基于OpenCL的图像积分图算法改进
复杂的算法却未必低效,简单的算法往往要付出代价,这个代价可能很大。在opencl环境下编程,与我们在CPU上的传统编程思想有一些差异,这些差异看似微不足道,但往往是细节决定成功,就是这些看似微不足道的差异,在多核的GPU上被无限放大,导致同一种算法在GPU和CPU运行效果有着巨大的差别。
之前写过一篇文章《基于OpenCL的图像积分图算法实现》介绍了opencl中积分图算法的基本原理(不了解积分图概念的朋友可以先参考这篇文章),并基于这个基本原理提供了kernel实现代码.但经过这两个月的实践检验,原先这个基于前缀和计算加矩阵转置的算法被证明在GPU上是非常低效的。
为什么呢?从根本上来说,之前的算法不符合并行计算所要求的分治原则,每个kernel一次循环处理一整行数据,相着挺简单,真正执行的时候,并不快。
下图是原来的算法在CodeXL GPU performance counters的记录结果。一次积分图计算的总执行时间在1.6ms左右
![]()
注:为了提高效率这里的kernel代码基于前一篇文章的算法上有改进,将前经和计算和矩阵转置合并为一个名为prefix_sum_col_and_transpose的kernel,没有改进前的算法更慢数倍。
于是我参考了OpenCLIPP的积分图算法思路,重写了自己的代码,新的算法思路是这样的:
整个算法分为5个步骤(kernel)来完成。
第一步(integral_block)将整个图像分为4x4的小块,分别计算局部积分图。

第二步(intergral_scan_v),纵向扫描计算前一步每个4x4块最后一组数据的前缀和矩阵vert。

第三步(intergral_combine_v),结合前面两步的结果将纵向互不关联的4x4块在纵向上连接起来。
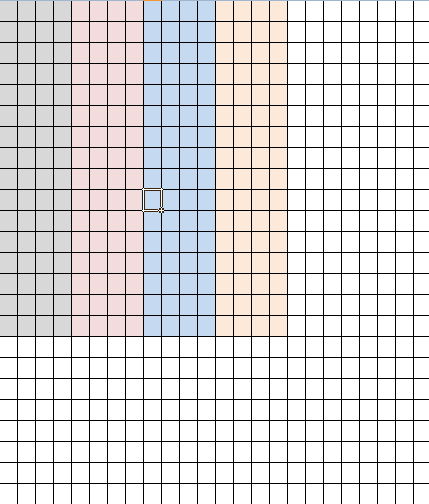
第四步(intergral_scan_h),横向扫描计算前一步每个4x4块最后一组数据的前缀和矩阵horiz。
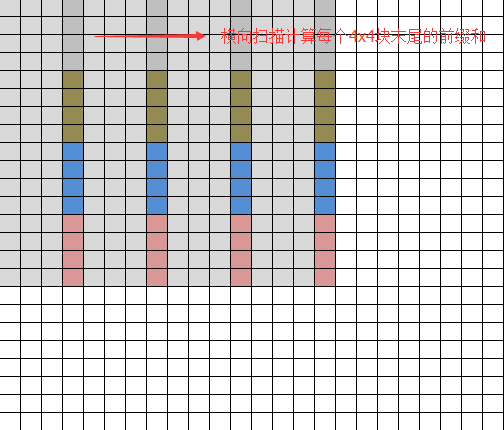
第五步(intergral_combine_h),结合前面两步的结果将横向互不关联的4x4块在横向上连接起来,就形成了一幅完整的积分图。
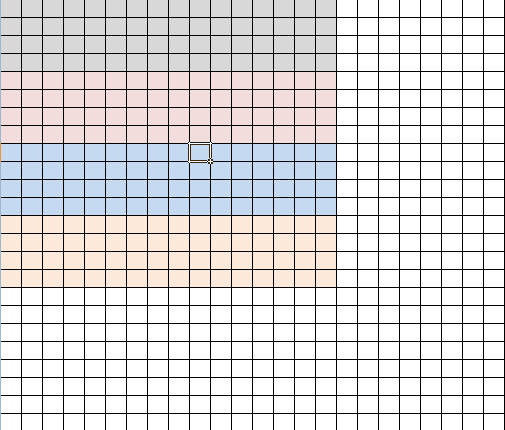
这个算法思路与之前的算法相比,没有了耗时的矩阵转置过程,但分为5步,更复杂了,实际的执行效果呢?出乎我的意料:5个kernel加起来的总时间是0.63ms左右,相比原来的算法提高了近3倍。

下面是完整的kernel代码
///////////////////////////////////////////////////////////////////////////////
//! @file : integral_gpu.cl
//! @date : 2016/05/08
//! @author: guyadong
//! @brief : Calculates the integral sum scan of an image
////////////////////////////////////////////////////////////////////////////////
#include "common_types.h"
#ifndef CL_DEVICE_LOCAL_MEM_SIZE
#error not defined CL_DEVICE_LOCAL_MEM_SIZE by complier with options -D
#endif
#ifndef SRC_TYPE
#error not defined SRC_TYPE by complier with options -D
#endif
#ifndef DST_TYPE
#error not defined DST_TYPE by complier with options -D
#endif
#ifndef INTEG_TYPE
#error not defined INTEG_TYPE by complier with options -D
#endif
#define V_TYPE 4
#define SHIFT_NUM 2
#define LOCAL_BUFFER_SIZE (CL_DEVICE_LOCAL_MEM_SIZE/sizeof(DST_TYPE))
#define _KERNEL_NAME(s,d,t) prefix_sum_col_and_transpose_##s##_##d##_##t
#define KERNEL_NAME(s,d,t) _KERNEL_NAME(s,d,t)
#define _KERNEL_NAME_INTEGRAL_BLOCK(s,d,t) integral_block_##s##_##d##_##t
#define KERNEL_NAME_INTEGRAL_BLOCK(s,d,t) _KERNEL_NAME_INTEGRAL_BLOCK(s,d,t)
#define _KERNEL_NAME_SCAN_V(s) integral_scan_v_##s
#define KERNEL_NAME_SCAN_V(s) _KERNEL_NAME_SCAN_V(s)
#define _KERNEL_NAME_COMBINE_V(s) integral_combine_v_##s
#define KERNEL_NAME_COMBINE_V(s) _KERNEL_NAME_COMBINE_V(s)
#define _KERNEL_NAME_SCAN_H(s) integral_scan_h_##s
#define KERNEL_NAME_SCAN_H(s) _KERNEL_NAME_SCAN_H(s)
#define _KERNEL_NAME_COMBINE_H(s) integral_combine_h_##s
#define KERNEL_NAME_COMBINE_H(s) _KERNEL_NAME_COMBINE_H(s)
#define _kernel_name_scan_v KERNEL_NAME_SCAN_V(DST_TYPE)
