数据分析 NO.9 python进阶深入
第十二~十三天:python进阶深入
1.生成器:创建生成器最简单的方法就是用圆括号()代替方括号 []
把列表生成式的 [ ] 变成()
生成器只能调用一次,不占用资源。用完就释放出来。
for i in g:
print(i)
也可以调用Next函数直到计算出最后一个元素位置,但是这种方法很明显不适用,并且最后会抛出StopIteration的错误。
斐波那契数列:除第一个和第二个数外,任意一个数都可由前两个数相加得到:
1, 1, 2, 3, 5, 8, 13, 21, 34, …
return返回的是具体的数值
yield返回的是一个生成器
递归的思路代码:
def fib(n_position):
if n_position == 1 or n_position ==2:
return 1
return fib(n_position - 1 ) + fib(n_position -2)
2.迭代器:
可用于for循环的对象统称为可迭代对象:Iterable。包括之前学的list,tuple等数据结构以及生成器。 但是生成器不仅可以被for循环调用, 还可以使用next函数获取元素,可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator
isinstance(g,Iterator) 判断g 是不是后面类似返回True or False
3.函数式编程
高阶函数:
函数名也是变量,
既然变量可以指向函数,函数可以接受变量,那么一个函数就可以接受另一个函数作为传入参数,拿来使用
def add(x,y,z):
return z(x) + z(y)
add([1,2,3,4],[4,3,1,5,6],len)
4.map/reduce
map接受两个参数,一个是函数,一个是Iterable,函数作用在序列的每一个元素上,并把结果作为Iterable返回
x=[1,2,3,4,5,6,7,8,9,10]
map(lambda s:s*s,x)
list(map(lambda s:s*s,x))
reduce也是把函数作用与序列上,但是这个函数必须接受两个参数,reduce把计算结果继续与下一个元素做累积计算
from functools import reduce
reduce(lambda a,b:a*b,x)
5.filter函数:
filter也是把函数作用在序列元素上,但是该函数返回的结果必须是布尔型,filter根据true或者false进行元素的保留和删除
x = [1,3,6,7,2,19,20,33,29,10,49]
list(filter(lambda s : s%2 ==0,x))
6.匿名函数 Lambda
f=lambda s:s*2
x=[1,2,3,4]
map(f,x)
f=lambda a,b:(a+b)*2
x=[1,2,3]
y=[2,3,4]
list(map(f,x,y))
7.面向对象
类里面一般包含属性和方法,你可以简单理解为属性为静态,方法是动态的。比如人(PERSON)这个类,嘴、手、腿就是类的属性,跑步、吃饭等就是累的方法。
我们可以把在创建实例时我们认为必须绑定的属性强制填写进去,这里通过 init 方法完成。init 方法的第一个参数永远是self,代表了实例本身。有了该方法之后,在创建的实例的时候必须强制指定属性值,否则会报错。该方法也可以理解为初始化的一个动作,在创建实例的时候初始化该实例的一些属性!
前后都是两个下划线
下面的S是的大写,如果是多个单词组合,每个单词第一个字母大写(编写规范)
class Student:
def __init__(self,student_id,address,score):
self.staudent_id = staudent_id
self.address = address
self.score = score
self.name = student_name
self.gender = "female"
def getId(self):
print(self.student_id)
#创建实例
student = Student(1020202,"北京",98,"xiaoming")
必须把()里面参数填满
class Student:
kind = "Chinese" # Shared by all instances
def __init__(self,id,address,score):
self.id = id
self.address = address
self.score = score
def getId(self):
print(self.id)
print(self.kind)
def judge_age(self,age):
if age < 18:
return "未成年"
elif age < 30:
print("Student: {0}".format(self.id))
return "年轻人"
elif age < 60:
return "中年人"
else:
return "老年人"
S1 = Student(12324,"上海市",100)
S2 = Student(3245,"上海市",90)
# print(S1.kind)
# S1.judge_age(22)
上述程序中,kind是被所有的实例共享,只要是实例拥有的都要用self一下。
调用属性和方法都是通过 .
继承和多态:
面向对象编程语言连都会有继承的概念,我们可以定义一个class类,然后再定义它的子类,这个子类继承了上面的类,被继承的类称作父类
class HighSchool(Student):
pass
Highschool类集成了Student类,student类就是父类。
继承的好处就是子类可以享用父类的全部方法和属性。虽然HighSchool什么也没定义,但是可以直接使用Student的方法
子类也可以由自己的初始化方法,一定要用 super().init(name, id) 去初始化父类
函数super()将返回当前类继承的父类,即 Student ,然后调用init()方法
class Student():
def __init__(self,name,id):
self.name = name
self.id = id
def student(self):
print("Student score!")
