【Keras-ResNet】CIFAR-10
系列连载目录
- 请查看博客 《Paper》 4.1 小节 【Keras】Classification in CIFAR-10 系列连载
学习借鉴
- github:BIGBALLON/cifar-10-cnn
- 知乎专栏:写给妹子的深度学习教程
- resnet caffe model:https://github.com/soeaver/caffe-model
参考
- 给妹纸的深度学习教学(4)——同Residual玩耍
- 《Deep Residual Learning for Image Recognition》
- 《Identity Mappings in Deep Residual Networks》
- 本地远程访问Ubuntu16.04.3服务器上的TensorBoard
代码
- 链接:https://pan.baidu.com/s/1JApBTf5oV4jIA3sV71vYfw
提取码:5v7l
硬件
- TITAN XP
文章目录
- 1 ResNet
- 2 resnet_32
- 2.1 my_resnet_32
- 2.2 resnet_32(resnet_32_e)
- 2.3 my_resnet_34
- 2.4 resnet_32_a/b/c/d/e
- 2.4.1 resnet_32_a
- 2.4.2 resnet_32_b
- 2.4.3 resnet_32_c
- 2.4.4 resnet_32_d
- 2.5 resnet32_d/e-v2
- 3 resnet_50 / 101 / 152
- 4 总结
- 5 附录
1 ResNet
简单的堆叠网络,越深效果反而变差了,恺明 大神提出了学残差

图片来源给妹纸的深度学习教学(4)——同Residual玩耍
- 学residual 比学映射更简单
- 更容易 optimize

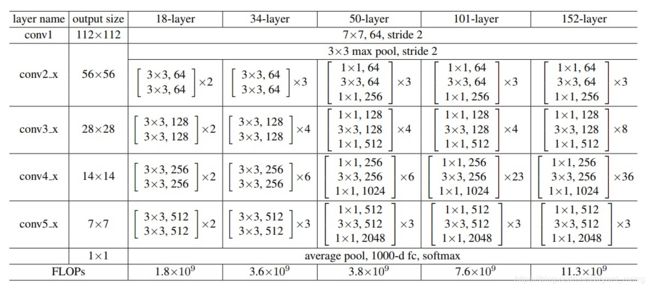
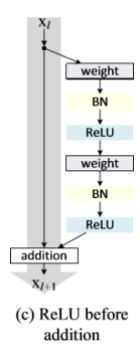
《Deep Residual Learning for Image Recognition》中大于50层的采用了右边的结构,层数比较少的时候,采用的左边的结构,他们的参数量是一样的。
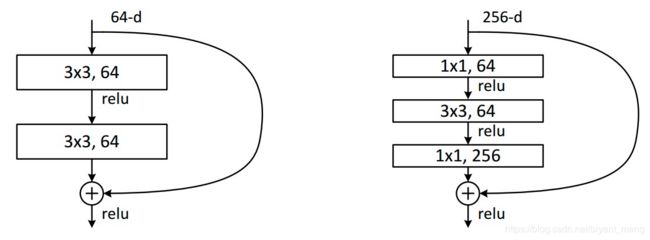
64 ∗ 3 ∗ 3 ∗ 64 + 64 ∗ 3 ∗ 3 ∗ 64 = 73728 64*3*3*64+64*3*3*64=73728 64∗3∗3∗64+64∗3∗3∗64=73728
64 ∗ 1 ∗ 1 ∗ 64 + 64 ∗ 3 ∗ 3 ∗ 64 + 64 ∗ 1 ∗ 1 ∗ 256 + 64 ∗ 1 ∗ 1 ∗ 256 = 73728 64*1*1*64+64*3*3*64+64*1*1*256 + 64*1*1*256= 73728 64∗1∗1∗64+64∗3∗3∗64+64∗1∗1∗256+64∗1∗1∗256=73728
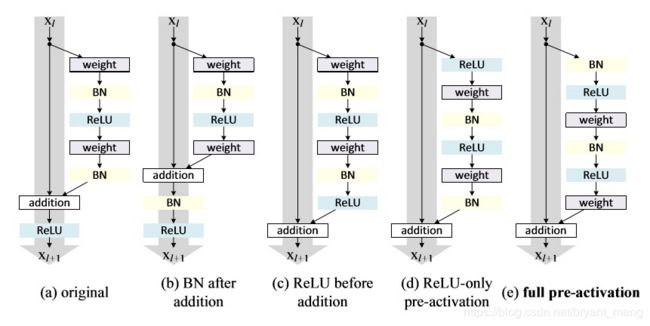
《Identity Mappings in Deep Residual Networks》 中对其结构进行了进一步分析与探讨,篇幅有限,不太深入的描写论文的细节。
我们先实现一个(e)版本的结构
2 resnet_32
2.1 my_resnet_32
1)导入库,设置 hyper parameters
import keras
import numpy as np
from keras.datasets import cifar10, cifar100
from keras.preprocessing.image import ImageDataGenerator
from keras.layers.normalization import BatchNormalization
from keras.layers import Conv2D, Dense, Input, add, Activation, GlobalAveragePooling2D
from keras.callbacks import LearningRateScheduler, TensorBoard
from keras.models import Model
from keras import optimizers, regularizers
from keras import backend as K
stack_n = 5
layers = 6 * stack_n + 2
num_classes = 10
batch_size = 128
epochs = 200
iterations = 50000 // batch_size + 1
weight_decay = 1e-4
log_filepath = './my_resnet_32/'
2)数据预处理,training schedule 设置
def color_preprocessing(x_train,x_test):
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
mean = [125.307, 122.95, 113.865]
std = [62.9932, 62.0887, 66.7048]
for i in range(3):
x_train[:,:,:,i] = (x_train[:,:,:,i] - mean[i]) / std[i]
x_test[:,:,:,i] = (x_test[:,:,:,i] - mean[i]) / std[i]
return x_train, x_test
def scheduler(epoch):
if epoch < 81:
return 0.1
if epoch < 122:
return 0.01
return 0.001
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
y_train = keras.utils.to_categorical(y_train, 10) # number of classes
y_test = keras.utils.to_categorical(y_test,10)# number of classes
# color preprocessing
x_train, x_test = color_preprocessing(x_train, x_test)
3)搭建 resnet_32 网络
通过 strides 来减小图片的分辨率,而不是 pooling

