Flink开发需要的环境
运行环境介绍
Flink执行环境主要分为本地环境和集群环境,本地环境主要为了方便用户编写和调试代码使用,而集群环境则被用于正式环境中,可以借助Hadoop Yarn或Mesos等不同的资源管理器部署自己的应用。
- 环境依赖
(1)JDK环境
Flink核心模块均使用Java开发,所以运行环境需要依赖JDK,本书暂不详细介绍JDK安装过程,用户可以根据官方教程自行安装,其中包括Windows和Linux环境安装,需要注意的是JDK版本需要保证在1.8以上。
(2)Scala环境
如果用户选择使用Scala作为Flink应用开发语言,则需要安装Scala执行环境,Scala环境可以通过本地安装Scala执行环境,也可以通过Maven依赖Scala-lib来引入。
(3)Maven编译环境
Flink的源代码目前仅支持通过Maven进行编译,所以如果需要对源代码进行编译,或通过IDE开发Flink Application,则建议使用Maven作为项目工程编译方式。Maven的具体安装方法这里不再赘述。
需要注意的是,Flink程序需要Maven的版本在3.0.4及以上,否则项目编译可能会出问题,建议用户根据要求进行环境的搭建。
(4)Hadoop环境
对于执行在Hadoop Yarn资源管理器的Flink应用,则需要配置对应的Hadoop环境参数。目前Flink官方提供的版本支持hadoop2.4、2.6、2.7、2.8等主要版本,所以用户可以在这些版本的Hadoop Yarn中直接运行自己的Flink应用,而不需要考虑兼容性的问题。
Flink项目模板
Flink为了对用户使用Flink进行应用开发进行简化,提供了相应的项目模板来创建开发项目,用户不需要自己引入相应的依赖库,就能够轻松搭建开发环境,前提是在JDK(1.8及以上)和Maven(3.0.4及以上)的环境已经安装好且能正常执行。在Flink项目模板中,Flink提供了分别基于Java和Scala实现的模板,下面就两套项目模板分别进行介绍和应用。
基于Java实现的项目模板
- 创建项目
创建模板项目的方式有两种,一种方式是通过Maven archetype命令进行创建,另一种方式是通过Flink提供的Quickstart Shell脚本进行创建,具体实例说明如下。
- 通过Maven Archetype进行创建:
$ mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.8.0
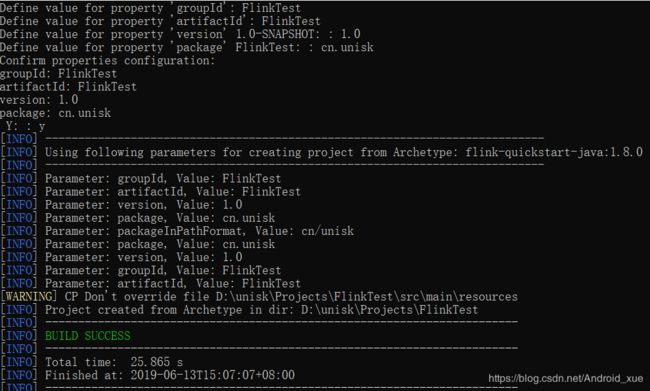
通过以上Maven命令进行项目创建的过程中,命令会交互式地提示用户对项目的groupId、artifactId、version、package等信息进行定义,且部分选项具有默认值,用户直接回车即可,如下图所示。我们创建了实例项目成功之后,客户端会提示用户项目创建成功,且在当前路径中具有相应创建的Maven项目。
- 通过quickstart脚本创建:
$ curl https://flink.apache.org/q/quickstart.sh | bash -s 1.8.0
通过以上脚本可以比较简单地创建项目,执行后项目会自动生成,但是项目的名称和一些GAV信息都是自动生成的,用户不能进行交互式重新定义,其中的项目名称为quickstart,gourpid为org.myorg.quickstart,version为0.1。这种方式对于Flink入门相对比较适合,其他有一定基础的情况下,则不建议使用这种方式进行项目创建。
注意
在Maven 3.0以上的版本中,DarchetypeCatalog配置已经从命令行中移除,需要用户在Maven Settings中进行配置,或者直接将该选项移除,否则可能造成不能生成Project的错误。
- 检查项目
对于使用quickstart curl命令创建的项目,我们可以看到的项目结构如代码下面清单所示,如果用户使用Maven Archetype,则可以自己定义对应的artifactId等信息。
tree quickstart/
quickstart/
├── pom.xml
└── src
└── main
├── java
│ └── org
│ └── myorg
│ └── quickstart
│ ├── BatchJob.java
│ └── StreamingJob.java
└── resources
└── log4j.properties
