《代码整洁之道》阅读分享
文章目录
- 《代码整洁之道》简介
- 代码永存
- 破窗理论与童子军军规
- 为读代码而写代码
- 一、谨慎命名
- 1.1.名副其实
- 1.2.避免误导
- 1.3.去掉冗余
- 1.4.使用读得出来的名称
- 1.5.严谨,不要俏皮
- 1.6.其他规则
- 二、函数和类
- 2.1.保持函数短小精悍,一个函数只做一件事
- 2.2.保持类短小精悍,单一权责原则
- 2.3.条件表达式使用if-else还是卫语句
- 2.4.每个函数一个抽象层级
- 2.5.将修改和查询分离
- 2.6.使用多态替换switch
- 2.7.减少函数参数
- 2.8.重构
- 三、坏注释与好注释
- 3.1.去掉无意义的注释
- 3.2.注释掉的代码
- 3.3.我们是作者——为每个类添加头注释
- 3.4.警示
- 3.5.TODO注释
- 3.6.让代码自解释
- 四、良好的格式
- 4.1.自顶向下的阅读顺序
- 4.2.缩进与间隔
- 五、数据结构
- 5.1.得墨忒定律
- 六、错误处理
- 6.1.抽离 try / catch 代码块
- 6.2.使用异常代替错误码
- 6.3.别返回 null 值、别传递 null 值
- 七、测试代码
- 7.1.保持测试整洁
- 笔者手记
《代码整洁之道》简介
软件质量,不但依赖于架构及项目管理,而且跟代码质量息息相关。代码质量与其整洁度成正比。如同干净的地板能减少事故发生,归置到位的工具能提升生产力一般。干净的代码,既在质量上较为可靠,也为后期维护、升级奠定了良好的基础。
代码永存
有人说过我们正在临近代码的终结点。很快,代码就会自动产生出来,不需要再人工编写。程序员完全没用了,因为产品经理可以直接写出需求,生成代码。
扯淡!我们期待语言的抽象程度继续提升,那会是好事一件,但那终结不了代码。在较高层次上撰写的语言也将是代码。它需要严谨、精确、规范和详细,而不是产品经理提出的天马行空的需求。将需求明确到机器可以执行的细节的程度,就是编程要做的事。
大约在1951年,一种名为“全员生产维护”(Total Productive Maintenance,TPM)的质量保证手段在日本出现。它关注维护甚于关注生产。TPM的主要支柱之一是所谓的5S原则体系。5S是一套规程,包括以下概念:
- 整理。通过恰当的命名之类的手段,搞清楚事物之所在至关重要。
- 整齐。有句美国老话说:物皆有其位,而后物尽归其位(A place for everything, and everything in its place)。每段代码都该在你希望它所在的地方,如果不在那里,就需要重构了。
- 清洁。清理工作地的拉线、油污和边角废料。对于那种四处遗弃的带注释的代码及反映过去或将来的需求的无注释代码,除之而后快。
- 标准化。制定团队整理代码的规范,使用一致的风格整理代码。
- 自律。在实践中贯彻此规程,并时时体现于个人工作上,而且要乐于改进。
丹麦有一句谚语:“小处诚实非小事”,著名建筑师路德维希·密斯·凡德罗也说过:“神在细节之中”,本书介绍了一些小小的整洁代码的技巧,涵盖从命名到重构的多个方面。只要遵循这些规则,就能编写出干净的代码,从而有效提升代码质量。

破窗理论与童子军军规
我喜欢优雅和高效的代码。代码逻辑应当直截了当,叫缺陷难以隐藏;尽量减少依赖关系,使之便于维护;依据某种分层战略完善错误处理代码;性能调至最优,省得引诱别人做没规矩的优化,搞出一堆混乱来。整洁的代码只做好一件事。
————C++语言发明者 Bjarne Stroustrup