32层由 卷积层+15个residual block +fc 构成,每个residual block 中有2个卷积层
- residual block 1-5:上图左边结构
- residual block 6:上图中间结构
- residual block 7-10:上图左边结构
- residual block 11:上图中间结构
- residual block 12-15:上图左边结构
def res_32(img_input):
# input: 32x32x3 output: 32x32x16
x = Conv2D(16, (3, 3), strides=(1,1),padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay),
kernel_initializer="he_normal")(img_input)
# res_block1 to res_block5 input: 32x32x16 output: 32x32x16
for _ in range(5):
b0 = BatchNormalization(momentum=0.9, epsilon=1e-5)(x)
a0 = Activation('relu')(b0)
conv_1 = Conv2D(16,kernel_size=(3,3),strides=(1,1),padding='same',kernel_regularizer=regularizers.l2(weight_decay),
kernel_initializer="he_normal")(a0)
b1 = BatchNormalization(momentum=0.9, epsilon=1e-5)(conv_1)
a1 = Activation('relu')(b1)
conv_2 = Conv2D(16,kernel_size=(3,3),strides=(1,1),padding='same',kernel_regularizer=regularizers.l2(weight_decay),
kernel_initializer="he_normal")(a1)
x = add([x,conv_2])
# res_block6 input: 32x32x16 output: 16x16x32
b0 = BatchNormalization(momentum=0.9, epsilon=1e-5)(x)
a0 = Activation('relu')(b0)
conv_1 = Conv2D(32,kernel_size=(3,3),strides=(2,2),padding='same',kernel_regularizer=regularizers.l2(weight_decay),
kernel_initializer="he_normal")(a0)
b1 = BatchNormalization(momentum=0.9, epsilon=1e-5)(conv_1)
a1 = Activation('relu')(b1)
conv_2 = Conv2D(32,kernel_size=(3,3),strides=(1,1),padding='same',kernel_regularizer=regularizers.l2(weight_decay),
kernel_initializer="he_normal")(a1)
projection = Conv2D(32,kernel_size=(1,1),strides=(2,2),padding='same', kernel_regularizer=regularizers.l2(weight_decay),
kernel_initializer="he_normal")(a0)
x = add([projection,conv_2])
# res_block7 to res_block10 input: 16x16x32 output: 16x16x32
for _ in range(1,5):
b0 = BatchNormalization(momentum=0.9, epsilon=1e-5)(x)
a0 = Activation('relu')(b0)
conv_1 = Conv2D(32,kernel_size=(3,3),strides=(1,1),padding='same',kernel_regularizer=regularizers.l2(weight_decay),
kernel_initializer="he_normal")(a0)
b1 = BatchNormalization(momentum=0.9, epsilon=1e-5)(conv_1)
a1 = Activation('relu')(b1)
conv_2 = Conv2D(32,kernel_size=(3,3),strides=(1,1),padding='same',kernel_regularizer=regularizers.l2(weight_decay),
kernel_initializer="he_normal")(a1)
x = add([x,conv_2])
# res_block11 input: 16x16x32 output: 8x8x64
b0 = BatchNormalization(momentum=0.9, epsilon=1e-5)(x)
a0 = Activation('relu')(b0)
conv_1 = Conv2D(64,kernel_size=(3,3),strides=(2,2),padding='same',kernel_regularizer=regularizers.l2(weight_decay),
