Tensorflow学习笔记-基于LeNet5结构的ORL数据集人脸识别
参考文献:
《基于卷积神经网络的人脸识别研究》 李春利,柳振东,惠康华
文章中基于经典的网络LeNet-5的结构,提出了一种适用于ORL数据集的CNN结构,在该数据集上取得了较高的识别率。
本文是在参考此论文的基础上,使用tensorflow实现了文中相关理论。
ORL训练集byCSDN
训练集下载解压后可以看到,ORL训练集一共有40类,每一类有10张bmp类型的图片。

首先我们需要做的就是将这些数据读入,制作我们自己的训练集和测试集。
input_path = "./orl"
train_path = "./train"
test_path = "./test"
if not os.path.exists(train_path):
os.mkdir(train_path)
if not os.path.exists(test_path):
os.mkdir(test_path)
for i in range(1, 41):
if not os.path.exists(train_path + '/' + str(i)):
os.mkdir(train_path + '/' + str(i))
if not os.path.exists(test_path + '/' + str(i)):
os.mkdir(test_path + '/' + str(i))
# 生成训练和测试的数据
def generate_data(train_path, test_path):
index = 1
output_index = 1
for (dirpath, dirnames, filenames) in os.walk(input_path):
# 打乱文件列表,相当于是随机选取8张训练集,2张测试
random.shuffle(filenames)
for filename in filenames:
if filename.endswith('.bmp'):
img_path = dirpath + '/' + filename
# 使用opencv 读取图片
img_data = cv2.imread(img_path)
# 按照论文中的将图片大小调整为28 * 28
img_data = cv2.resize(img_data, (28, 28), interpolation=cv2.INTER_AREA)
if index < 3:
cv2.imwrite(test_path + '/' + str(output_index) + '/' + str(index) + '.jpg', img_data)
index += 1
elif 10 >= index >= 3:
cv2.imwrite(train_path + '/' + str(output_index) + '/' + str(index) + '.jpg', img_data)
index += 1
if index > 10:
output_index += 1
index = 1
运行完后我们便得到了320张训练集,80张测试集,所得的样本都是通过随机选取。
训练集:

测试集:

将train和test写入到tfrecord的同时进行标注
# 生成整数型的属性
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
# 生成字符串类型
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
train_path = "./train/"
test_path = "./test/"
classes = {i: i for i in range(1, 41)}
writer_train = tf.python_io.TFRecordWriter("orl_train.tfrecords")
writer_test = tf.python_io.TFRecordWriter("orl_test.tfrecords")
def generate():
# 遍历字典
for index, name in enumerate(classes):
train = train_path + str(name) + '/'
test = test_path + str(name) + '/'
for img_name in os.listdir(train):
img_path = train + img_name # 每一个图片的地址
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img_raw = img.tobytes()
example = tf.train.Example(features=tf.train.Features(feature={
'label': _int64_feature(index + 1),
'img_raw': _bytes_feature(img_raw)
}))
writer_train.write(example.SerializeToString())
for img_name in os.listdir(test):
img_path = test + img_name # 每一个图片的地址
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img_raw = img.tobytes()
example = tf.train.Example(features=tf.train.Features(feature={
'label': _int64_feature(index + 1),
'img_raw': _bytes_feature(img_raw)
}))
writer_test.write(example.SerializeToString())
writer_test.close()
writer_train.close()接下来开始训练:
def train(data, label):
x = tf.placeholder(tf.float32,
[BATCH_SIZE, SIZE, SIZE, orl_inference.NUM_CHANNELS],
name='x-input')
y_ = tf.placeholder(tf.float32, [None, orl_inference.OUTPUT_NODE], name='y-output')
# 使用L2正则化计算损失函数
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
min_after_dequeue = 100
capacity = min_after_dequeue + 3 * BATCH_SIZE
image_batch, label_batch = tf.train.shuffle_batch(
[data, label], batch_size=BATCH_SIZE,
capacity=capacity, min_after_dequeue=min_after_dequeue
)
y = orl_inference.inference(x, False, regularizer)
global_step = tf.Variable(0, trainable=False)
variable_averages = tf.train.ExponentialMovingAverage(
MOVING_AVERAGE_DECAY, global_step
)
variable_averages_op = variable_averages.apply(tf.trainable_variables())
# 计算交叉熵作为刻画预测值和真实值之间的损失函数
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
# 计算所有样例中交叉熵的平均值
cross_entropy_mean = tf.reduce_mean(cross_entropy)
# 总损失等于交叉熵损失和正则化损失的和
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
# 设置指数衰减的学习率
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
320 / BATCH_SIZE,
LEARNING_RATE_DECAY,
staircase=True
)
# 优化损失函数
train_step = tf.train.GradientDescentOptimizer(learning_rate) \
.minimize(loss, global_step=global_step)
with tf.control_dependencies([train_step, variable_averages_op]):
train_op = tf.no_op(name='train')
saver = tf.train.Saver()
# 验证
# accuracy = tf.reduce_mean()
with tf.Session() as sess:
tf.global_variables_initializer().run()
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 迭代的训练网络
for i in range(TRAINING_STEPS):
xs, ys = sess.run([image_batch, label_batch])
xs = xs / 255.0
reshaped_xs = np.reshape(xs, (BATCH_SIZE,
SIZE,
SIZE,
orl_inference.NUM_CHANNELS))
# 将图像和标签数据通过tf.train.shuffle_batch整理成训练时需要的batch
ys = get_label(ys)
_, loss_value, step = sess.run([train_op, loss, global_step],
feed_dict={x: reshaped_xs, y_: ys})
if i % 100 == 0:
# 每10轮输出一次在训练集上的测试结果
acc = loss.eval({x: reshaped_xs, y_: ys})
print("After %d training step[s], loss on training"
" batch is %g. " % (step, loss_value))
saver.save(
sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME),
global_step=global_step
)
# logit = orl_inference.inference(image_batch)
coord.request_stop()
coord.join(threads)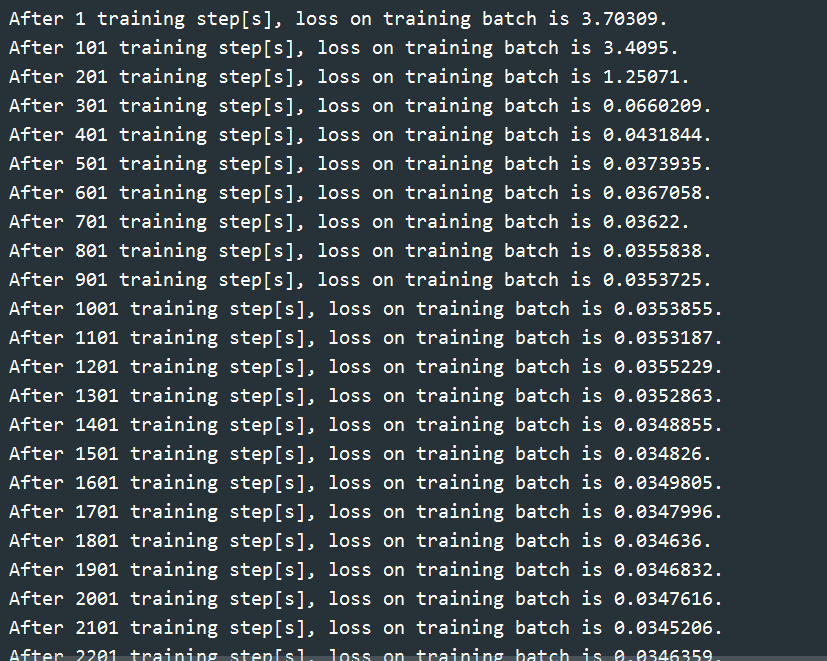
进行验证:
def evaluate():
with tf.Graph().as_default() as g:
filename_queue = tf.train.string_input_producer(["orl_test.tfrecords"])
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(serialized_example,
features={
'label': tf.FixedLenFeature([], tf.int64),
'img_raw': tf.FixedLenFeature([], tf.string),
})
img = tf.decode_raw(features['img_raw'], tf.uint8)
img = tf.reshape(img, [28, 28, 1])
label = tf.cast(features['label'], tf.int32)
min_after_dequeue = 100
capacity = min_after_dequeue + 3 * 200
image_batch, label_batch = tf.train.shuffle_batch(
[img, label], batch_size=80,
capacity=capacity, min_after_dequeue=min_after_dequeue
)
x = tf.placeholder(tf.float32,
[80,
orl_inference.IMAGE_SIZE,
orl_inference.IMAGE_SIZE,
orl_inference.NUM_CHANNELS],
name='x-input')
y_ = tf.placeholder(
tf.float32, [None, orl_inference.OUTPUT_NODE], name='y-input'
)
y = orl_inference.inference(x, None, None)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
variable_averages = tf.train.ExponentialMovingAverage(
orl_train.MOVING_AVERAGE_DECAY
)
variable_to_restore = variable_averages.variables_to_restore()
saver = tf.train.Saver(variable_to_restore)
# 每隔EVAL_INTERVAL_SECS秒调用一次
while True:
with tf.Session() as sess:
test = cv2.imread('./data/20/10.jpg')
test = cv2.cvtColor(test, cv2.COLOR_BGR2GRAY)
test = np.array(test)
test = test / 255.0
test_re = np.reshape(test, (1, 28, 28, 1))
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
xs, ys = sess.run([image_batch, label_batch])
ys = get_label(ys)
xs = xs / 255.0
validate_feed = {x: xs,
y_: ys}
cpkt = tf.train.get_checkpoint_state(
orl_train.MODEL_SAVE_PATH
)
if cpkt and cpkt.model_checkpoint_path:
# 加载模型
saver.restore(sess, cpkt.model_checkpoint_path)
# 通过文件名得到模型保存时迭代的轮数
global_step = cpkt.model_checkpoint_path \
.split('/')[-1].split('-')[-1]
# result = sess.run(y, feed_dict={x: test_re})
# re = np.where(result == np.max(result))
# ss = tf.argmax(result, 1)
# tt = np.argmax(result, 1)
# print('result is %d'%(tt[0] + 1))
# # print('hehe')
accuracy_score = sess.run(accuracy,feed_dict=validate_feed)
print("After %s training steps, validation "
"accuracy = %g" % (global_step, accuracy_score))
else:
print("No checkpoint file found")
return
time.sleep(EVAL_INTERVAL_SECS)
此次实验参考了《Tensorflow 实战Google深度学习框架》这本书的内容,根据所学内容,将文献中的实验实践了一遍,也算是加深了理解。
完整代码:听说star的人会变帅