#define _kernel_name_scan_h KERNEL_NAME_SCAN_H(DST_TYPE)
#define _kernel_name_combine_v KERNEL_NAME_COMBINE_V(DST_TYPE)
#define _kernel_name_combine_h KERNEL_NAME_COMBINE_H(DST_TYPE)
#define VECTOR_SRC VECTOR(SRC_TYPE,V_TYPE)
#define VECTOR_DST VECTOR(DST_TYPE,V_TYPE)
#define VLOAD FUN_NAME(vload,V_TYPE)
#if INTEG_TYPE == INTEG_SQUARE
#define compute_src(src) src*src
#define _kernel_name_ KERNEL_NAME(SRC_TYPE,DST_TYPE,integ_square)
#define _kernel_name_integral_block KERNEL_NAME_INTEGRAL_BLOCK(SRC_TYPE,DST_TYPE,integ_square)
#elif INTEG_TYPE == INTEG_COUNT
#define compute_src(src) ((DST_TYPE)0!=src?(DST_TYPE)(1):(DST_TYPE)(0))
#define _kernel_name_ KERNEL_NAME(SRC_TYPE,DST_TYPE,integ_count)
#define _kernel_name_integral_block KERNEL_NAME_INTEGRAL_BLOCK(SRC_TYPE,DST_TYPE,integ_count)
#elif INTEG_TYPE == INTEG_DEFAULT
#define compute_src(src) src
#define _kernel_name_ KERNEL_NAME(SRC_TYPE,DST_TYPE,integ_default)
#define _kernel_name_integral_block KERNEL_NAME_INTEGRAL_BLOCK(SRC_TYPE,DST_TYPE,integ_default)
#else
#error unknow INTEG_TYPE by complier with options -D
#endif
///////////////////////////////////////////////////////////////////////////////
//! @brief : Calculates the integral of an image
////////////////////////////////////////////////////////////////////////////////
#define __SWAP(a,b) swap=a,a=b,b=swap;
// 4x4矩阵转置
inline void transpose( VECTOR_DST m[V_TYPE] ){
DST_TYPE swap;
__SWAP(m[0].s1,m[1].s0);
__SWAP(m[0].s2,m[2].s0);
__SWAP(m[0].s3,m[3].s0);
__SWAP(m[1].s2,m[2].s1);
__SWAP(m[1].s3,m[3].s1);
__SWAP(m[2].s3,m[3].s2);
}
// 计算4x4的局部积分图
__kernel void _kernel_name_integral_block( __global SRC_TYPE *sourceImage, __global VECTOR_DST * dest, __constant integ_param* param){
int pos_x=get_global_id(0)*V_TYPE,pos_y=get_global_id(1)*V_TYPE;
if(pos_x>=param->width||pos_y>=param->height)return;
int count_x=min(V_TYPE,param->width -pos_x);
int count_y=min(V_TYPE,param->height-pos_y);
VECTOR_DST sum;
VECTOR_DST matrix[V_TYPE];
// 从原矩阵加载数据,并转为目标矩阵的数据向量类型(VECTOR_DST),
//比如原矩阵是uchar,目标矩阵是float
matrix[0]= 00,sourceImage+(pos_y+0)*param->src_width_step+pos_x))
:(count_x==1?(VECTOR_DST)(VCONVERT(VECTOR_DST,)(VLOAD(0,sourceImage+(pos_y+0)*param->src_width_step+param->width-V_TYPE)).w,0,0,0)
:(count_x==2?(VECTOR_DST)(VCONVERT(VECTOR_DST,)(VLOAD(0,sourceImage+(pos_y+0)*param->src_width_step+param->width-V_TYPE)).zw,0,0)
:(VECTOR_DST)(VCONVERT(VECTOR_DST,)(VLOAD(0,sourceImage+(pos_y+0)*param->src_width_step+param->width-V_TYPE)).yzw,0)
)
):0;
matrix[1]= 10,sourceImage+(pos_y+1)*param->src_width_step+pos_x))
:(count_x==1?(VECTOR_DST)(VCONVERT(VECTOR_DST,)(VLOAD(0,sourceImage+(pos_y+1)*param->src_width_step+param->width-V_TYPE)).w,0,0,0)