kernel_initializer="he_normal")(a0)
b1 = BatchNormalization(momentum=0.9, epsilon=1e-5)(conv_1)
a1 = Activation('relu')(b1)
conv_2 = Conv2D(64,kernel_size=(3,3),strides=(1,1),padding='same',kernel_regularizer=regularizers.l2(weight_decay),
kernel_initializer="he_normal")(a1)
projection = Conv2D(64,kernel_size=(1,1),strides=(2,2),padding='same', kernel_regularizer=regularizers.l2(weight_decay),
kernel_initializer="he_normal")(a0)
x = add([projection,conv_2])
# res_block12 to res_block15 input: 8x8x64 output: 8x8x64
for _ in range(1,5):
b0 = BatchNormalization(momentum=0.9, epsilon=1e-5)(x)
a0 = Activation('relu')(b0)
conv_1 = Conv2D(64,kernel_size=(3,3),strides=(1,1),padding='same',kernel_regularizer=regularizers.l2(weight_decay),
kernel_initializer="he_normal")(a0)
b1 = BatchNormalization(momentum=0.9, epsilon=1e-5)(conv_1)
a1 = Activation('relu')(b1)
conv_2 = Conv2D(64,kernel_size=(3,3),strides=(1,1),padding='same',kernel_regularizer=regularizers.l2(weight_decay),
kernel_initializer="he_normal")(a1)
x = add([x,conv_2])
# Dense input: 8x8x64 output: 64
x = BatchNormalization(momentum=0.9, epsilon=1e-5)(x)
x = Activation('relu')(x)
x = GlobalAveragePooling2D()(x)
# input: 64 output: 10
x = Dense(10,activation='softmax',kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(x)
return x
然后生成模型
img_input = Input(shape=(32,32,3))
output = res_32(img_input)
resnet = Model(img_input, output)
4)开始训练,trick 和 【Keras-VGG19】CIFAR-10 中一样,不再赘述
# set optimizer
sgd = optimizers.SGD(lr=.1, momentum=0.9, nesterov=True)
resnet.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
# set callback
tb_cb = TensorBoard(log_dir=log_filepath, histogram_freq=0)
change_lr = LearningRateScheduler(scheduler)
cbks = [change_lr,tb_cb]
# dump checkpoint if you need.(add it to cbks)
# ModelCheckpoint('./checkpoint-{epoch}.h5', save_best_only=False, mode='auto', period=10)
# set data augmentation
datagen = ImageDataGenerator(horizontal_flip=True,
width_shift_range=0.125,
height_shift_range=0.125,
fill_mode='constant',cval=0.)
datagen.fit(x_train)
# start training
resnet.fit_generator(datagen.flow(x_train, y_train,batch_size=batch_size),
steps_per_epoch=iterations,
epochs=epochs,
callbacks=cbks,
validation_data=(x_test, y_test))
resnet.save('my_resnet_32.h5')
5)结果分析
resnet32 没有用预训练模型
![]()
![]()
training accuracy 和 training loss
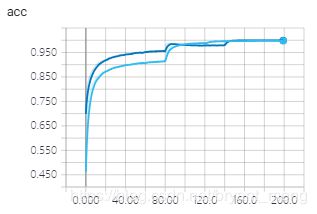
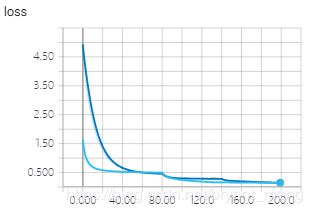
test accuracy 和 test loss
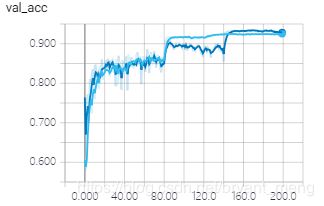


