Flink流计算编程--Flink中allowedLateness详细介绍及思考
1、简介
Flink中借助watermark以及window和trigger来处理基于event time的乱序问题,那么如何处理“late element”呢?
也许有人会问,out-of-order element与late element有什么区别?不都是一回事么?
答案是一回事,都是为了处理乱序问题而产生的概念。要说区别,可以总结如下:
1、通过watermark机制来处理out-of-order的问题,属于第一层防护,属于全局性的防护,通常说的乱序问题的解决办法,就是指这类;
2、通过窗口上的allowedLateness机制来处理out-of-order的问题,属于第二层防护,属于特定window operator的防护,late element的问题就是指这类。下面我们重点介绍allowedLateness。
2、allowedLateness介绍
默认情况下,当watermark通过end-of-window之后,再有之前的数据到达时,这些数据会被删除。
为了避免有些迟到的数据被删除,因此产生了allowedLateness的概念。
简单来讲,allowedLateness就是针对event time而言,对于watermark超过end-of-window之后,还允许有一段时间(也是以event time来衡量)来等待之前的数据到达,以便再次处理这些数据。
下图是其API:

默认情况下,如果不指定allowedLateness,其值是0,即对于watermark超过end-of-window之后,还有此window的数据到达时,这些数据被删除掉了。
注意:对于trigger是默认的EventTimeTrigger的情况下,allowedLateness会再次触发窗口的计算,而之前触发的数据,会buffer起来,直到watermark超过end-of-window + allowedLateness()的时间,窗口的数据及元数据信息才会被删除。再次计算就是DataFlow模型中的Accumulating的情况。
同时,对于sessionWindow的情况,当late element在allowedLateness范围之内到达时,可能会引起窗口的merge,这样,之前窗口的数据会在新窗口中累加计算,这就是DataFlow模型中的AccumulatingAndRetracting的情况。
3、allowedLateness的例子
3.1、TumblingEventTime窗口
这里watermark允许3秒的乱序,allowedLateness允许数据迟到5秒。
import java.text.SimpleDateFormat
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks
import org.apache.flink.streaming.api.{CheckpointingMode, TimeCharacteristic}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
/** * windowedStream.allowedLateness() test,this is also called window accumulating. * allowedLateness will trigger window again when 'late element' arrived to the window */
object TumblingWindowAccumulatingTest {
def main(args : Array[String]) : Unit = {
if (args.length != 2) {
System.err.println("USAGE:\nSocketTextStreamWordCount " )
return
}
val hostName = args(0)
val port = args(1).toInt
val env = StreamExecutionEnvironment.getExecutionEnvironment //获取流处理执行环境
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //设置Event Time作为时间属性
//env.setBufferTimeout(10)
//env.enableCheckpointing(5000,CheckpointingMode.EXACTLY_ONCE)
val input = env.socketTextStream(hostName,port) //socket接收数据
val inputMap = input.map(f=> {
val arr = f.split("\\W+")
val code = arr(0)
val time = arr(1).toLong
(code,time)
})
/** * 允许3秒的乱序 */
val watermarkDS = inputMap.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(String,Long)] {
var currentMaxTimestamp = 0L
val maxOutOfOrderness = 3000L
val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS")
override def getCurrentWatermark: Watermark = {
new Watermark(currentMaxTimestamp - maxOutOfOrderness)
}
override def extractTimestamp(t: (String,Long), l: Long): Long = {
val timestamp = t._2
currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp)
timestamp
}
})
/** * 对于此窗口而言,允许5秒的迟到数据,即第一次触发是在watermark > end-of-window时 * 第二次(或多次)触发的条件是watermark < end-of-window + allowedLateness时间内,这个窗口有late数据到达 */
val accumulatorWindow = watermarkDS
.keyBy(_._1)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.allowedLateness(Time.seconds(5))
.apply(new AccumulatingWindowFunction)
.name("window accumulate test")
.setParallelism(2)
accumulatorWindow.print()
env.execute()
}
}AccumulatingWindowFunction:
主要是计算窗口内的元素个数以及累计个数:
import java.text.SimpleDateFormat
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala.function.RichWindowFunction
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
class AccumulatingWindowFunction extends RichWindowFunction[(String, Long),(String,String,String,Int, String, Int),String,TimeWindow]{
