理解ResNet
理解ResNet
文章目录
- 理解ResNet
- 一、ResNet回顾
- 1.1
- 1.2
- 二、传统网络的理解
- 三、理解方式一:Ensembles of Relatively Shallow Networks
- 实验一:在测试时去掉某一个block
- 实验二:在测试时去掉多个block
- 实验三:在测试时重新调整block的位置
- 三、理解方式二:Unrolled Iterative Estimation
- 四、总结
本篇内容主要讲两种理解ResNet的方式。一种是“ensembles of relatively shallow networks”,另一种是“unrolled iterative estimation”。
涉及到的论文
Deep Residual Learning for Image Recognition
Identity Mappings in Deep Residual Networks
Residual Networks Behave Like Ensembles of Relatively Shallow Networks
Highway and Residual Networks learn Unrolled Iterative Estimation
一、ResNet回顾
1.1

上图就是15年“Deep Residual Learning for Image Recognition” Kaiming He提出的Residual Blocks。

在此之上,对于更加深的网络,会对residual block进行一定的改进,如上图右边先使用1*1的卷积来减小channel数量,再使用1*1卷机增加channel数量,以此控制3*3卷积的参数的数量,使网络能变得更深。
“Solely due to our extremely deep representation…“,这就是作者觉得为何ResNet效果更好的原因。因为residual block 可以让网络变深,而网络变深使得效果变好。
1.2
在16年,还是由Kaiming He提出了更进一步的版本。“Identity Mappings in Deep Residual Networks”
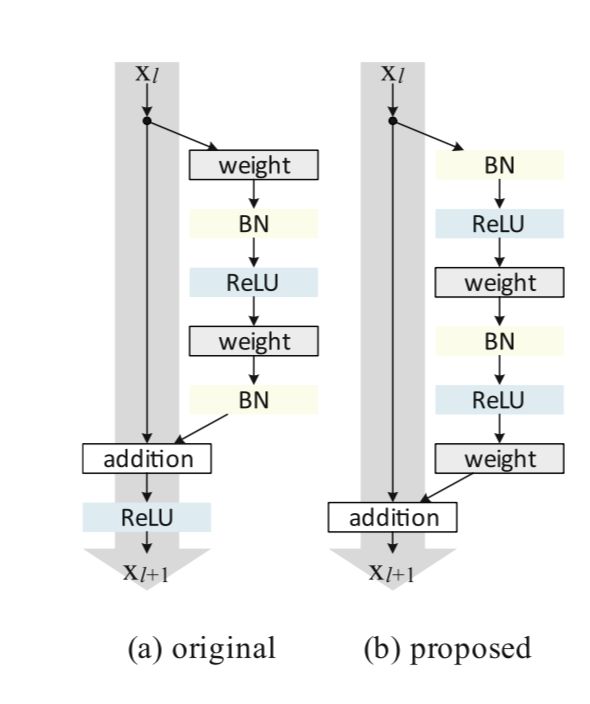
这篇文章主要就是将下图左边original的版本改为右图的版本。可以看到主要的改变就是BN和Relu位置的变化。
“If both h(x) and f(y) are identity mappings, the signal could be directly propagated from one unit to any other units, in both forward and backward passes. ”
具体的推导如下。
y l = h ( x l ) + F ( x l , W l ) y_l=h(x_l)+F(x_l, W_l) yl=h(xl)+F(xl,Wl)
x l + 1 = f ( y l ) x_{l+1}=f(y_l) xl+1=f(yl)
上面这两条公式就是residual block的公式。在上图original部分F函数代表的是卷积层(conv,BN,Relu等),h函数代表的是identity link,即h(x)=x,f函数代表的是两条路相加后的Relu操作。如果让h和f都为identity mapping,那么可以推出
x l + 2 = x l + 1 + F ( x l + 1 , W l + 1 ) = x l + F ( x l , W l ) + F ( x l + 1 , W l + 1 ) x_{l+2}=x_{l+1}+F(x_{l+1},W_{l+1})=x_l+F(x_l,W_l)+F(x_{l+1}, W_{l+1}) xl+2=xl+1+F(xl+1,Wl+1)=xl+F(xl,Wl)+F(xl+1,Wl+1)
Forward: x L = ∑ i = l L − 1 F ( x i , W i ) x_L=\sum_{i=l}^{L-1}F(x_i,W_i) xL=∑i=lL−1F(xi,Wi)
Backward: ∂ ε ∂ x l = ∂ ε ∂ x L ∂ x L ∂ x l = ∂ x L ( 1 + ∂ x l ∑ i = l L − 1 F ( x i , W i ) ) \frac{\partial\varepsilon}{\partial x_l}=\frac{\partial\varepsilon}{\partial x_L}\frac{\partial x_L}{\partial x_l}=\frac{\partial}{x_L}(1+\frac{\partial}{x_l}\sum_{i=l}^{L-1}F(x_i, W_i)) ∂xl∂ε=∂xL∂ε∂xl∂xL=xL∂(1+xl∂∑i=lL−1F(xi,Wi))
从中可以看出,在forward阶段,任意的l层的信息可以直接连到任意L层。在backward阶段,任意的L层的梯度可以直接传回第l层。
二、传统网络的理解
传统网络主流理解是representation view。低层的layer提取低级别的特征,而高层layer提取高级别的特征。如论文Visualizaing and Understanding Convolutional Networks中的图