从上述项目结构可以看出,该项目已经是一个相对比较完善的Maven项目,其中创建出来对应的Java实例代码,分别是BatchJob.java和Streaming.java两个文件,分别对应Flink批量接口DataSet的实例代码和流式接口DataStream的实例代码。在创建好上述项目后,建议用户将项目导入到IDE进行后续开发,Flink官网推荐使用的是Intellij IDEA或者Eclipse进行项目开发,具体的开发环境配置可以参考后面的介绍。
- 编译环境
项目经过上述步骤创建后,可以使用Maven Command命令mvn clean package对项目进行编译,编译完成后在项目同级目录会生成target/-.jar,则该可执行Jar包就可以通过Flink命令或者Web客户端提交到集群上执行。
注意
通过Maven创建Java应用,用户可以在Pom中指定Main Class,这样提交执行过程中就具有默认的入口Main Class,否则需要用户在执行的Flink App的Jar应用中指定Main Class。
如:
cn.unisk.StreamingJob
- 开发应用
在项目创建和检测完成后,用户可以选择在模板项目中的代码上编写应用,也可以定义Class调用DataSet API或DataStream API进行Flink应用的开发,然后通过编译打包,上传并提交到集群上运行。具体应用的开发可以参考后续文章。
基于Scala实现项目模板
Flink在开发接口中同样提供了Scala的接口,用户可以借助Scala高效简洁的特性进行Flink App的开发。在创建项目的过程中,也可以像上述Java一样创建Scala模板项目,而在Scala项目中唯一的区别就是可以支持使用SBT进行项目的创建和编译,以下实例,将从SBT和Maven两种方式进行介绍。
- 创建项目
(1)创建Maven项目
1)使用Maven archetype进行项目创建
下面代码清单是通过Maven archetype命令创建Flink Scala版本的模板项目,其中项目相关的参数同创建Java项目一样,需要通过交互式的方式进行输入,用户可以指定对应的项目名称、groupid、artifactid以及version等信息。
$ mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-scala \
-DarchetypeVersion=1.8.0
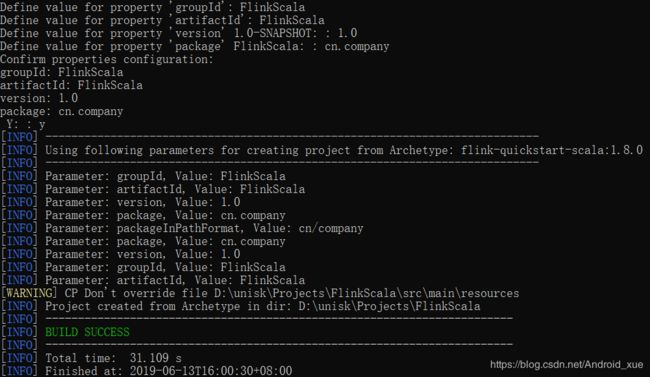
执行完上述命令之后,会显示如图下图所示的提示,表示项目创建成功,可以进行后续操作。同时可以在同级目录中看到已经创建好的Scala项目模板,其中包括了两个Scala后缀的文件。
2)使用quickstart curl脚本创建
如上节所述,在创建Scala项目模板的过程中,也可以通过quickstart curl脚本进行创建,这种方式相对比较简单,只要执行以下命令即可:
$ curl https://flink.apache.org/q/quickstart-scala.sh | bash -s 1.8.0
执行上述命令后就能在路径中看到相应的quickstart项目生成,其目录结构和通过Maven archetype创建的一致,只是不支持修改项目的GAV信息。
(2)创建SBT项目
在使用Scala接口开发Flink应用中,不仅可以使用Maven进行项目的编译,也可以使用SBT(Simple Build Tools)进行项目的编译和管理,其项目结构和Maven创建的项目结构有一定的区别。可以通过SBT命令或者quickstart脚本进行创建SBT项目,具体实现方式如下:
1)使用SBT命令创建项目
$ sbt new tillrohrmann/flink-project.g8
执行上述命令后,会在客户端输出创建成功的信息,表示项目创建成功,同时在同级目录中生成创建的项目,其中包含两个Scala的实例代码供用户参考。
2)使用quickstart curl脚本创建项目
可以通过使用以下指令进行项目创建Scala项目:
$ bash <(curl https://flink.apache.org/q/sbt-quickstart.sh)
注意
如果项目编译方式选择SBT,则需要在环境中提前安装SBT编译器,同时版本需要在0.13.13以上,否则无法通过上述方式进行模板项目的创建,具体的安装教程可以参考SBT官方网站进行下载和安装。
- 检查项目
对于使用Maven archetype创建的Scala项目模板,其结构和Java类似,在项目中增加了Scala的文件夹,且包含两个Scala实例代码,其中一个是实现DataSet接口的批量应用实例BatchJob,另外一个是实现DataStream接口的流式应用实例StreamingJob,如下面代码清单所示。