犯罪心理学中有一个破窗理论,以一幢有少许破窗的建筑为例,如果那些窗不被及时修理好,可能会有破坏者破坏更多的窗户。最终他们甚至会闯入建筑内,如果发现无人居住,也许就在那里定居或者纵火。一面墙,如果出现一些涂鸦没有被清洗掉,很快地,墙上就布满了乱七八糟、不堪入目的东西;一条人行道有些许纸屑,不久后就会有更多垃圾,最终人们会理所当然地将垃圾顺手丢弃在地上。

在编程过程中,也同样经常出现这些问题。当我们接手了一份结构混乱的代码,如果不及时加以整理,在一团乱麻中继续添加代码,最终将导致代码结构越来越混乱,当我们review代码时,听到最多的辩解就是:前一个人就是这么写的。
程序员面临一种基础价值谜题。有那么几年经验的开发者都知道,之前的混乱拖了自己的后腿,但开发者背负期限的压力,只好继续制造混乱。简言之,他们没有花时间让自己做得更快。
美国童子军有一条简单的军规:让营地比你来时更干净。
清理代码也许只是改好一个变量名,拆分一个有点过长的函数,消除一点点重复代码,清理一个嵌套if语句。当梳理代码时,坚守此军规:每次review代码,让代码比你发现它时更整洁。
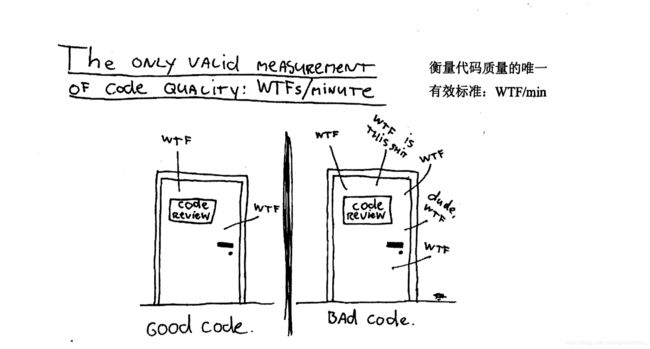
为读代码而写代码
整洁的代码总是看起来像是某位特别在意它的人写的。几乎没有改进的余地。代码作者什么都想到了,如果你企图改进它,总会回到原点,赞叹那位全心投入的某人留给你的代码。
————《修改代码的艺术》作者 Michael Feathers
你或许会问:代码真正“读”的成分有多少呢?难道力量主要不是用在“写”上吗?
你是否玩过“编辑器回放”?20世纪80、90年代,Emac之类编辑器记录每次击键动作。你可以在一小时工作之后,回放击键过程,就像是看一部高速电影。我这么做过,结果很有趣。回放过程显示,多数时间我都是在滚动屏幕、浏览其他模块!
鲍勃进入模块。
他向下滚动到要修改的函数。
他停下来考虑可以做什么。
哦,他滚动到模块顶端,检查变量初始化。
现在他回到修改处,开始键入。
喔,他删掉了键入的内容。
他重新键入。
他又删除了!
他键入了一半什么东西,又删除掉。
他滚动到调用要修改函数的另一函数,看看是怎么调用的。
他回到修改处,重新键入刚才删掉的代码。
他停下来。
他再一次删掉代码!
他打开另一个窗口,查看别的子类,那是个负载函数吗?
…
你该明白了,读与写花费时间的比例超过10:1,写新代码时,我们一直在读旧代码。既然比例如此之高,我们就该让读的过程变得轻松,即便那会使得编写过程更难。
一、谨慎命名
在意你的代码,就像给自己的孩子起名一样给每个变量、每个函数起名。

1.1.名副其实
给函数和变量取个好名字是优秀程序员的基本功,取的名字要名副其实,见文知意。
笔者之前修改过一份遗留代码,其中的变量命名很不规范,例如:
val grzx
val fanhui
val a
val aa
梳理许久,我才知道"grzx"变量是一个TextView,代表"个人中心","fanhui"变量是一个ImageView,代表返回按钮。更好的命名方式为:
val tvUserCenter
val ivBack
"a"和"aa"这样无意义的名字更不要使用,读起来让人不知所云,应该为它取个名副其实的名字。
变量、函数或类的名称应该已经答复了所有的大问题。它该告诉你,它为什么会存在,它做什么事,应该怎么用。如果名称需要注释来补充,那就不算是名副其实。
var d // 消逝的时间,以日计
修改为:
var elapsedTimeInDays
var daysSinceCreation
var daysSinceModification
var fileAgeInDays
选择体现本意的名称能让人更容易理解和修改代码。以下是一个扫雷游戏的部分代码,你能看出它的目的是什么吗?