val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS")
var state: ValueState[Int] = _
var count = 0
override def open(config: Configuration): Unit = {
state = getRuntimeContext.getState(new ValueStateDescriptor[Int]("AccumulatingWindow Test", classOf[Int], 0))
}
override def apply(key: String, window: TimeWindow, input: Iterable[(String, Long)], out: Collector[(String, String, String, Int, String, Int)]): Unit = {
count = state.value() + input.size
state.update(count)
// key,window start time, window end time, window size, system time, total size
out.collect(key, format.format(window.getStart),format.format(window.getEnd),input.size, format.format(System.currentTimeMillis()),count)
}
}测试:
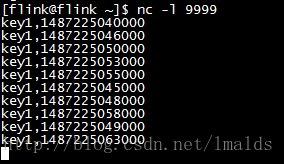
输出结果:

解释:
对于key1而言,1487225040000代表2017-02-16 14:04:00.000,10秒钟的窗口范围是[2017-02-16 14:04:00.000,2017-02-16 14:04:10.000),因此当watermark超过2017-02-16 14:04:10.000时,窗口会被触发,由于watermark是允许3秒乱序,因此当标签时间是1487225053000的数据到来时,窗口被触发了。我们看到结果中的第一行就是第一次触发的窗口,窗口内的元素个数是2,累加个数也是2。
由于此窗口还允许5秒的late,因此在watermark < end-of-window + allowedLateness(2017-02-16 14:04:15.000)之内到达的数据,都会被再次触发窗口的计算。我们看标签是key1,1487225045000的数据,此时的watermark是2017-02-16 14:04:12.000(1487225055000 - 3000得来),因此符合触发条件,立刻触发窗口的计算。也就是我们看到的第二条数据的结果。此时窗口内的元素个数是3,累加个数却是5!!!
同理,key1,1487225048000这条数据第三次触发了窗口的计算。窗口内的个数是4,累加个数是9!!!
当key1,1487225058000的数据到来时,此时的watermark是2017-02-16 14:04:15.000,已经超过了这个窗口的触发范围(窗口都是前闭后开的区间),因此,这个窗口再有迟到的数据,将直接被删除。
我们看到key1,1487225049000这条数据到达时,系统没有任何的反应,即此数据太晚了,被删除了。
最后的一条数据是key1,1487225063000,其watermark是2017-02-16 14:04:20.000,已经超过了下一个窗口的触发时间,因此会触发下一个窗口的计算,结果就是我们看到的最后一条输出的数据,窗口内的元素个数是4(分别是1487225050000,1487225053000,1487225055000和1487225058000),但是累加个数是13!!!
思考:
对于TumblingEventTime窗口的累加处理,很好的一点是及时更新了最后的结果,但是也有一个令人无法忽视的问题,即再次触发的窗口,窗口内的UDF状态错了!这就是我们要关注的问题,我们要做的是去重操作。
至于这个去重怎么做,这个就要看UDF中的状态具体要算什么内容了,例如本例中的state只是简单的sum累计值,此时可以在UDF中添加一个hashMap,map中的key就设计为窗口的起始与结束时间,如果map中已经存在这个key,则state.update时,就不要再加上window.size,而是直接加1即可。这里不再做具体的演示。
附上一张这个测试程序的DAG图:
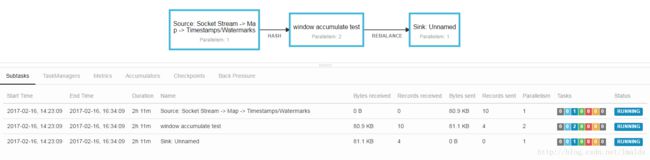
可以看到,window操作接到10条数据(输入),触发了4次window计算(输出)。而且Flink1.2中对与DAG也增加了一些reason元数据信息,例如每个边的类型(Hash或Rebalance)。
3.2、Session Window的窗口(EventTimeSessionWindows)
修改window的类型为SessionWindow并调整windowFunction,去掉state,代码如下:
import java.text.SimpleDateFormat
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.streaming.api.windowing.assigners.{EventTimeSessionWindows, TumblingEventTimeWindows}
import org.apache.flink.streaming.api.windowing.time.Time
object SessionWindowAccumulatingAndRetractingTest {
def main(args : Array[String]) : Unit = {
if (args.length != 2) {
System.err.println("USAGE:\nSocketTextStreamWordCount " )
return
}
val hostName = args(0)
val port = args(1).toInt
val env = StreamExecutionEnvironment.getExecutionEnvironment //获取流处理执行环境
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //设置Event Time作为时间属性
//env.setBufferTimeout(10)
//env.enableCheckpointing(5000,CheckpointingMode.EXACTLY_ONCE)
val input = env.socketTextStream(hostName,port)
val inputMap = input.map(f=> {
val arr = f.split("\\W+")
val code = arr(0)
val time = arr(1).toLong
(code,time)
})
val watermarkDS = inputMap.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(String,Long)] {
var currentMaxTimestamp = 0L
val maxOutOfOrderness = 3000L
val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS")
override def getCurrentWatermark: Watermark = {