tree quickstart/
quickstart/
├── pom.xml
└── src
└── main
├── resources
│ └── log4j.properties
└── scala
└── org
└── myorg
└── quickstart
├── BatchJob.scala
└── StreamingJob.scala
-
编译项目
1)使用Maven编译 进入到项目路径中,然后通过执行mvn clean package命令对项目进行编译,编译完成后产生target/-.jar。
2)使用Sbt编译 进入到项目路径中,然后通过使用sbt clean assembly对项目进行编译,编译完成后再产生target/scala_your-major-scala-version/project-name-assembly-0.1-SNAPSHOT.jar。 -
开发应用
在项目创建和检测完成后,用户可以选择在Scala项目模板的代码上编写应用,也可以定义Class调用DataSet API或DataStream API进行Flink应用的开发,然后通过编译打包,上传并提交到集群上运行。
Flink开发环境配置
我们可以选择IntelliJ IDEA或者Eclipse作为Flink应用的开发IDE,但是由于Eclipse本身对Scala语言支持有限,所以Flink官方还是建议用户能够使用IntelliJ IDEA作为首选开发的IDE,以下将重点介绍使用IntelliJ IDEA进行开发环境的配置。
下载IntelliJ IDEA IDE
用户可以通过IntelliJ IDEA官方地址下载安装程序,根据操作系统选择相应的程序包进行安装。安装方式和安装包请参考这里。
安装Scala Plugins
对于已经安装好的IntelliJ IDEA默认是不支持Scala开发环境的,如果用户选择使用Scala作为开发语言,则需要安装Scala插件进行支持。以下说明在IDEA中进行Scala插件的安装:
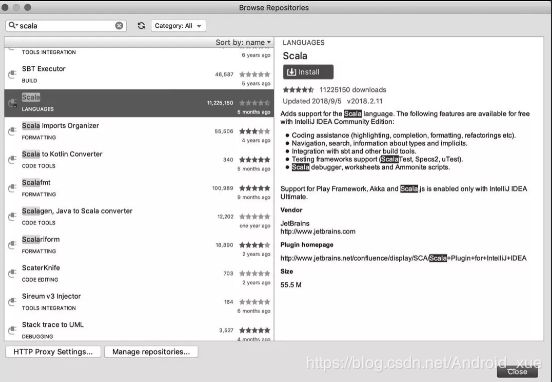
- 打开IDEA IDE后,在IntelliJ IDEA菜单栏中选择 Preferences选项,然后选择Plugins子选项,最后在页面中选择Browser Repositories,在搜索框中输入Scala进行检索;
- 在检索出来的选项列表中选择和安装Scala插件,如图下图所示;
- 点击安装后重启IDE,Scala编程环境即可生效。
导入Flink应用代码
开发环境配置完毕之后,下面就可以将前面创建好的项目导入到IDE中,具体步骤如下所示:
- 启动IntelliJ IDEA,选择File→Open,在文件选择框中选择创建好的项目(quickstart),点击确定,IDEA将自动进行项目的导入;
- 如果项目中提示没有SDK,可以选择File→Project Structure,在SDKS选项中选择安装好的JDK路径,添加Scala SDK路径,如果系统没有安装Scala SDK,也可以通过Maven Dependence将scala-lib引入;
- 项目正常导入之后,程序状态显示正常,可以通过mvn clean package或者直接通过IDE中自带的工具Maven编译方式对项目进行编译;
完成了在IntelliJ IDEA中导入Flink项目,接下来用户就可以开发Flink应用了。
项目配置
对于通过项目模板生成的项目,项目中的主要参数配置已被初始化,所以无须额外进行配置,如果用户通过手工进行项目的创建,则需要创建Flink项目并进行相应的基础配置,包括Maven Dependences、Scala的Version等配置信息。
- Flink基础依赖库
对于Java版本,需要在项目的pom.xml文件中配置如下面代码清单所示的依赖库,其中flink-java和flink-streaming-java分别是批量计算DataSet API和流式计算DataStream API的依赖库,{flink.version}是官方的发布的版本号,用户可根据自身需要进行选择。
org.apache.flink
flink-java
{flink.version}
provided
org.apache.flink
flink-streaming-java_2.11
{flink.version}
provided
创建Scala版本Flink项目依赖库配置如下,和Java相比需要指定scala的版本信息,目前官方建议的是使用Scala 2.11,如果需要使用特定版本的Scala,则要将源码下载进行指定Scala版本编译,否则Scala各大版本之间兼容性较弱会导致应用程序在实际环境中无法运行的问题。Flink基于Scala语言项目依赖配置库如下面代码清单所示:
org.apache.flink
flink-scala_2.11
{flink.version}
provided
org.apache.flink
flink-streaming-scala_2.11
{flink.version}
provided
另外在上述Maven Dependences配置中,核心的依赖库配置的Scope为provided,主要目的是在编译阶段能够将依赖的Flink基础库排除在项目之外,当用户提交应用到Flink集群的时候,就避免因为引入Flink基础库而导致Jar包太大或类冲突等问题。而对于Scope配置成provided的项目可能出现本地IDE中无法运行的问题,可以在Maven中通过配置Profile的方式,动态指定编译部署包的scope为provided,本地运行过程中的scope为compile,从而解决本地和集群环境编译部署的问题。
不然会报错:
Error:scalac: missing or invalid dependency detected while loading class file 'ScalaCaseClassSerializer.class'.
Could not access type SelfResolvingTypeSerializer in object org.apache.flink.api.common.typeutils.TypeSerializerConfigSnapshot,
because it (or its dependencies) are missing. Check your build definition for
missing or conflicting dependencies. (Re-run with `-Ylog-classpath` to see the problematic classpath.)
A full rebuild may help if 'ScalaCaseClassSerializer.class' was compiled against an incompatible version of org.apache.flink.api.common.typeutils.TypeSerializerConfigSnapshot.
注意
由于Flink在最新版本中已经不再支持scala 2.10的版本,建议读者使用scala 2.11,同时Flink将在未来的新版本中逐渐支持Scala 2.12。
- Flink Connector和Lib依赖库
除了上述Flink项目中应用开发必须依赖的基础库之外,如果用户需要添加其他依赖,例如Flink中內建的Connector,或者其他第三方依赖库,需要在项目中添加相应的Maven Dependences,并将这些Dependence的Scope需要配置成compile。
如果项目中需要引入Hadoop相关依赖包,和基础库一样,在打包编译的时候将Scope注明为provided,因为Flink集群中已经将Hadoop依赖包添加在集群的环境中,用户不需要再将相应的Jar包打入应用中,否则容易造成Jar包冲突。
注意
对于有些常用的依赖库,为了不必每次都要上传依赖包到集群上,用户可以将依赖的包可以直接上传到Flink安装部署路径中的lib目录中,这样在集群启动的时候就能够将依赖库加载到集群的ClassPath中,无须每次在提交任务的时候上传依赖的Jar包。
运行Scala REPL
和Spark Shell一样,Flink也提供了一套交互式解释器(Scala-Shell),用户能够在客户端命令行交互式编程,执行结果直接交互式地显示在客户端控制台上,不需要每次进行编译打包在集群环境中运行,目前该功能只支持使用Scala语言进行程序开发。另外需要注意的是在开发或者调试程序的过程中可以使用这种方式,但在正式的环境中则不建议使用。
环境支持
用户可以选择在不同的环境中启动Scala Shell,目前支持Local、Remote Cluster和Yarn Cluster模式,具体命令可以参考以下说明:
- 通过start-scala-shell.sh启动本地环境;
bin/start-scala-shell.sh local
- 可以启动远程集群环境,指定远程Flink集群的hostname和端口号;
bin/start-scala-shell.sh remote
- 启动Yarn集群环境,环境中需要含有hadoop客户端配置文件;