var theList = listOf(
intArrayOf(0, 0, 0),
intArrayOf(1, 0, 1),
intArrayOf(-1, 1, 0),
intArrayOf(-1, 1, 1)
)
fun getThem(): List<IntArray> {
val list = mutableListOf<IntArray>()
theList.forEach {
if (it[0] == -1) list.add(it)
}
return list
}
这份代码很简单,但是却很模糊。看了之后只会疑惑:theList是什么?theList的数据中0下标的意义是什么?-1的意义是什么?返回的列表是什么?
将其修改如下:
companion object {
const val STATUS_VALUE = 0
const val FLAGGED = -1
}
var gameBoard = listOf(
intArrayOf(0, 0, 0),
intArrayOf(1, 0, 1),
intArrayOf(-1, 1, 0),
intArrayOf(-1, 1, 1)
)
fun getFlaggedCells(): List<IntArray> {
val flaggedCells = mutableListOf<IntArray>()
gameBoard.forEach { cell ->
if (cell[STATUS_VALUE] == FLAGGED) flaggedCells.add(cell)
}
return flaggedCells
}
很容易看出,gameBoard代表游戏面板,gameBoard中的数据的0下标代表状态值,-1的意义是已被标记。返回的列表是游戏面板中已被标记的格子。
本例中,代码的简洁性完全未修改,但代码变得明确多了。
我们还可以更进一步优化:
...
fun getFlaggedCells(): List<IntArray> {
val flaggedCells = mutableListOf<IntArray>()
gameBoard.forEach { cell ->
if (isFlagged(cell)) flaggedCells.add(cell)
}
return flaggedCells
}
private fun isFlagged(cell: IntArray) = FLAGGED == cell[STATUS_VALUE]
1.2.避免误导
1.如果数据本身不是个List,否则别用 personList 来指代一组数据。List一词对程序员有特殊意义。
var personList = mapOf("Martin" to "Author", "Alpinist Wang" to "Reader")
修改为:
var personMap = mapOf("Martin" to "Author", "Alpinist Wang" to "Reader")
2.谨防名字类似,笔者在使用 EasyRecyclerView 库时,看到作者写了两个函数:
fun onCreateViewHolder(){}
fun OnCreateViewHolder(){}
这两个词实在是太相似了,容易对阅读者造成误导,将其修改为:
fun onCreateViewHolder(){}
fun onCreateEasyViewHolder(){}
1.3.去掉冗余
1.废话都是冗余,Variable一词永远不应当出现在变量名中,Table一词永远不应当出现在表名中。 nameString 会比 name 好吗? ProductInfo 、 ProductData 和 Product 有什么区别?更糟糕的是,如果代码中同时存在 Article 和 ArticleInfo 类,程序员怎么知道该调用哪个类呢? Info 和 Data 就像 a 、 an 和 the 一样,属于意义含混的废话。
如果缺少明确的约定, moneyAmount 就与 money 没区别, customerInfo 与 customer 没区别, accountData 和 account 没区别, theMessage 也与 message 没区别,要区分名称,就要以读者能鉴别不同之处的方式来区分。