6)参数量和模型大小
VGG的恐怖之处不是盖的……
![]()

-
my_resnet_32
Total params: 470,218
Trainable params: 467,946
Non-trainable params: 2,272 -
vgg19_pretrain_0.0005
Total params: 39,002,738
Trainable params: 38,975,326
Non-trainable params: 27,412
2.2 resnet_32(resnet_32_e)
写代码的时候会发现上面 residual block 结构反复的重复,可以用更简单的形式实现,本节是对上一节的代码优化,结构不变。只需修改网络设计部分即可,其它部分都一样
1)定义residual block,分两种情况,就是上一节图中的左边和中间部分
def residual_block(x,o_filters,increase=False):
stride = (1,1)
if increase:
stride = (2,2)
o1 = Activation('relu')(BatchNormalization(momentum=0.9, epsilon=1e-5)(x))
conv_1 = Conv2D(o_filters,kernel_size=(3,3),strides=stride,padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(o1)
o2 = Activation('relu')(BatchNormalization(momentum=0.9, epsilon=1e-5)(conv_1))
conv_2 = Conv2D(o_filters,kernel_size=(3,3),strides=(1,1),padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(o2)
if increase:
projection = Conv2D(o_filters,kernel_size=(1,1),strides=(2,2),padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(o1)
block = add([conv_2, projection])
else:
block = add([conv_2, x])
return block
2)搭建网络
def residual_network(img_input,classes_num=10,stack_n=5):
# build model ( total layers = stack_n * 3 * 2 + 2 )
# stack_n = 5 by default, total layers = 32
# input: 32x32x3 output: 32x32x16
x = Conv2D(filters=16,kernel_size=(3,3),strides=(1,1),padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(img_input)
# input: 32x32x16 output: 32x32x16
for _ in range(stack_n):
x = residual_block(x,16,False)
# input: 32x32x16 output: 16x16x32
x = residual_block(x,32,True)
for _ in range(1,stack_n):
x = residual_block(x,32,False)
# input: 16x16x32 output: 8x8x64
x = residual_block(x,64,True)
for _ in range(1,stack_n):
x = residual_block(x,64,False)
x = BatchNormalization(momentum=0.9, epsilon=1e-5)(x)
x = Activation('relu')(x)
x = GlobalAveragePooling2D()(x)
# input: 64 output: 10
x = Dense(classes_num,activation='softmax',kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(x)
return x
3)生成模型
# build network
img_input = Input(shape=(32,32,3))
output = residual_network(img_input,10,stack_n) # 5
resnet = Model(img_input, output)
对比下效果
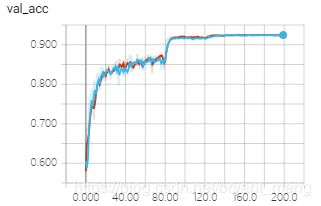