bin/start-scala-shell.sh yarn -n 2
运行程序
启动Scala Shell交互式解释器后,就可以进行Flink流式应用或批量应用的开发。需要注意的是,Flink已经在启动的执行环境中初始化好了相应的Environment,分别使用“benv”和“senv”获取批量计算环境和流式计算环境,然后使用对应环境中的API开发Flink应用。以下代码实例分别是用批量和流式实现WordCount的应用,读者可以直接在启动Flink Scala Shell客户端后执行并输出结果。
- 通过Scala-Shell运行批量计算程序,调用benv完成对单词数量的统计。
scala> val textBatch = benv.fromElements(
"To be, or not to be,--that is the question:--",
"Whether 'tis nobler in the mind to suffer")
scala> val counts = textBatch
.flatMap { _.toLowerCase.split("\\W+") }
.map { (_, 1) }.groupBy(0).sum(1)
scala> counts.print()
- 通过Scala-Shell运行流式计算,调用senv完成对单词数量的统计。
scala> val textStreaming = senv.fromElements(
"flink has Stateful Computations over Data Streams")
scala> val countsStreaming = textStreaming
.flatMap { _.toLowerCase.split("\\W+") }
.map { (_, 1) }.keyBy(0).sum(1)
scala> countsStreaming.print()
scala> senv.execute("Streaming Wordcount")
注意
用户在使用交互式解释器方式进行应用开发的过程中,流式作业和批量作业中的一些操作(例如写入文件)并不会立即执行,而是需要用户在程序的最后执行env.execute(“appname”)命令,这样整个程序才能触发运行。
Flink源码编译
对于想深入了解Flink源码结构和实现原理的读者,可以按照本节的内容进行Flink源码编译环境的搭建,完成Flink源码的编译,具体操作步骤如下所示。
Flink源码可以从官方 Git Repository上通过git clone命令下载:
git clone https://github.com/apache/flink
读者也可以通过官方镜像库手动下载,下载地址为这里。用户根据需要选择需要编译的版本号,下载代码放置在本地路径中,然后通过如下Maven命令进行编译,需要注意的是,Flink源码编译依赖于JDK和Maven的环境,且JDK必须在1.8版本以上,Maven必须在3.0版本以上,否则会导致编译出错。
mvn clean install -DskipTests
(1)Hadoop版本指定
Flink镜像库中已经编译好的安装包通常对应的是Hadoop的主流版本,如果用户需要指定Hadoop版本编译安装包,可以在编译过程中使用-Dhadoop.version参数指定Hadoop版本,目前Flink支持的Hadoop版本需要在2.4以上。
mvn clean install -DskipTests -Dhadoop.version=2.6.1
如果用户使用的是供应商提供的Hadoop平台,如Cloudera的CDH等,则需要根据供应商的系统版本来编译Flink,可以指定-Pvendor-repos参数来激活类似于Cloudera的Maven Repositories,然后在编译过程中下载依赖对应版本的库。
mvn clean install -DskipTests -Pvendor-repos -Dhadoop.version=2.6.1-cdh5.0.0
(2)Scala版本指定
Flink中提供了基于Scala语言的开发接口,包括DataStream API、DataSet API、SQL等,需要在代码编译过程中指定Scala的版本,因为Scala版本兼容性相对较弱,因此不同的版本之间的差异相对较大。目前Flink最近的版本基本已经支持Scala-2.11,不再支持Scala-2.10的版本,在Flink 1.7开始支持Scala-2.12版本,社区则建议用户使用Scala-2.11或者Scala-2.12的Scala环境。