还有一种使用前缀的情况:设想你有名为 firstName、lastName、street、houseNumber、city、state 和 zipcode 的变量。当它们搁在一块儿时,我们可以很明确的知道这是一个地址。不过,假使是在某个方法中看见孤零零一个 state 变量呢?你还会觉得他是某个地址的一部分吗?这时你可能会添加前缀 addrFirstName、addrLastName、addrState等,以此提供语境。至少,读者会明白这是某个更大的结构的一部分。但是,更好的方案是创建名为 Address 的类,将这些变量放在同一个类中。这样,即使是编辑器也会知道这些变量隶属于某个更大的概念了。
2.在早期的代码中,全局变量带有"m"前缀,这么做的原因是:使用时知道这是全局变量。而在阅读代码时,我们都会自动忽略前缀(和后缀),只看到代码中有意义的部分,代码读得越多,眼中就越没有前缀。最终,前缀变成了不入法眼的废料,成为旧代码的标志物。况且,现代化的IDE会把全局变量设为不同的颜色,现在使用"m"前缀纯属多余。与此类似的还有接口的 “I” 前缀。部分程序员喜欢在每个变量名称前加上"_"前缀一样,去掉他们,让代码更为整洁。
1.4.使用读得出来的名称
在阅读程序时,我往往会再脑海里默念程序执行步骤,如果变量命名如下:
var genymdhms // 生成日期,年、月、日、时、分、秒
阅读时我就会在脑海里默念这些奇怪组合的字母,一边默念一边思考含义。当与其他开发者交流时,他一定会问你,你说的这个gen-Y-M-D…是什么变量?修改为:
var generationTimestamp
这样,就让思维和交流都更加顺畅。
1.5.严谨,不要俏皮
假设你有一个全局的帮助类,GlobalHelper是一个好名字。而你觉得它像个超人一样非常有用,抖机灵把它命名为DiJia(全能的迪迦奥特曼!Biu Biu Biu~),别这样做,因为这会对阅读者造成误解,请让它保持GlobalHelper——宁可明确,毋为好玩。
1.6.其他规则
- 类名应该是名词或名词短语。如 Customer、WikiPage、Account,避免使用Manager、Processor、Data、Info这样的类名。
- 类名不应当是动词。
- 每个概念对应一个词。如果一堆代码中既有Controller,又有Manager,还有Driver,Presenter,就会令人困惑:他们之间有什么区别?为什么不全用Controller?如果同一概念可被多个词语描述,请确定其中一个名字,并在你的代码中一以贯之。
- 使用专业术语。只有程序员才会读你的代码,使用技术领域的名称。
二、函数和类
近年来,我开始研究贝克的简单代码规则,差不多也都琢磨透了。简单代码,依其重要次序:
- 能通过所有测试
- 没有重复代码
- 体现系统中的全部设计理念
- 包括尽量少的实体,比如类、方法、函数等
————《C#极限编程探险》作者 Ron Jeffries
2.1.保持函数短小精悍,一个函数只做一件事
过长的函数不易理解,如果某天这个函数需要修改的话,一个长长的函数让人望而生畏。我们也许只需要修改其中的两行代码,而梳理出这个长函数中的两行代码大大增加了理解成本。并且,小函数也能更好地复用。
1.函数应该清晰明了的实现它的名称声明的事。如果一个函数做了多件事,一个明显的标志是无法为它起一个精准的名字。这时你就应该重构了,将函数提炼成只做一件事的小函数。
2.尽量不要在函数签名中传递状态值。状态值是函数做了多件事的明显标志。将其拆分为不同状态的函数,阅读代码和调用时都会更方便。例如:
fun setLoading(status: Boolean) {
if (status) {
loading.VISIBILITY = View.VISIBLE
} else {
loading.VISIBILITY = View.GONE
}
}
修改为:
fun showLoading() {
loading.VISIBILITY = View.VISIBLE
}
fun hideLoading() {
loading.VISIBILITY = View.GONE
}
2.2.保持类短小精悍,单一权责原则
同样,类也应该保持短小、并符合单一权责原则。高内聚,低耦合。隔离让系统对每个元素的理解变得容易。
单一权责原则:在面向对象编程领域中,单一权责原则(Single responsibility principle)规定每个类都应该有一个单一的功能,并且该功能应该由这个类完全封装起来。一个类或者模块应该有且只有一个改变的原因。
2.3.条件表达式使用if-else还是卫语句
条件表达式通常有两种表现形式。第一种形式是:所有分支都属于正常行为。第二种形式是:条件表达式提供的答案中只有一种是正常行为,其他都是不常见的情况。