:(count_x==2?(VECTOR_DST)(VCONVERT(VECTOR_DST,)(VLOAD(0,sourceImage+(pos_y+1)*param->src_width_step+param->width-V_TYPE)).zw,0,0)
:(VECTOR_DST)(VCONVERT(VECTOR_DST,)(VLOAD(0,sourceImage+(pos_y+1)*param->src_width_step+param->width-V_TYPE)).yzw,0)
)
):0;
matrix[2]= 20,sourceImage+(pos_y+2)*param->src_width_step+pos_x))
:(count_x==1?(VECTOR_DST)(VCONVERT(VECTOR_DST,)(VLOAD(0,sourceImage+(pos_y+2)*param->src_width_step+param->width-V_TYPE)).w,0,0,0)
:(count_x==2?(VECTOR_DST)(VCONVERT(VECTOR_DST,)(VLOAD(0,sourceImage+(pos_y+2)*param->src_width_step+param->width-V_TYPE)).zw,0,0)
:(VECTOR_DST)(VCONVERT(VECTOR_DST,)(VLOAD(0,sourceImage+(pos_y+2)*param->src_width_step+param->width-V_TYPE)).yzw,0)
)
):0;
matrix[3]= 30,sourceImage+(pos_y+3)*param->src_width_step+pos_x))
:(count_x==1?(VECTOR_DST)(VCONVERT(VECTOR_DST,)(VLOAD(0,sourceImage+(pos_y+3)*param->src_width_step+param->width-V_TYPE)).w,0,0,0)
:(count_x==2?(VECTOR_DST)(VCONVERT(VECTOR_DST,)(VLOAD(0,sourceImage+(pos_y+3)*param->src_width_step+param->width-V_TYPE)).zw,0,0)
:(VECTOR_DST)(VCONVERT(VECTOR_DST,)(VLOAD(0,sourceImage+(pos_y+3)*param->src_width_step+param->width-V_TYPE)).yzw,0)
)
):0;
sum=0;
//4x4矩阵纵向前缀和计算
sum+=compute_src(matrix[0]),matrix[0]=sum;
sum+=compute_src(matrix[1]),matrix[1]=sum;
sum+=compute_src(matrix[2]),matrix[2]=sum;
sum+=compute_src(matrix[3]),matrix[3]=sum;
// 转置矩阵
transpose(matrix);
sum=0;
//4x4矩阵横向前缀和计算
sum+=matrix[0],matrix[0]=sum;
sum+=matrix[1],matrix[1]=sum;
sum+=matrix[2],matrix[2]=sum;
sum+=matrix[3],matrix[3]=sum;
// 第二次转置矩阵,将矩阵方向恢复正常
transpose(matrix);
// 计算结果将数据写到目标矩阵
if(00)*param->dst_width_step+pos_x)/V_TYPE]=matrix[0];
if(11)*param->dst_width_step+pos_x)/V_TYPE]=matrix[1];
if(22)*param->dst_width_step+pos_x)/V_TYPE]=matrix[2];
if(33)*param->dst_width_step+pos_x)/V_TYPE]=matrix[3];
}
#undef __SWAP
// 将第一个kernel计算的结果(4x4分块的局部积分图)作为输入输入矩阵(dest)
// 计算每个4x4块纵向结尾数据的前缀和,存入vert
__kernel void _kernel_name_scan_v( __global DST_TYPE * dest, __constant integ_param* param,__global DST_TYPE *vert,int vert_step){
int gid_y=get_global_id(0);
if(gid_y>=param->height)return;
DST_TYPE sum=0;
int dst_width_step=param->dst_width_step;
for(int x=V_TYPE-1,end_x=param->width;x// 将上第一个kernel计算的结果(4x4分块的局部积分图)作为输入输入矩阵(dest)
// 将上第二个kernel计算的分组前缀和作为输入输入矩阵(vert)
// 对dest每个4x4块数据加上vert对应的上一组增量,结果输出到dest_out
__kernel void _kernel_name_combine_v( __global VECTOR_DST * dest, __constant integ_param* param,__global DST_TYPE *vert,int vert_step,__global VECTOR_DST * dest_out){
int gid_x=get_global_id(0),gid_y=get_global_id(1);
if(gid_x*V_TYPE>=param->width||gid_y>=param->height)return;
int dest_index=(gid_y*param->dst_width_step)/V_TYPE+gid_x;