new Watermark(currentMaxTimestamp - maxOutOfOrderness)
}
override def extractTimestamp(t: (String,Long), l: Long): Long = {
val timestamp = t._2
currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp)
timestamp
}
})
// allow 5 sec for late element after watermark passed the
val accumulatorWindow = watermarkDS
.keyBy(_._1)
.window(EventTimeSessionWindows.withGap(Time.seconds(10)))
.allowedLateness(Time.seconds(5))
.apply(new AccumulatingAndRetractingWindowFunction)
.name("window accumulate test")
.setParallelism(2)
accumulatorWindow.print()
env.execute()
}
}AccumulatingAndRetractingWindowFunction:
import java.text.SimpleDateFormat
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
class AccumulatingAndRetractingWindowFunction extends WindowFunction[(String, Long),(String,String,String,Int, String),String,TimeWindow]{
val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS")
override def apply(key: String, window: TimeWindow, input: Iterable[(String, Long)], out: Collector[(String, String, String, Int, String)]): Unit = {
// key,window start time, window end time, window size, system time
out.collect(key,format.format(window.getStart),format.format(window.getEnd),input.size,format.format(System.currentTimeMillis()))
}
}测试:
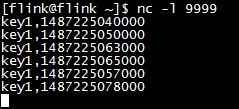
输出结果:
![]()
解释:
sessionWindow由于存在窗口的merge,所以对于late element,并不是来一条就重新触发一次窗口。
第2条数据的watermark没有超过第1条数据的end-of-window时间,因此没有发生gap。
对于第3条数据key1,1487225063000到达时,其watermark是2017-02-16 14:04:20.000,第2条数据的end-of-window的时间,因此第一个窗口触发了,即我们看到的第一条输出记录,其窗口数量是2(前2条输入数据)。
第4条数据key1,1487225065000,其watermark是2017-02-16 14:04:22.000,因此和上一条数据没有gap。
第5条数据key1,1487225057000,其watermar依然是2017-02-16 14:04:22.000,但此数据所在的窗口范围在[2017-02-16 14:04:17.000,2017-02-16 14:04:27.000),属于第一个窗口。虽然此时第一个窗口已经触发,但是第一个窗口的结束时间2017-02-16 14:04:20.000 + allowedLateness(5秒) = 2017-02-16 14:04:25.000,而此时的watermark是2017-02-16 14:04:22.000,因此这条数据不能被删除,而是重新纳入到第一个窗口中,被累加起来。注意,此时窗口发生了合并,但是还未到新的窗口的触发条件。
第6条数据key1,1487225078000到达时,其watermark提高到2017-02-16 14:04:35.000,比此前1487225065000的窗口结束时间(正好是2017-02-16 14:04:35.000)大,因此符合新窗口的触发条件。
即我们看到的输出中第2条记录。此时的窗口范围是从[2017-02-16 14:04:00.000,2017-02-16 14:04:35.000),其中late element和之前的窗口发生了merge,因此前一条输出中的窗口时间变了。新窗口中一共包含了5条数据(前5条数据)。
思考:
这个session window late element的例子,并没有包含UDF的state的内容。但是这里同样不能忽视这个问题,假如你的应用程序中包含UDF的state,那么也要考虑当late element到达且没有被删除的情况下,当发生或者不发生窗口merge的情况下,如何处理state的问题。
对于session window而言,allowedLateness的引入会使得部分late element可以被正确处理,同时也会增加state处理复杂度,这里主要涉及late element可能导致原窗口的merge或者不发生merge。
4、allowedLateness源码
此方法位于WindowedStream中,仅仅是对成员变量allowedLateness赋予初值(但不能指定负数值):
/** * Sets the time by which elements are allowed to be late. Elements that * arrive behind the watermark by more than the specified time will be dropped. * By default, the allowed lateness is {@code 0L}. * * Setting an allowed lateness is only valid for event-time windows. */
@PublicEvolving
public WindowedStream allowedLateness(Time lateness) {
final long millis = lateness.toMilliseconds();
checkArgument(millis >= 0, "The allowed lateness cannot be negative.");
this.allowedLateness = millis;
return this;
} 我们再来看下windowedStream之上执行的apply方法:
/**
* Applies the given window function to each window. The window function is called for each
* evaluation of the window for each key individually. The output of the window function is
* interpreted as a regular non-windowed stream.