如果两条分支都是正常行为,就应该使用if-else语句。如果其中一个条件是极少发生的,就应该单独检查该条件,并在其发生时,立即从函数中返回。这样的单独检查常常被称作“卫语句”(guard clauses)。例如:
fun getPayAmount() {
var result: Int
if (isSeparated()) result = separatedAmount()
else {
if (isRetired()) result = retiredAmount()
else result = normalPayAmount()
}
return result
}
这是一份获取工资的代码,如果员工已经离职了,获取离职工资;如果员工已经退休了,获取退休工资,否则获取正常工资。
离职和退休都属于特殊情况,修改为:
fun getPayAmount() {
if (isSeparated()) return separatedAmount()
if (isRetired()) return retiredAmount()
return normalPayAmount()
}
另外,在条件表达式中,应避免否定性条件,否定式要比肯定式难明白一些。所以,尽可能将条件表示为肯定形式。
2.4.每个函数一个抽象层级
同一个函数中的代码应该属于同一层级。创建分离较高层级一般性概念与较低层级细节概念的抽象模型,这很重要。例如:只与细节有关的常量、变量或工具函数不应该在基类中出现。基类应该对这些东西一无所知。
良好的软件设计要求分离位于不同层级的概念,将它们放到不同容器中。有时,这些容器是基类或派生类,有时是源文件、模块或组件。无论哪种情况,分离都要完整。较低层级概念和较高层级概念不应混杂在一起。
fun printOwing() {
printBanner()
// 打印详情
System.out.println("name: $name")
System.out.println("amount: ${getOutstanding()}")
}
修改为:
fun printOwing() {
printBanner()
printDetails()
}
fun printDetails() {
System.out.println("name: $name")
System.out.println("amount: ${getOutstanding()}")
}
2.5.将修改和查询分离
查询函数中不要做修改操作。这样调用者就可以多次调用查询函数而且没有任何副作用。将有副作用的修改函数单独提出。否则若在查询数据时修改了数据,调用者会产生迷惑。这也容易成为bug之源。
副作用是一种谎言。函数承诺只做一件事,但却偷偷做了其他事。这样的谎言是破坏性的,有时会导致古怪的时序性耦合及顺序依赖。
2.6.使用多态替换switch
switch语句天生就要做多件事。随着switch条件的增多,它做的事情也会增多。如果出现了,考虑使用多态替换之。
2.7.减少函数参数
1.最理想的函数参数数量是0,其次是1,再次是2,应尽量避免3。有足够特殊的理由才能使用三个以上参数——所以无论如何也不要这么做。
2.参数带有太多概念性,没有参数的函数能够见名知意,理解带参数的函数不仅要理解其名字,还要理解其所有参数。
3.太多的参数会造成测试困难。如果参数多于两个,测试覆盖所有可能值的组合让人望而生畏。
2.8.重构
- 消除特性依恋: 如果一个类过度的使用另一个类的方法,请将依恋代码移至另一个类
- 消除重复
- 用命名常量替代魔术数
更多的重构手法参见《重构改善既有代码的设计》一书。
三、坏注释与好注释
3.1.去掉无意义的注释
如果注释纯属废话,请去掉它,例如:
// 如果count > 0,返回1,否则返回-1
if (count > 0) {
return 1
} else {
return -1
}
代码已经清晰的表达了意图,这些注释看起来就像是喃喃自语。
再比如:
// 当this.closed变为true时,直接返回。如果超时未关闭,抛出一个异常
fun waitForClose(timeoutMillis: Long) {
if (closed) return
wait(timeoutMillis)
if (!closed) throw Exception("发射器关闭异常")
}
读这段注释的时间没准比读代码花的时间还要长。而且,你是否发现这个注释有误导读者的嫌疑?