VECTOR_DST m = dest[dest_index];
m += (VECTOR_DST)(gid_x>=1 ? vert[ gid_y*vert_step + gid_x-1]:0);
dest_out [dest_index]=m;
}
// 将上一个kernel计算的结果(4x4分块的局部积分图)作为输入输入矩阵(dest)
// 计算每个4x4块横向结尾数据的前缀和,存入horiz
__kernel void _kernel_name_scan_h( __global VECTOR_DST * dest, __constant integ_param* param,__global VECTOR_DST *horiz,int horiz_step){
int gid_x=get_global_id(0);
if(gid_x*V_TYPE>=param->width)return;
VECTOR_DST sum=0;
int dst_width_step=param->dst_width_step;
for(int y=V_TYPE-1,end_y=param->height;y// 将第三个kernel计算的结果作为输入输入矩阵(dest)
// 将第四个kernel计算的分组前缀和作为输入输入矩阵(vert)
// 对dest每个4x4块数据加上horiz对应的上一组增量,结果输出到dest_out
// dest_out就是最终的积分图
__kernel void _kernel_name_combine_h( __global VECTOR_DST * dest, __constant integ_param* param,__global VECTOR_DST *horiz,int horiz_step,__global VECTOR_DST * dest_out){
int gid_x=get_global_id(0),gid_y=get_global_id(1);
if(gid_x*V_TYPE>=param->width||gid_y>=param->height)return;
VECTOR_DST m;
int dest_index=(gid_y*param->dst_width_step)/V_TYPE+gid_x;
m = dest[dest_index];
m += gid_y>=V_TYPE?horiz[((gid_y/V_TYPE)-1)*horiz_step/V_TYPE + gid_x ]:(DST_TYPE)0;
dest_out[dest_index]=m;
} common_types.h
/* * common_types.h * * Created on: 2016年4月14日 * Author: guyadong */
#ifndef FACEDETECT_CL_FILES_COMMON_TYPES_H_
#define FACEDETECT_CL_FILES_COMMON_TYPES_H_
#ifdef __OPENCL_VERSION__
typedef char cl_char;
typedef uchar cl_uchar;
typedef short cl_short;
typedef ushort cl_ushort;
typedef int cl_int;
typedef uint cl_uint;
typedef long cl_long;
typedef ulong cl_ulong;
typedef double cl_double;
typedef float cl_float;
typedef char2 cl_char2;
typedef char4 cl_char4;
typedef char8 cl_char8;
typedef char16 cl_char16;
typedef uchar2 cl_uchar2;
typedef uchar4 cl_uchar4;
typedef uchar8 cl_uchar8;
typedef uchar16 cl_uchar16;
typedef short2 cl_short2;
typedef short4 cl_short4;
typedef short8 cl_short8;
typedef short16 cl_short16;
typedef ushort2 cl_ushort2;
typedef ushort4 cl_ushort4;
typedef ushort8 cl_ushort8;
typedef ushort16 cl_ushort16;
typedef int2 cl_int2;
typedef int4 cl_int4;
typedef int8 cl_int8;
typedef int16 cl_int16;
typedef uint2 cl_uint2;
typedef uint4 cl_uint4;
typedef uint8 cl_uint8;
typedef uint16 cl_uint16;
typedef long2 cl_long2;
typedef long4 cl_long4;
typedef long8 cl_long8;
typedef long16 cl_long16;
typedef ulong2 cl_ulong2;
typedef ulong4 cl_ulong4;
typedef ulong8 cl_ulong8;
typedef ulong16 cl_ulong16;
typedef float2 cl_float2;
typedef float4 cl_float4;
typedef float8 cl_float8;
typedef float16 cl_float16;
typedef double2 cl_double2;
typedef double4 cl_double4;
typedef double8 cl_double8;
typedef double16 cl_double16;
#ifdef NDEBUG
#define DEBUG_LOG(format, ...)