OK,简洁多了,这样写也方便后续对 《Identity Mappings in Deep Residual Networks》 中 a、b、c、d、e 结构的探讨。
2.3 my_resnet_34
把 my_resnet_32 中 residual_block6 和 residual_block11 中左边形式的结构换成右边形式的结构,多出来两层
看看结果


效果差不多,不过resnet_34的参数量会少一些
-
my_resnet_32
Total params: 470,218
Trainable params: 467,946
Non-trainable params: 2,272 -
my_resnet_34
Total params: 416,458
Trainable params: 414,186
Non-trainable params: 2,272
![]()
2.4 resnet_32_a/b/c/d/e
前面的章节中resnet_32就是图上的(e)结构,需要注意的时候,当 feature map size 减半的时候,skip connection 是从 activation之后连接的。(d)也做同样的处理

代码如下
2.4.1 resnet_32_a
residual_block 修改为
def residual_block(x,o_filters,increase=False):
stride = (1,1)
if increase:
stride = (2,2)
conv_1 = Conv2D(o_filters,kernel_size=(3,3),strides=stride,padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(x)
o1 = Activation('relu')(BatchNormalization(momentum=0.9, epsilon=1e-5)(conv_1))
conv_2 = Conv2D(o_filters,kernel_size=(3,3),strides=(1,1),padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(o1)
o2 = BatchNormalization(momentum=0.9, epsilon=1e-5)(conv_2)
if increase:
projection = Conv2D(o_filters,kernel_size=(1,1),strides=(2,2),padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(x)
block = add([o2, projection])
block = Activation('relu')(block)
else:
block = add([o2, x])
block = Activation('relu')(block)
return block
2.4.2 resnet_32_b
residual_block 修改为
def residual_block(x,o_filters,increase=False):
stride = (1,1)
if increase:
stride = (2,2)
conv_1 = Conv2D(o_filters,kernel_size=(3,3),strides=stride,padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(x)
o1 = Activation('relu')(BatchNormalization(momentum=0.9, epsilon=1e-5)(conv_1))
conv_2 = Conv2D(o_filters,kernel_size=(3,3),strides=(1,1),padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(o1)
if increase:
projection = Conv2D(o_filters,kernel_size=(1,1),strides=(2,2),padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(x)
block = add([conv_2, projection])
block = Activation('relu')(BatchNormalization(momentum=0.9, epsilon=1e-5)(block))
else:
block = add([conv_2, x])
block = Activation('relu')(BatchNormalization(momentum=0.9, epsilon=1e-5)(block))
return block
2.4.3 resnet_32_c
residual_block 修改为
def residual_block(x,o_filters,increase=False):
stride = (1,1)
if increase:
stride = (2,2)
conv_1 = Conv2D(o_filters,kernel_size=(3,3),strides=stride,padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(x)
o1 = Activation('relu')(BatchNormalization(momentum=0.9, epsilon=1e-5)(conv_1))
conv_2 = Conv2D(o_filters,kernel_size=(3,3),strides=(1,1),padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(o1)
o2 = Activation('relu')(BatchNormalization(momentum=0.9, epsilon=1e-5)(conv_2))
if increase:
projection = Conv2D(o_filters,kernel_size=(1,1),strides=(2,2),padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(x)
block = add([o2, projection])
else:
block = add([o2, x])
return block
2.4.4 resnet_32_d
residual_block 修改为
def residual_block(x,o_filters,increase=False):
stride = (1,1)
if increase:
stride = (2,2)
o1 = Activation('relu')(x)
conv_1 = Conv2D(o_filters,kernel_size=(3,3),strides=stride,padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(o1)
o2 = Activation('relu')(BatchNormalization(momentum=0.9, epsilon=1e-5)(conv_1))
conv_2 = Conv2D(o_filters,kernel_size=(3,3),strides=(1,1),padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(o2)
o3 = BatchNormalization(momentum=0.9, epsilon=1e-5)(conv_2)
if increase:
projection = Conv2D(o_filters,kernel_size=(1,1),strides=(2,2),padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(o1)
block = add([o3, projection])
else:
block = add([o3, x])
return block
- resnet_32_a/b/c/d 参数量都一样
Total params: 470,410
Trainable params: 468,042
Non-trainable params: 2,368 - resnet_32
Total params: 470,218
Trainable params: 467,946
Non-trainable params: 2,272
training accuracy 和 training loss