接下来的部分,就介绍两种理解ResNet的方式。
三、理解方式一:Ensembles of Relatively Shallow Networks
这篇文章的作者发现,将已经训练好的ResNet,在测试时去掉一些residual block,并不会有太大影响。而这个现象是和普通的网络有很大的区别的,因为传统分层网络结构每一层的处理过程严格依赖上一层的输出。为了解释这一现象,作者对resnet做了以下的分析。

如上图的3个block相连,可以做如下的推导
y 3 = y 2 + f 3 ( y 2 ) = [ y 1 + f 2 ( y 1 ) ] + f 3 ( y 1 + f 2 ( y 1 ) ) = [ y 0 + f 1 ( y 0 ) + f 2 ( y 0 + f 1 ( y 0 ) ) ] + f 3 ( y 0 + f 1 ( y 0 ) + f 2 ( y 0 + f 1 ( y 0 ) ) ) y_3=y_2+f_3(y_2)=[y_1+f_2(y_1)]+f_3(y_1+f_2(y_1)) \\ =[y_0+f_1(y_0)+f_2(y_0+f_1(y_0))]+f_3(y_0+f_1(y_0)+f_2(y_0+f_1(y_0))) y3=y2+f3(y2)=[y1+f2(y1)]+f3(y1+f2(y1))=[y0+f1(y0)+f2(y0+f1(y0))]+f3(y0+f1(y0)+f2(y0+f1(y0)))
那么3个block相连的结构就可以分解为下图这样由8条不同支路组合得到的网络。
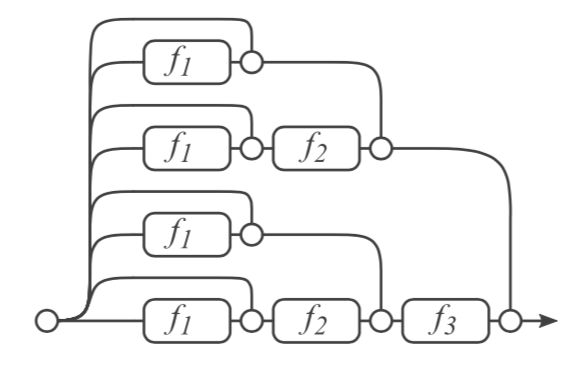
如果有n个block,那么就有 2 n − 1 2^{n-1} 2n−1个不同的支路。一条支路经过的f函数的个数记为支路的长度,那么我们可以看出不同支路有着不一样的长度。在上图中有长度为0、1、2、3的支路。
为了证明这种理解方式的正确性,作者做了以下几个实验。在这些实验中,作者使用54个block组成的网络。
实验一:在测试时去掉某一个block
比如将上图中f_2去掉,那么分解后的图如下所示。

实验结果如下。
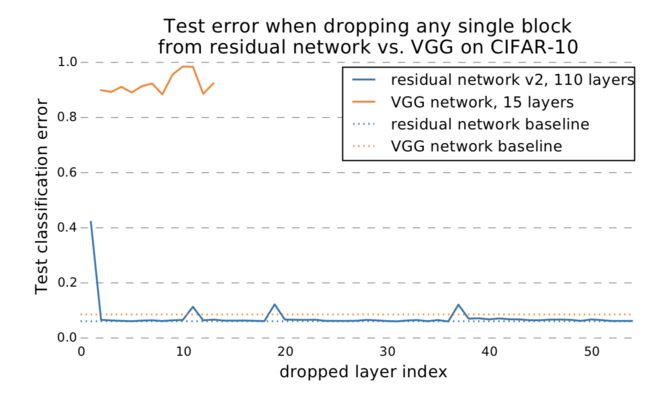
从实验结果中可以看出,去掉一个block,对test error并不会有很大影响。具体的实验结果分析可以看论文。而没有residual block的网络,比如图上的VGG网络,如果去掉一层,则会造成很大的影响。
而这种现象的原因是:从分解后的图中可以看出,去掉f2函数,只是将这所有支路中的某些支路去掉,但还保留了其他一些支路,因此不会对最终效果有很大影响。
“This result suggests that paths in a residual network do not strongly depend on each other although they are trained jointly. ”
实验二:在测试时去掉多个block
在测试时,去掉不同数量的block。
因为ensemble模型的一个表现是随着去掉的模型数量增多,测试错误率会逐渐提升。而从下图的实验结果来看,有着与ensemble相同的表现形式,因此作者认为resnet是ensemble-like。

