概念,Flink中有很多feature来处理状态。
- 多种多样的状态元语:Flink有多种数据结构来提供状态原语,例如原子值,列表或映射,我们可以根据这个function访问方式来选择合适的状态元语类型
- 可插拔的状态后端:应用的状态是由一个可插拔的状态后端服务管理和设置检查点的,我们可以选择用内存或
RocksDB(一个高效的嵌入式磁盘数据存储)甚至是自定义的状态后端插件来存储应用状态 - 精准一次的状态一致性:Flink的检查点和恢复算法可以保证在失败时应用状态的一致性。所以,这些失败对应用来说是透明的,不会影响正确性
- 巨大的状态信息维护:Flink通过异步和增量检查点算法可维护TB级别的应用状态
- 可扩展的应用:Flink通过对应用弹性分配worker数量来实现应用可扩展
4.3 Time
4.3.1 概述
Time是流式应用状态中的一个重要概念。
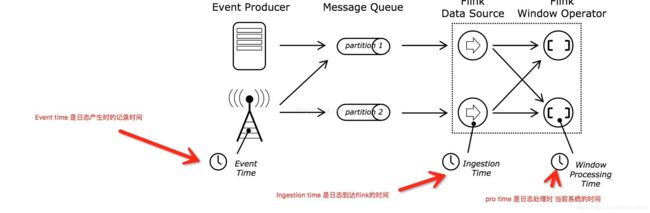
大多流式数据本身就有时间语义,因为每个事件都是在特定的时间点上产生的。而且通常流式计算是以时间为基础的。在流式处理中很重要的方面是应用程序如何去测量时间即event-time 和processing-time的差别
4.3.2 EventTime
处理具有事件时间语义的流的应用程序,是基于事件的时间戳来计算结果。 因此,无论是处理记录型还是实时的流事件,通过event-time处理都会得到准确和一致的结果。
说白了,EventTime是事件在现实世界中发生的时间
当选择event-time模式时有两个重要概念:
- 水位:Flink使用水位来推断
event-time应用中的时间。此外,水位也是一种灵活的机制,可以在结果的延迟和完整性间做出权衡。 - 延迟数据处理:当使用水位在
event-time模式下处理流时,可能发生在所有相关事件到达之前就已完成了计算,这类事件称为延迟事件。 Flink具有多种处理延迟事件的选项,如重新路由它们以及更新此前已经完成的结果。
4.3.3 IngestionTime
数据到达Flink系统时间。
4.3.4 ProcessingTime
除event time模式外,Flink还支持Processing-time语义,该语义执行由处理机器的时钟时间来触发的计算。 该模式适用于具有严格的低延迟要求的应用,但也必须容忍并不精确、近似的结果。
说白了,ProcessingTime是Flink系统真正开始处理该事件的时间。
4.4 窗口
4.4.1 概述
大体来说 ,Flink的窗口分为两类:
- Count Window
- Time Window

Flink的窗口又能细分为: - 翻滚窗口(Tumbling Window,无重叠)
- 滑动窗口(Sliding Window,有重叠)
- 会话窗口(Session Window,活动间隙)