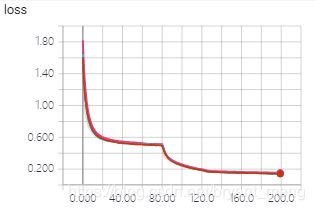
testing accuracy 和 testing loss
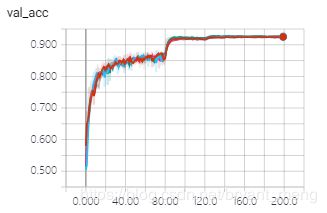
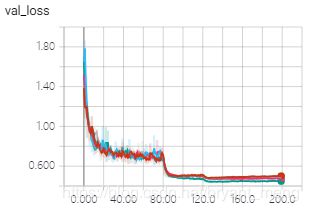

伯仲之间,拉大一点看看

2.5 resnet32_d/e-v2
区别于 resnet_32_d / e, resnet_32_d / e_v2 当 feature map size 减少的时候,采用右边的结构,而不是左边的结构,代码只用修改projection 的输入即可。
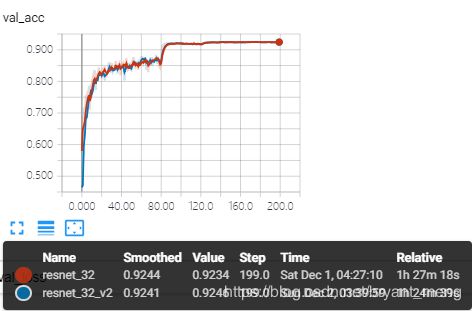