*
*
* Not that this function requires that all data in the windows is buffered until the window
* is evaluated, as the function provides no means of incremental aggregation.
*
* @param function The window function.
* @return The data stream that is the result of applying the window function to the window.
*/
public SingleOutputStreamOperator apply(WindowFunction function) {
TypeInformation resultType = TypeExtractor.getUnaryOperatorReturnType(
function, WindowFunction.class, true, true, getInputType(), null, false);//拿到Window的类型(Tumbling、Sliding或Session)以及输入类型T等信息
return apply(function, resultType);
}
返回apply(function, resultType)方法:
/**
* Applies the given window function to each window. The window function is called for each
* evaluation of the window for each key individually. The output of the window function is
* interpreted as a regular non-windowed stream.
*
*
* Note that this function requires that all data in the windows is buffered until the window
* is evaluated, as the function provides no means of incremental aggregation.
*
* @param function The window function.
* @param resultType Type information for the result type of the window function
* @return The data stream that is the result of applying the window function to the window.
*/
public SingleOutputStreamOperator apply(WindowFunction function, TypeInformation resultType) {
//clean the closure
function = input.getExecutionEnvironment().clean(function);
String callLocation = Utils.getCallLocationName();
String udfName = "WindowedStream." + callLocation;
SingleOutputStreamOperator result = createFastTimeOperatorIfValid(function, resultType, udfName);
if (result != null) {
return result;
}
LegacyWindowOperatorType legacyWindowOpType = getLegacyWindowType(function);//根据WindowAssigner判断windowOperator的类型,用于存储window的状态
String opName;
KeySelector keySel = input.getKeySelector(); //根据keyedStream获取key
WindowOperator, R, W> operator;
if (evictor != null) {
@SuppressWarnings({"unchecked", "rawtypes"})
TypeSerializer> streamRecordSerializer =
(TypeSerializer>) new StreamElementSerializer(input.getType().createSerializer(getExecutionEnvironment().getConfig()));
ListStateDescriptor> stateDesc =
new ListStateDescriptor<>("window-contents", streamRecordSerializer);
opName = "TriggerWindow(" + windowAssigner + ", " + stateDesc + ", " + trigger + ", " + evictor + ", " + udfName + ")";
operator =
new EvictingWindowOperator<>(windowAssigner,
windowAssigner.getWindowSerializer(getExecutionEnvironment().getConfig()),
keySel,
input.getKeyType().createSerializer(getExecutionEnvironment().getConfig()),
stateDesc,
new InternalIterableWindowFunction<>(function),
trigger,
evictor,
allowedLateness);
} else {
// 窗口中的ListState,用于在窗口触发前,buffer窗口中的元素
ListStateDescriptor stateDesc = new ListStateDescriptor<>("window-contents",
input.getType().createSerializer(getExecutionEnvironment().getConfig()));
opName = "TriggerWindow(" + windowAssigner + ", " + stateDesc + ", " + trigger + ", " + udfName + ")"; // 拼接唯一的operator名字,记录标志
operator =
new WindowOperator<>(windowAssigner,
windowAssigner.getWindowSerializer(getExecutionEnvironment().getConfig()),
keySel,
input.getKeyType().createSerializer(getExecutionEnvironment().getConfig()),
stateDesc,
new InternalIterableWindowFunction<>(function),
trigger,
allowedLateness,
legacyWindowOpType);
}
return input.transform(opName, resultType, operator);//根据operator name,窗口函数的类型,以及window operator,执行keyedStream.transaform操作
}
我们看到,最终是生成了WindowOperator,初始化时包含了trigger以及allowedLateness的值。然后经过transform转换,实际上是执行了DataStream中的transform方法。
其中,WindowOperator中有一个方法onEventTime,其中,此方法中判断当element的watermark时间超过窗口的结束时间+allowedLateness时,就会清空window中的缓存的所有数据,这里不再赘述。
5、总结
Flink中处理乱序依赖watermark+window+trigger,属于全局性的处理;
同时,对于window而言,还提供了allowedLateness方法,使得更大限度的允许乱序,属于局部性的处理;
其中,allowedLateness只针对Event Time有效;
allowedLateness可用于TumblingEventTimeWindow、SlidingEventTimeWindow以及EventTimeSessionWindows,要注意这可能使得窗口再次被触发,相当于对前一次窗口的窗口的修正(累加计算或者累加撤回计算);
要注意再次触发窗口时,UDF中的状态值的处理,要考虑state在计算时的去重问题。
最后要注意的问题,就是sink的问题,由于同一个key的同一个window可能被sink多次,因此sink的数据库要能够接收此类数据。