实验三:在测试时重新调整block的位置
随机交换网络中一对blocks,甚至可以交换k对blocks。这个实验发现交换两个block后,效果也不会有很大的恶化,而且随着k值的增加,test error缓慢增加。
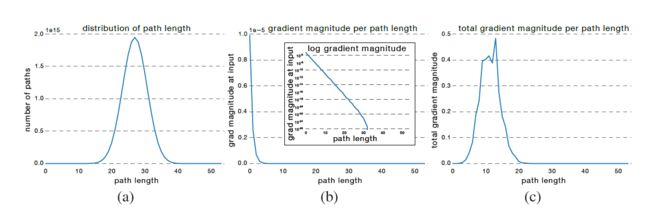
除了以上三个实验,论文中经过其他实验后发现,在resnet中,其实是较短的支路对网络的训练影响较大。在文章之前已经说过并不是网络中所有的路径都是相同的,仅有一条路径会经过所有的模块,n条路径仅仅通过一个module,因为路径的长度服从二项分布。如下图中最左边的图所示。通过统计,网络的路径长度集中在n/2处附近(19-35层)。同时也观察了不同路径长度网络在梯度回传时传到第一层的值,即中间这幅图。将左和中这两幅图相乘,就可以得到右边这幅图。这幅图说明在梯度回传时,长度在11附近的支路所做的贡献最大。
三、理解方式二:Unrolled Iterative Estimation
在这篇论文中,作者将一个resnet分为多个stage,每个stage中有多个block。一个stage中的block的feature map是相同大小的,而不同stage间的feature map是不同大小的,如下图所示。
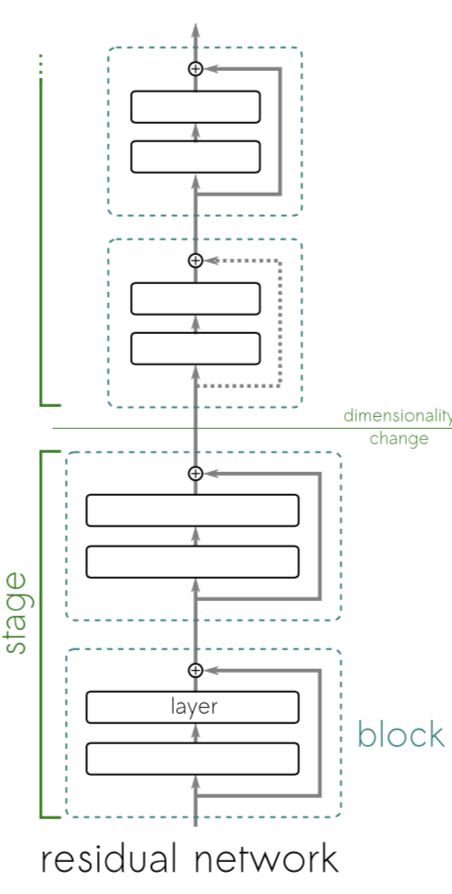
这篇文章的理解方式为:一个stage中的每个block并没有计算得到一个不同级别的特征,而是,一个stage中的第一个block就已经得到了一个粗略的特征,而同一个stage中之后的block是来提升这些特征的质量的。(“Functional blocks in these networks do not compute entirely new representations; instead, they engage in an unrolled iterative estimation of representations that refine/improve upon their input representation.”)
“The first layer already computes a rough estimate of that representation, which is then iteratively refined by the successive layers. ”
下面这张图是在一个stage中三个block的“top nine activating patches”,可以看出这三张图基本相似,也有一定的改变。

文章中有对这种理解方式给出数学上的解释和推导,具体请看论文。假如接受了这种设定,或者说理解方式,那么就可以根据这种理解对resnet区别与普通CNN的特殊表现进行解释。
第一个表现是,resnet在测试时去掉一些层不会有很大影响。按照这种理解方式,这是因为在一个stage中第一个block之后的block只是进行一些refine的操作,因此去掉一个stage中的一层,不会影响下一层接收到的特征的level,只是会影响质量。
第二个表现是,重新排序resnet中的一些层,也就是随机交换两层的位置不会对最终效果有很大影响时。因为一个stage中的的不同block work with the same input and output representations。
四、总结
以上两种方式都与传统的representation view有些不同,较好的解释了resnet出现的与传统的CNN不同的现象。当然作者也在文中说了“this view is incomplete and does not adequately explain
several recent findings”,不过这两种理解算是帮助扫除了一些resnet的疑惑。