哈哈,改变都不明显。
模型大小

3 resnet_50 / 101 / 152
参考 ResNet-50 architecture(caffe)
根据如下的图,我们改进下来一个 resnet_50 /101 /152,residual block 采用 Relu before addtion 的结构,也就是 resnet_32_c 的结构。
修改如下,第一层卷积,让 channels 变成 64,大小还是32,后面 con2_x 到 con5_x 和表中一样,最后 average pooling 之后 fc 层为 10
1) resnet_50 /101 /152 的 residual block 的设计都一样,如下代码所示:
def residual_block(x,o_filters_1,o_filters_2,increase=False):
""" increase: feature map size 减半,channels 增加 """
stride = (1,1)
if increase:
stride = (2,2)
conv_1 = Conv2D(o_filters_1,kernel_size=(1,1),strides=stride,padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(x)
o1 = Activation('relu')(BatchNormalization(momentum=0.9, epsilon=1e-5)(conv_1))
conv_2 = Conv2D(o_filters_1,kernel_size=(3,3),strides=(1,1),padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(o1)
o2 = Activation('relu')(BatchNormalization(momentum=0.9, epsilon=1e-5)(conv_2))
conv_3 = Conv2D(o_filters_2,kernel_size=(1,1),strides=(1,1),padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(o2)
o3 = Activation('relu')(BatchNormalization(momentum=0.9, epsilon=1e-5)(conv_3))
if increase:
projection = Conv2D(o_filters_2,kernel_size=(1,1),strides=stride,padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(x)
block = add([o3, projection])
else:
block = add([o3, x])
return block
2)网络结构如下:
- resnet_50
def residual_network(img_input,classes_num=10):
# input: 32x32x3 output: 32x32x64
x = Conv2D(filters=64,kernel_size=(3,3),strides=(1,1),padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(img_input)
# input: 32x32x64 output: 16x16x256
x = residual_block(x,64,256,True)
for _ in range(2):
x = residual_block(x,64,256,False)
# input: 16x16x256 output: 8*8*512
x = residual_block(x,128,512,True)
for _ in range(3):
x = residual_block(x,128,512,False)
# input: 8*8*512 output: 4*4*1024
x = residual_block(x,256,1024,True)
for _ in range(5):
x = residual_block(x,256,1024,False)
# input: 4*4*1024 output: 2*2*2048
x = residual_block(x,512,2048,True)
for _ in range(2):
x = residual_block(x,512,2048,False)
x = BatchNormalization(momentum=0.9, epsilon=1e-5)(x)
x = Activation('relu')(x)
x = GlobalAveragePooling2D()(x)
# input: 64 output: 10
x = Dense(classes_num,activation='softmax',kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(x)
return x
- resnet_101
def residual_network(img_input,classes_num=10):
# input: 32x32x3 output: 32x32x64
x = Conv2D(filters=64,kernel_size=(3,3),strides=(1,1),padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(img_input)
# input: 32x32x64 output: 16x16x256
x = residual_block(x,64,256,True)
for _ in range(2):
x = residual_block(x,64,256,False)
# input: 16x16x256 output: 8*8*512
x = residual_block(x,128,512,True)
for _ in range(3):
x = residual_block(x,128,512,False)
# input: 8*8*512 output: 4*4*1024
x = residual_block(x,256,1024,True)
for _ in range(22):
x = residual_block(x,256,1024,False)
# input: 4*4*1024 output: 2*2*2048
x = residual_block(x,512,2048,True)
for _ in range(2):
x = residual_block(x,512,2048,False)
x = BatchNormalization(momentum=0.9, epsilon=1e-5)(x)
x = Activation('relu')(x)
x = GlobalAveragePooling2D()(x)
# input: 64 output: 10
x = Dense(classes_num,activation='softmax',kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(x)
return x
- resnet_152
def residual_network(img_input,classes_num=10):
# input: 32x32x3 output: 32x32x64
x = Conv2D(filters=64,kernel_size=(3,3),strides=(1,1),padding='same',
kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(img_input)
# input: 32x32x64 output: 16x16x256
x = residual_block(x,64,256,True)
for _ in range(2):
x = residual_block(x,64,256,False)
# input: 16x16x256 output: 8*8*512
x = residual_block(x,128,512,True)
for _ in range(3):
x = residual_block(x,128,512,False)
# input: 8*8*512 output: 4*4*1024
x = residual_block(x,256,1024,True)
for _ in range(35):
x = residual_block(x,256,1024,False)
# input: 4*4*1024 output: 2*2*2048
x = residual_block(x,512,2048,True)
for _ in range(2):
x = residual_block(x,512,2048,False)
x = BatchNormalization(momentum=0.9, epsilon=1e-5)(x)
x = Activation('relu')(x)
x = GlobalAveragePooling2D()(x)
# input: 64 output: 10
x = Dense(classes_num,activation='softmax',kernel_initializer="he_normal",
kernel_regularizer=regularizers.l2(weight_decay))(x)
return x
3)结果如下:
- training accuracy 和 training loss



- test accuracy 和 test loss
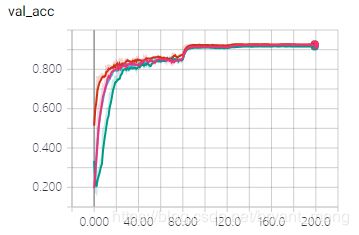

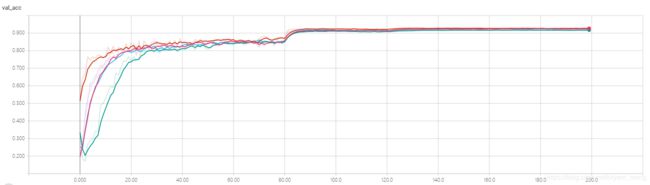
4)test accuracy 放大结果如下

5)参数量
- resnet_30_c
Total params: 470,410
Trainable params: 468,042
Non-trainable params: 2,368 - resnet_50
Total params: 23,593,098
Trainable params: 23,543,690
Non-trainable params: 49,408 - resnet_101
Total params: 42,663,562
Trainable params: 42,561,930
Non-trainable params: 101,632 - resnet_152
Total params: 57,246,858
Trainable params: 57,105,290
Non-trainable params: 141,568
6)生成的模型的大小

