求编辑距离
定义
编辑距离又称Leveinshtein距离,是由俄罗斯科学家Vladimir Levenshtein在1965年提出。编辑距离是计算两个文本相似度的算法之一,以字符串为例,字符串a和字符串b的编辑距离是将a转换成b的最小操作次数,这里的操作包括三种:
- 插入一个字符
- 删除一个字符
- 替换一个字符
举个例子,kitten和sitting的编辑距离是3,kitten -> sitten(k替换为s) -> sittin(e替换为i) -> sitting(插入g),至少要做3次操作。
实现
用 leva,b(i,j) 来表示a和b的Leveinshtein距离(i和j分别代表a和b的长度),则:
- 当min(i,j)=0时,leva,b(i,j)=max(i,j),一个字符串的长度为0,编辑距离自然是另一个字符串的长度
- 当ai=bj时,leva,b(i,j)=leva,b(i−1,j−1),比如xxcz和xyz的距离=xxc和xy的距离
- 否则,leva,b(i,j)为如下三项的最小值:
- leva,b(i−1,j)+1(删除ai),比如xxc和xyz的距离=xx和xyz的距离+1
- leva,b(i,j−1)+1(插入bj),比如xxc和xyz的距离=xxcz和xyz的距离+1=xxc和xy的距离+1
- leva,b(i−1,j−1)+1(替换bj),比如xxc和xyz的距离=xxz和xyz的距离+1=xx和xy的距离+1
用公式表示如下:
递归实现
用上面的公式可以很容易的写出递归实现:
public static int levenshteinDistance(String left, String right) {
return levenshteinDistance(left.toCharArray(), left.length(), right.toCharArray(), right.length());
}
private static int levenshteinDistance(char[] left, int leftLen, char[] right, int rightLen) {
if (Math.min(leftLen, rightLen) == 0) {
return Math.max(leftLen, rightLen);
}
if (left[leftLen - 1] == right[rightLen - 1]) {
return levenshteinDistance(left, leftLen - 1, right, rightLen - 1);
}
return Math.min(levenshteinDistance(left, leftLen - 1, right, rightLen),
Math.min(levenshteinDistance(left, leftLen, right, rightLen - 1),
levenshteinDistance(left, leftLen - 1, right, rightLen - 1))) + 1;
}递归的实现比较简单,递归的思想是通过递归的形式,最终得到一个由不可继续分割(递归出口)的式子组成的表达式,最终会存在非常多的重复的不可继续分割的式子,造成大量的重复计算,所以很低效。
动态规划实现
递归是从后向前分解,那与之相对的就是从前向后计算,逐渐推导出最终结果,此法被称之为动态规划,动态规划很适用于具有重叠计算性质的问题,但这个过程中会存储大量的中间计算的结果,一个好的动态规划算法会尽量减少空间复杂度。
全矩阵
以xxc和xyz为例,建立一个矩阵,通过矩阵记录计算好的距离:

当min(i,j)=0时,leva,b(i,j)=max(i,j) ,根据此初始化矩阵的第一行和第一列:
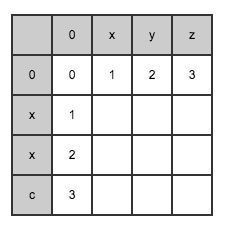
依据上面的公式可以继续推导出第二行:

继续迭代,直至推导出最终结果:

这个过程记录了所有中间结果,空间复杂度为 O(n2) ,来看一下代码实现:
public static int levenshteinDistance(String left, String right) {
// 创建矩阵
int[][] d = new int[left.length() + 1][right.length() + 1];
// 初始化第一列
for (int i = 0; i <= left.length(); i++) {
d[i][0] = i;
}
// 初始化第一行
for (int j = 1; j <= right.length(); j++) {
d[0][j] = j;
}
// 从第二行第二列开始迭代
for (int i = 1; i <= left.length(); i++) {
for (int j = 1; j <= right.length(); j++) {
// 套公式计算
if (left.charAt(i - 1) == right.charAt(j - 1)) {
d[i][j] = d[i - 1][j - 1];
} else {
d[i][j] = Math.min(d[i - 1][j], Math.min(d[i][j - 1], d[i - 1][j - 1])) + 1;
}
}
}
// 最后一个格子即为最终结果
return d[left.length()][right.length()];
}两行
空间复杂度可以继续优化,我们计算当前行时,只依赖上一行的数据,所以我们只需要 O(2n) 的空间复杂度,代码实现:
public static int levenshteinDistance3(String left, String right) {
int[] pre = new int[right.length() + 1];// 上一行
int[] current = new int[right.length() + 1];// 当前行
// 初始化第一行
for (int i = 0; i < pre.length; i++) {
pre[i] = i;
}
for (int i = 1; i <= left.length(); i++) {
current[0] = i;// 第一列
for (int j = 1; j <= right.length(); j++) {
// 套公式计算
if (left.charAt(i - 1) == right.charAt(j - 1)) {
current[j] = pre[j - 1];
} else {
current[j] = Math.min(current[j - 1], Math.min(pre[j], pre[j - 1])) + 1;
}
}
// current -> pre
System.arraycopy(current, 0, pre, 0, current.length);
}
return pre[pre.length - 1];
}单行
我们还可以进一步优化,其实只需要一行就可以了,计算当前格子时,只需要左、上、左上的值,左面的值可以直接得到,上面的值是当前格子修改前的旧值,也可以直接得到,左上角的值是左面格子修改前的旧值,需要暂存,这时空间复杂度为 O(n) 。

代码实现:
public static int levenshteinDistance(String left, String right) {
// 初始化当前行
int[] d = new int[right.length() + 1];
for (int i = 0; i < d.length; i++) {
d[i] = i;
}
int leftTop, nextLeftTop;
for (int i = 1; i <= left.length(); i++) {
leftTop = i - 1;// 当前行的左上角初始值
d[0] = i;// 第一列
for (int j = 1; j <= right.length(); j++) {
nextLeftTop = d[j];// 暂存,此时d[j]为上一行的值,也是d[j+1]左上角的值
// 套公式计算
if (left.charAt(i - 1) == right.charAt(j - 1)) {
d[j] = leftTop;
} else {
d[j] = Math.min(d[j - 1], Math.min(d[j], leftTop)) + 1;
}
leftTop = nextLeftTop;
}
}
return d[d.length - 1];
}应用
编辑距离是基于文本自身去计算,没有办法深入到语义层面,可以胜任一些简单的分析场景,如拼写检查、抄袭侦测等,在我的工作中,该算法在数据聚合时有一定的运用。
参考
https://en.wikipedia.org/wiki/Levenshtein_distance
http://www.dreamxu.com/books/dsa/dp/edit-distance.html
版权声明
本博客所有的原创文章,作者皆保留版权。转载必须包含本声明,保持本文完整,并以超链接形式注明作者高爽和本文原始地址:http://blog.csdn.net/ghsau/article/details/78903076。