当this.closed中途变为true时,函数并不会直接返回。函数仅仅在开始时判断了this.closed是否为true,否则就只是等待遥遥无期的超时。然后在超时等待时间结束后,再判断this.closed状态。
这一细微的误导信息,放在比代码本身更难阅读的注释里面,有可能导致某位程序员快乐地调用这个函数,并期望在 this.closed 变为true时立即返回。那位可怜的程序员将会发现自己陷入调试困境之中,拼命想找出代码执行得如此之慢的原因。
3.2.注释掉的代码
曾经有一段时间,注释掉的代码可能有用。但我们已经拥有良好的源代码控制系统如此之久,这些系统可以为我们记住不要的代码。我们无需再用注释来标记,删掉即可。当你需要时,很容易就能找回。事实证明,注释掉的代码往往用着过时的函数和变量,很少有需要的时候。
3.3.我们是作者——为每个类添加头注释
为每个类添加头注释,用@author字段告诉别人你是谁。写代码的时候,记得自己是作者,要为评判你工作的读者写代码,对自己的代码负责。
3.4.警示
用于警告其他程序员会出现某种后果的注释是有用的,例如:
fun getDataFormat(): SimpleDateFormat {
// SimpleDateFormat不是线程安全的,所以我们需要每次创建新的实例
val df = SimpleDateFormat("yyyy-MM-dd")
df.timeZone = TimeZone.getTimeZone("GMT")
return df
}
你也许会抱怨说,还会有更好的解决方法。我同意你所说的。不过上面的注释绝对有道理存在,它能阻止某位急切的程序员以效率之名使用静态初始器。
3.5.TODO注释
有时,我们需要使用 TODO 注释来表示自己认为应该做,但由于某些原因目前还没做的工作。它可能要提醒删除某个不必要的特性,或者要求他人注意某个问题。它可能是恳请别人取个好名字,或者提示对依赖于某个计划事件的更改。无论 TODO 的目的如何,它都不是在系统中留下糟糕代码的接口。
一定要定期查看 TODO 注释,删除不再需要的。不要让 TODO 变成程序员的谎言。
3.6.让代码自解释
注释并不像辛德勒的名单。它们并不“纯然的好”。若代码足够有表达力,用代码来展示意图往往会更好。注释总是一种失败。当我们无法找到不用注释就能表达自我的方法时,我们写了注释,这并不值得庆贺。
如果你发现自己需要写注释,再想想看是否有办法翻盘——用代码来表达。每次用代码来表达,你都该夸奖一下自己。每次写注释,你都该做个鬼脸,羞愧于自己在表达能力上的失败。
我为什么极力贬低注释?因为注释会撒谎。也不是说总是如此或有意如此,但出现得实在太频繁。注释存在的时间越久,就离其所描述的代码越远,越来越变得全然错误。原因很简单。程序员不能坚持维护注释。
代码在变动,在演化。从这里移到那里。彼此分离、重造又合到一起。很不幸,注释并不总是随之变动。注释常常会与其所描述的代码分割开来,孑然飘零,越来越不准确。
当你想写一句注释时,更好的方式是将你想要写注释的代码提取出一个单独的方法,再给它起个好名字。
你愿意看到这个:
// 如果员工是优秀员工
if (employee.flags == AWESOME && employee.value > 9) {
// 颁发优秀员工奖励
employee.holiday += 5
employee.money += 2000
}
还是这个:
if (employee.isExcellent) {
employee.getReward()
}
写注释的常见动机之一是糟糕代码的存在。我们编写一个模块,发现它令人困扰、乱七八糟,它烂透了。我们告诉自己:“喔,最好写点注释!”—— 不!最好是把代码整理干净。
// 初始化数据和初始化视图