4 总结
没有采用 max pooling 而是通过 strides 让 feature map size 减半。由 residual block 中的第一个 conv 的 strides 控制,如果 increase,第一个 conv 的 strides = (2,2),skip connections 中也会多一个 1×1 的 conv,其 strides = (2,2),否则,第一个 conv 的 strides = (1,1),skip connections 中没有 conv,直接与卷积后的结果 add
5 附录
《Deep Residual Learning for Image Recognition》读后感
Q1:Is learning better networks as easy as stacking more layers?
A1:非也,会梯度爆炸,两种解决方案,
1)normalized initialization
2)intermediate normalization layers(BN)
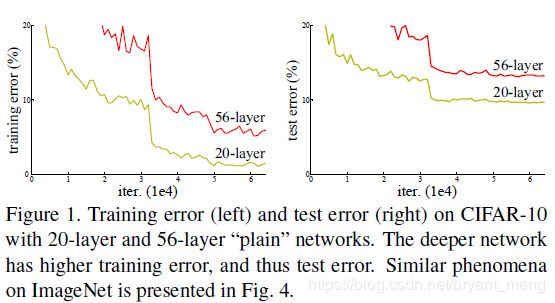
Q2:采用上述两种方案,When deeper networks are able to start converging, a degradation problem has been exposed,网络效果饱和后,越深 performance 反而降低了(见 figure 1)……
A2:Kaiming He 大神提出了 deep residual learning framework,来使得网络越深效果越好,原理是,如果 conv 学习的是自身映射,WX=X,那么网络的 performance 随着网络越来越深,是不会下降的,但事实并非如此,怎么办?说明网络学习的并非自身映射(WX=X),因为网络随着深度增加,效果反而变差,所以 Kaiming He 提出 identity 的 shortcut,相当于给网络加先验,在 identity 的基础上精益求精,因为 identity 至少能保证网络的效果不会随着深度的增加而下降!
假设 WX=X 是网络的最优结构,那么加入的 identity shortcut 也不会忽略这种结果,也即加入 identity shortcut 后,原网络 W 接近0(To the extreme, if an identity mapping were optimal, it would be easier to push the residual to zero than to fit an identity mapping by a stack of nonlinear layers.)
下面一张图能很好的反应出作者这种 innovation 的正确性!
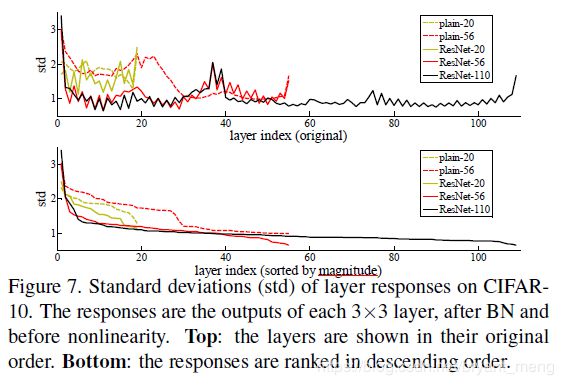
统计 3x3 layer 的在BN后,activation之前的输出,可以看出,std 随着网络的增加减少,也就是说,网络学到后面,在 identity 的基础下,改的越来越少!
Q3:知道网络中 down sampling 喜欢 resolution 减半,channels 翻倍的原因吗?(哈哈,看到解释了)
A3:if the feature map size is halved, the number of filters is doubled so as to preserve the time complexity per layer.
Q4:shortcut 能只跨一层吗?
A4:跨一层没有意义,WX+X 线性变换(注意图2是 addition 之后,才 activation,如果addition之前activation,情况就不一样了,一层就有意义了)

Q5:你了解 PASCAL VOC 中 07+12 和 07++12 的含义吗?
A5:
for the PASCAL VOC 2007 test set,
we use the 5k trainval images in VOC 2007 and 16k trainval images in VOC 2012 for training (“07+12”).
For the PASCAL VOC 2012 test set,
we use the 10k trainval+test images in VOC 2007 and 16k trainval images in VOC 2012 for training (“07++12”).
对ResNet本质的一些思考 这篇文章的视角很好,eg 如果一个信息可以完整地流过一个非线性激活层,则这个非线性激活层对于这个信息而言,相当于仅仅作了一个线性激活。