而滑动窗口与滚动窗口的最大区别就是滑动窗口有重复的计算部分。
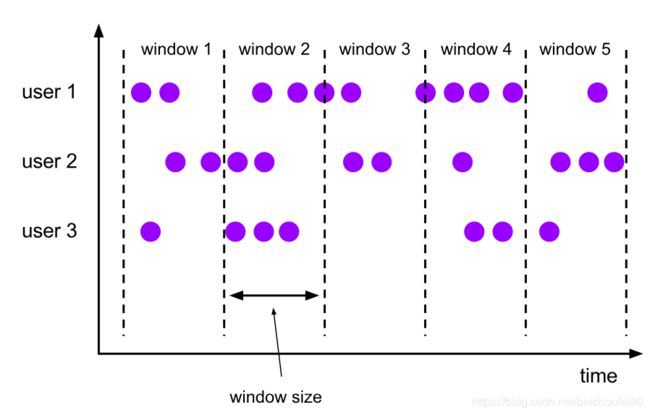
4.4.2 Tumbling Window-滚动窗口
- 滚动窗口分配器将每个元素分配给固定大小的窗口
- 每个窗口无重叠部分。
- 窗口大小可按Time或Event Count
- 如果滚动窗口的大小指定为5分钟,则将每五分钟启动一个新窗口,如下图所示:
4.4.3 Sliding Window-滑动窗口
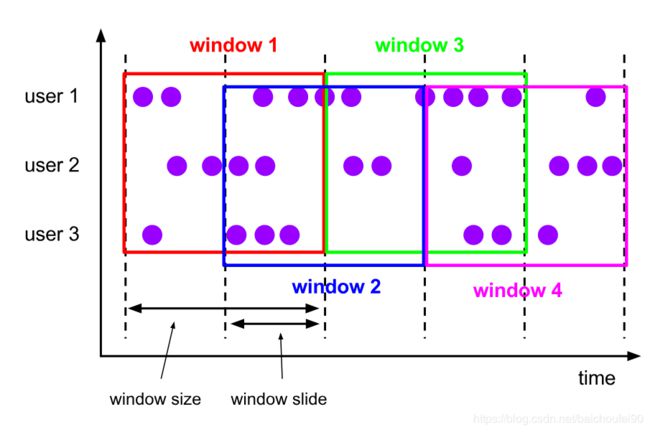
- 滑动窗口分配器将所有元素分配给固定大小的窗口。
- 滑动窗口有两个参数:
- 窗口大小
- 滑动间隔(步长)
- 有重叠
因此,如果滑动间隔小于窗口大小,那么滑动窗口会有重叠部分。此时,元素会被分配到多个窗口。 - 窗口大小可按Time或Event Count
- 适合求最近时间的统计,比如BI常用这种模式窗口
例如,滑动窗口两个参数为(10分钟,5分钟)。这样,每5分钟会生成(滑动)一个窗口,包含生成时往前推10分钟内到达的事件,每次有5分钟时间内的数据重叠,如下图所示。
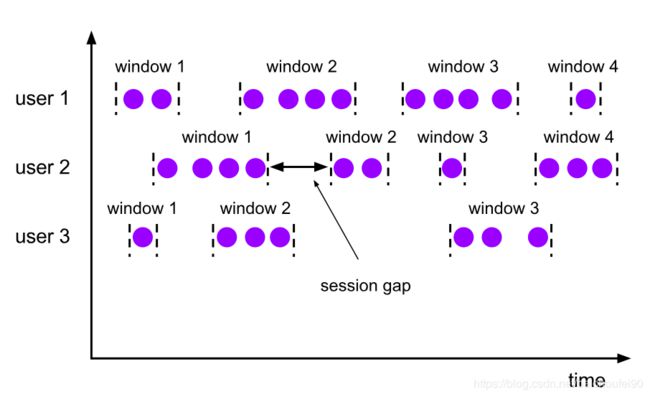
4.4.4 Session Window-会话窗口
- Session Window分配器通过activity session来对事件进行分组。
- 无时间窗口大小对齐
- 无重叠
与滚动窗口和滑动窗口相比,会话窗口不会重叠,也没有固定的开始和结束时间。相反,当会话窗口在一段时间内没有接收到元素时会关闭,例如,不活动的间隙时。 - Gap可配
会话窗口分配器配置会话间隙,定义所需的不活动时间长度(defines how long is the required period of inactivity)。当此时间段到期时,当前会话关闭,后续元素被分配到新的会话窗口。 - 适合线上用户行为分析
4.5 Watermarker-水位
标记水位以下的数据已经到齐了。
- Flink流计算编程–watermark(水位线)简介
- 流式计算-low watermark机制
4.6 触发器
4.7 转换
4.8 语义
- At-Most-Once
- At-Least-Once
- At-Exactly-Once
0xFE 总结
本章主要介绍了Flink的一些基本概念,下一章讲Flink的下载、安装和启动,请点击Flink系列2-安装和启动
0xFF 参考文档
1 好文推荐
- Apache Flink
- Flink在唯品会的实践应用
- 大数据处理引擎 Apache Flink 全梳理
- Flink架构、原理与部署测试
- Apache Flink - 架构和拓扑
- Flink原理及架构
2 参考文档
Apache Flink