fun init(){}
修改为:
fun initData(){}
fun initView(){}
四、良好的格式
4.1.自顶向下的阅读顺序
想想看你阅读新闻时,在顶部,你期望有个头条,告诉你故事的主题,好让你决定是否要读下去。第一段是整个故事的大纲,给出粗线条概述,但隐藏了故事细节。接着读下去,细节渐次增加,直至你了解所有的日期、名字、引语、说法及其他细节。
源文件也要像新闻文章一样,最顶部给出高层次概念和算法,细节向下渐次展开,直至找到源文件中最底层的函数和细节。函数应该紧跟调用处,保证垂直方向上的靠近。当阅读代码时,能够很流畅的读完。否则若滑上滑下的阅读代码,容易导致思维不流畅,影响理解。
4.2.缩进与间隔
现代化的IDE都有格式化代码快捷键,例如Mac的Android Studio格式化代码快捷键是"Command + Alt + L",你也可以在设置中搜索"Reformat Code",自定义格式化代码快捷键。随时格式化,并去掉多余的空行,让代码保持清爽是一个好习惯。
五、数据结构
5.1.得墨忒定律
著名的得墨忒定律(The Law of Demeter)认为:模块不应该了解它所操作对象的内部情形。
换言之,只跟朋友谈话,不与朋友的朋友谈话。不要为了节省变量,写过长的链式调用。在关键的地方为其取个有意义的名字,更容易理清结构,调试也更方便。
val appId = packageManager.getApplicationInfo(packageName, PackageManager.GET_META_DATA).metaData.get("app_id")
修改为:
val applicationInfo = packageManager.getApplicationInfo(packageName, PackageManager.GET_META_DATA)
val metaData = applicationInfo.metaData
val appId = metaData.get("app_id")
六、错误处理

6.1.抽离 try / catch 代码块
try / catch 代码块丑陋不堪,他们搞乱了代码结构,把错误处理与正常流程混为一谈。最好把 try 和 catch 代码块的主体部分抽离出来,另外形成函数。
错误处理就是一件事。
6.2.使用异常代替错误码
现代化的语言都有异常机制,对于绝对不应该出现的情况,有的程序员会选择返回0或者-1等错误码,保持程序不崩溃。
请不要这样做,将错误码替换为抛出异常,出现错误时立马就可以发现,更容易定位问题。而不是在错误的状态下继续执行,将来造成更加迷惑的错误。
6.3.别返回 null 值、别传递 null 值
要讨论错误处理,就一定要提及那些容易引发错误的做法。第一项就是返回 null 值。我不想去计算曾经见过多少几乎每行代码都在检查 null 值的应用程序。返回 null 值基本上就是在给自己增加工作量,也是在给调用者添乱。只要有一处没有检查 null 值,应用程序就会失控。返回 null 不如抛出 NullPointerException ,或是替换为一个空对象。让调用者不再需要检查 null,代码也就更整洁了。
七、测试代码
如果每个例程都让你感到深合己意,那就是整洁代码,如果代码让编程语言看起来像是专为解决那个问题而存在,就可以称之为漂亮的代码。
————Wiki发明者,极限编程创始人之一 Ward Cunningham
7.1.保持测试整洁
测试带来的好处不必多说。有了测试,你就不必担心对代码的修改。修改代码后,只需一键运行测试代码,便可验证本次修改是否破坏了原有逻辑。