#else
#define DEBUG_LOG(format, ...) printf((__constant char*)format, __VA_ARGS__)
#endif
#define LOG(format, ...) printf((__constant char*)format, __VA_ARGS__)
#ifndef NULL
#define NULL 0
#endif
#define _VECTOR(t,n) t##n
#define VECTOR(t,n) _VECTOR(t,n)
#define _FUN_NAME(f,n) f##n
#define FUN_NAME(f,n) _FUN_NAME(f,n)
#define _FUN_NAME2(f,n,s) f##_##n##s
#define FUN_NAME2(f,n,s) _FUN_NAME2(f,n,s)
#define VCONVERT(vtype,suffix) FUN_NAME2(convert,vtype,suffix)
#define VCONVERT_SAT(vtype) VCONVERT(vtype,_sat)
#define VAS(vtype) FUN_NAME2(as,vtype,)
#define ALIGN_UP(v,a) ((v+(1<>a<
//denominator/numerator
#define CEIL_DIV(d,n) (((d)+(n)-1)/(n))
#endif
// define alignment macro for data struct crossed between host & device
#ifdef _MSC_VER
#define _CL_CROSS_ALIGN_(n) __declspec( align(n) )
#elif __GNUC__
#define _CL_CROSS_ALIGN_(n) __attribute__((aligned(n)))
#elif __cplusplus>=201103L
#define _CL_CROSS_ALIGN_(n) alignas(n)
#elif __OPENCL_VERSION__
#define _CL_CROSS_ALIGN_(n) __attribute__((aligned(n)))
#else
#warning Need to implement some method to align data here
#define _CL_CROSS_ALIGN_(n)
#endif /*_MSC_VER*/
// define column num of each work-item working for integral kernel,
// is also equivalent to the number of local work-items so sad get_local_size(0)
#define INTEGRAL_COLUMN_STEP 16
#define IMGSCALE_LOCAL_SIZE 64
/* get divisor for len/num */
inline size_t gf_get_divisor(size_t len,size_t num){
return (size_t)(len/num+(int)(len%num>0));
}
typedef struct _integ_param {
cl_int width,height,src_width_step,dst_width_step;
}integ_param;
typedef struct _matrix_info_cl {
cl_uint width ;
cl_uint height ;
cl_uint row_stride;
/* #ifdef __cplusplus _matrix_info_cl(size_t width,size_t height,size_t row_stride=0):width(cl_uint(width)), height(cl_uint(width)),row_stride( cl_uint(row_stride? row_stride:width)) {} _matrix_info_cl() = default; _matrix_info_cl(const _matrix_info_cl&) = default; _matrix_info_cl(_matrix_info_cl&&) = default; _matrix_info_cl& operator=(const _matrix_info_cl&) = default; _matrix_info_cl& operator=(_matrix_info_cl&&) = default; #endif */
}matrix_info_cl;
// define integral matrix type
// default intergal matrix
#define INTEG_DEFAULT 0
// intergal matrix for suquare
#define INTEG_SQUARE 1
// integral matrix for count of no zero
#define INTEG_COUNT 2
typedef enum _integral_type{
integ_default=INTEG_DEFAULT
,integ_square=INTEG_SQUARE
,integ_count=INTEG_COUNT
}integral_type;
#endif /* FACEDETECT_CL_FILES_COMMON_TYPES_H_ */