def get_name_id(self):
print(self.name +":" +self.id)
class HighSchool(Student):
def __init__(self,name,id,score):
super().__init__(name,id)
self.score=score
pass
如果在父类和子类的方法重复了,会首先使用我子类自己的方法
8.Collections类
8.1 deque:
deque 和list的用法比较类似,它是队列与栈的实现,可以对序列数据进行两端的操作。deque支持在O(1)的时间复杂度上对序列进行两端的append或者pop。list也可以实现同样的操作,但是它的复杂度是O(N)
O(N)复杂度
# 类似于列表实现
from collections import deque
a = deque(['a','b','c','d'])
a.append("e")
# a
a.pop()
# 两端操作
#a.popleft()
a.appendleft("a")
#反转
a.rotate()
对首端进行操作的话,用deque_a.appendleft("a")
8.2 counter
from collections import Counter
a = list('absgctsgabfxtdrafabstxrsg')
c = Counter(a)
# 查看TOPN的元素
c.most_common(5)
关于OrderedDict
本身不是对key或者value的大小进行排序,而是对存储的时候,人为定义好的插入的顺序进行保存。
from collections import OrderedDict
# regular unsorted dictionary
d = {'banana': 3, 'apple': 4, 'pear': 1, 'orange': 2}
# dictionary sorted by key
OrderedDict(sorted(d.items(), key=lambda t: t[0]))
# # dictionary sorted by value
OrderedDict(sorted(d.items(), key=lambda t: t[1]))
# # dictionary sorted by length of the key string
OrderedDict(sorted(d.items(), key=lambda t: len(t[0])))
od = OrderedDict(sorted(d.items(), key=lambda t: t[0]))
t[0]:key
t[1]:value
od.popitem(last = False)
False 去掉左端第一个,是True的话就是末尾
9.字符串处理
s.strip() 去掉首位两端的空格 延伸:.lstrip(),.rstrip()
s.find() s.find(“e”)返回e的索引位置,如果没有就会返回-1
s.find(“H”,1) 后面的1是启始位置,其实只要找的到了,是不影响索引位置。
s.startwith(“H”,1) 判断后面的索引位置开始的首字母是否是"H",返回True or False
s.endwith()
s.lower()
s.upper()
s.split(",") 切割,返回的一个列表。
map(lambda t : t.strip() , s.strip().upper().split(","))
10.格式化
for i in range(100):
t = str(i)
print("这是我打印的第 %s 个数字"%t)
下面这个看起来更简洁
a = "shanghai"
b = 39
print("今天 {0} 的气温是 {1}".format(a,b)) 根据索引的位置选
11.datetime
from datetime import datetime
print(datetime.now())
strptime(,)
# 字符串与时间的转换
s = '20170901'
s1 = datetime.strptime(s,'%Y%m%d')
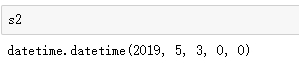
s = "2019/05/03"
s2 = datetime.strptime(s,'%Y/%m/%d')
返回结果:
timedelta
** timedelta **
class datetime.timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0)
from datetime import datetime.timedelta
s2 - s1
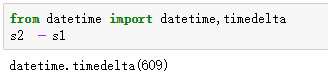
返回结果是609天,datetime用作减可以直接减
加的话是
s2+timedelta(3)
减可以是
s2-timedelta(3) 或 s2+timedelta(-3)
s2 + timedelta(hours = 10) + timedelta(weeks = 1)
s1.date() 只获取到日的节点
from datetime import datetime
s="2019-5-9"
s_test=datetime.strptime(s,"%Y-%m-%d")
s_test.day
12 I/O
读文件需要使用 open()函数,其参数为文件名与标识符:
f = open("file",'r')
data = f.read()
f.close()
读了文件一定要关闭文件。
可以使用with关键词进行整合:
with open("helloWorld.py",'r') as handle:
data = handle.readlines()
read()所有数据读取进来
readlines()一行一行读出来,
list(map(lambda s : s.strip(),data))
编码问题:添加encoding=
f = open("file",'r',encoding = 'gbk') # utf-8
数据写入:
写文件和读文件几乎一致,唯一的区别是标识符需要改为"w"。
第一个实参也是要打开的文件的名称; 第二个实参(‘w’)告诉Python,我们要以写入模式打开这个文件。打开文件时,可指定读取模 式(‘r’)、 写入模式(‘w’)、 **附加模式(‘a’)**或让你能够读取和写入文件的模式(‘r+’)。如果 你省略了模式实参, Python将以默认的只读模式打开文件
with open("test2.txt",'w') as handle:
handle.write("hello world")
如果你要写入的文件不存在,函数open()将自动创建它。然而,以写入(‘w’)模式打开文 件时千万要小心,因为如果指定的文件已经存在, Python将在返回文件对象前清空该文件。
with open("test.txt",'a') as handle:
handle.write("Today is Nice!\n")
handle.write("We are happy!!\n")
如果你要给文件添加内容,而不是覆盖原有的内容,可以附加模式打开文件。你以附加模式 打开文件时, Python不会在返回文件对象前清空文件,而你写入到文件的行都将添加到文件末尾。 如果指定的文件不存在, Python将为你创建一个空文件。
要写入多行的话。需要自己添加换号符 “\n”