几年前,有人请我去指导一个开发团队。那个团队认定,测试代码的维护不应遵循生产代码的质量标准。他们彼此默许在单元测试中破坏规矩。“速而不周”成了团队格言。变量命名不用好,测试函数不必短小和具有描述性。测试代码不必做良好设计和仔细划分。只要测试代码还能工作,只要还覆盖着生产代码,就足够好。
有些读者可能会同意这种做法。从编写那种用后即扔的测试到编写全套自动化单元测试是一大进步。所以,就像那个我指导过的团队一样,你或许会认为脏测试好过没测试。
这个团队没有意识到的是,脏测试等用于——如果不是坏于的话——没测试。问题在于,测试必须随着生产代码的演进而修改。测试越脏,就越难修改。测试代码越缠结,你就越有可能花更多时间塞进新测试,而不是编写新生产代码。修改生产代码后,旧测试就会开始失败,而测试代码中乱七八糟的东西将阻碍代码再次通过。于是,测试变得就像是不断翻番的债务。
随着版本递进,团队维护测试代码组的代价也在上升。最终,它变成了开发者最大的抱怨对象。当经理们问及为何超支如此巨大,开发者们就归咎于测试。最后,他们只能扔掉了整个测试代码组。
但是,没有了测试代码组,他们就失去了确保对代码的改动能如愿工作的能力。没有了测试代码组,他们就无法确保对系统某个部分的修改不会影响到系统的其他部分。故障率开始增加。随着并非出自有意的故障越来越多,他们开始害怕做改动。他们不再清理生产代码,因为他们害怕修改带来的损害多于收益。生产代码开始腐坏。最后,他们只剩下没有测试、纷乱而缺陷缠身的生产代码,沮丧的客户,还有对测试的失望。
在某种意义上,他们说对了。测试的确让他们失望。不过是他们自己决定让测试变得乱七八糟的,而那正是失败的根源。如果他们保持测试整洁,测试就不会令他们失望。我可以拍着胸脯这么说,因为我曾经参与并指导了多个凭借整洁单元测试获得成功的团队。
故事的寓意很简单:测试代码和生产代码一样重要。它可不是二等公民。它需要被思考、被设计和被照料。它该像生产代码一样保持整洁。
笔者手记
《代码整洁之道》讲述的大多是一些编程细节和好习惯,并不是那种让人醍醐灌顶的书,它更像是一个指引,一本避坑指南,Martin将其从业多年遇到的一些好习惯和坏习惯列举出来一一对比,告诉读者哪些习惯应该坚持,哪些习惯应该摒弃。
比如笔者在阅读之前,确实受到一些流言影响,认为注释越多越好,越细越好。Martin告诉我,注释并不全然的好,程序员维护程序的同时往往不会花时间维护注释,导致注释说谎;以及一些喃喃自语或抖机灵的注释实际上会影响代码的阅读。有的源代码中在大括号‘}’旁添加注释,表示它是哪一个条件的闭括号,在阅读本书之前,我可能认为这是一种好习惯,甚至我可能会效仿,在阅读本书后我知道这也是一种冗余的代码,并不值得坚持。
再比如有的源代码中采用长长的链式调用,作者甚至会鼓吹“我只写了一行代码便实现了此功能”,Martin告诉我,这样容易导致“火车失事”,正确的做法是遵守“得墨忒定律”:适当拆解链式调用,只和朋友谈话,不和朋友的朋友谈话,使得代码阅读和调试都更方便。
再比如笔者在学习写测试代码时,确实如Martin所唾弃的那样,不管不顾测试代码的结构,认为有测试好过没测试。Martin告诉我,测试不是“二等公民”,它同样应该保持良好的结构,以保证测试代码的可维护。
Martin在本书中告诉我们正确的代码、好的代码应该怎样怎样,这样即使我们在工作中,在公司凌乱不堪的源码中深陷泥淖,心中仍然知道代码的伊甸园长什么样。有了这样一个清晰的目标,我们就能一步一步地向着它前进,而不至于走偏方向。或许这也是译者将其译作“道”的原因吧。
最重要的是,Martin向我们传递出自己“不向肮脏代码低头”,用他近乎偏执的决心清理代码、重构代码,保证它的整洁。阅读本书时,笔者心中充满了感动与敬畏,真切地感受到一位程序大师的工匠之心,我们要像照顾孩子一样照顾代码,像热爱生命一样热爱代码。
以上,就是笔者对《代码整洁之道》的阅读分享。