收到一个task,搭建3节点的tikv集群,用相关profiling工具研究下tikv可能的性能瓶颈,可暂时只测raw kv insert性能。
听起来有些挑战性。平常profile的多半是c/c++程序,这rust版本的程序还真没弄过。对rust的了解,目前较浅显,对tikv的了解非源码级别上。Anyway,也并非不了解源码就做不成,性能profiling过程大同小异,顺便熟悉一下编译安装、监控搭建等过程
tikv集群及监控安装
参照前一篇文章安装。不过,有两个问题。
-
若是不加修改使用pd.toml, tikv.toml,tikv的日志中一直有下图所示的ERROR; 但用pd-ctl检查状态都是正常的(暂不确定为何,但貌似不影响测试)
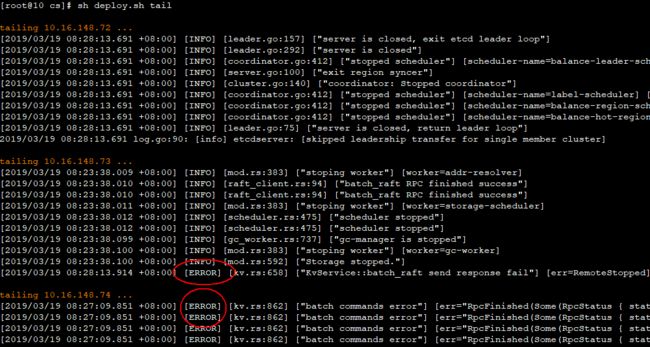 image.png
image.png - 担心latest中的binary没有包含DEBUG符号信息,这样在火焰图可能会出现大量unknown,所以尝试自己编译tikv
编译tikv release with debuginfo
切换到v3.0.0-beta分支,执行cargo build --release(Cargo.toml默认debug=true; 默认并行编译)。可能的编译error有:
- 若出现
error: expected ``)' before 'PRIu64',则export CXXFLAGS="-D__STDC_FORMAT_MACROS" - 若
unrecognized command line option ‘-Wimplicit-fallthrough’,则更新g++到7.x - 若
error: ‘google’ has not been declared,则手工编译安装gflags 2.2+
编译耗时较长(24cores, > 30min)
比较target/release下的tikv-server与tidb-latest-linux-amd64/bin/tikv-server,竟然一样大。只好认为binary包中的带有debuginfo(也许可以从readelf -S tidb-latest-linux-amd64/bin/tikv-server | grep debug得知)
rust profiler
perf + flamegraph
平常perf用于分析C++程序性能用得较多,既然也可用于分析rust程序,本次实践就用perf。
参考
http://carol-nichols.com/2015/12/09/rust-profiling-on-osx-cpu-time/
rust-lang post: Profiling in rust application
cargo profiler
它支持callgrind, cachegrind等valgrind系列工具,但其counting开销要比perf_events的sampling大些;
当然,valgrind也可单独作用于rust 程序,如How-to Optimize Rust Programs on Linux 详细介绍了使用valgrind工具来profiling rust program
flame + flamer
flame是原生的rust性能分析库,不同于perf,它是通过给特定代码加上instrumentation code,从而得到那部分代码的火焰图。有些类似于systemtap的探针;
flamer是给flame制作的编译器插件,使用annotation更加方便地注入instrumentation code
benchmark tools: go-ycsb
指定了用https://github.com/pingcap/go-ycsb,这个由golang改写的YCSB压测工具,作者在go-ycsb:一个 Go 的 YCSB 移植也做了相关介绍。当然有时间的话,也可以用java版本的YCSB,不过可能得另加tikv db 接口了。
编译go-ycsb曲折小插曲:
本来想在开发机编译go-ycsb,出现了unrecognized import path "golang.org/x/net"类似的问题后,就手动从github.com clone到golang.org/x文件夹内。没想到还是不行,猜测原因在于go.mod文件指定了依赖的特定版本,而我clone的时候默认是主版本。这一个一个clone有点麻烦,还是希望能编译。
暂不知如何在公司机器上加科学上网的代理,于是考虑在个人windows上安装virtualbox linux,借助windows上已经配置成功的代理可桥接到golang.org/x, googleapis等,然而在某些地址上发生i/o timeout。额,最后一招了,借助公司windows上的virtualbox linux,终于可以编译了,虽然中间也出现了uber.org的i/o timeout,手动从github下载相应tag版本后就可以了。顺便拷贝所有的pkg到开发机上
选择一台物理机(10.110.36.144)作压测节点(与tikv node ping latency 1.4ms),执行
./bin/go-ycsb shell tikv -p tikv.pd=http://10.16.148.72:2379 -p tikv.type=raw
出现错误
ERRO[0003] [pd] failed to get cluster id: rpc error: code = Unavailable desc = all SubConns are in TransientFailure, latest connection error: connection error: desc = "transport: Error while dialing failed to do connect handshake, response: "HTTP/1.0 403 Forbidden
弄了半天也没发现哪里出了问题,pd, tikv-server都没ERROR日志。只好去社区提了个issue #96。几小时之后,细致地看错误信息后,发现有access denied, squid等字眼,怀疑是不是https_proxy被设置了,果然是它!
先尝试跑个shell basic,
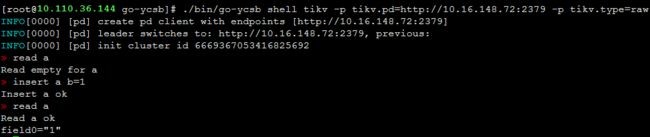
- 问题:当第二次进入shell命令行时,exit时出现报错,这应该不是个正确的行为。见issue #97,这个问题以后再跟踪
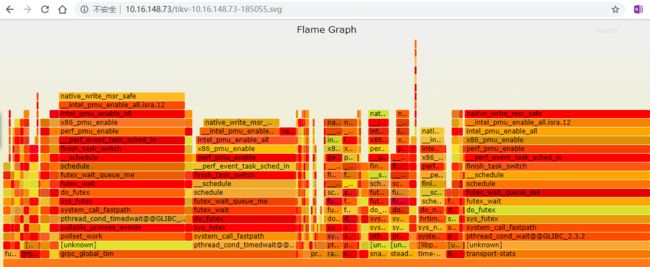
空闲状态下的火焰图
下图是tikv-1节点在空闲状态下的火焰图。可以看出tikv进程的线程还是蛮多的,用ps -L -p $(pidof tikv-server) | wc -l发现有194个,远超逻辑CPU个数48。是否合理,合理到能平衡context-switch, lock contention所带来的负面影响,值得探讨。
由下图可知,线程grpc_global_tim和transport_stats占了CPU大块头。(不明白为什么还是有unknown ?)
go-ycsb load phase
基本想法是:目前只有一台物理机client loader,为看清server性能,client应尽可能吃满CPU(24 cores)
命令:
./bin/go-ycsb load tikv -P workloads/workloada -p tikv.pd=10.16.148.72:2379 -p tikv.type=raw -p recordcount=100000000 -p tikv.conncount=1024 -p tikv.batchsize=256
然而,
- 我以为dropdata=true是删除tikv所有数据,然而貌似没有
- 我以为增加
tikv.conncount,可以提高客户端的压力,然而选1或1024,insert ops始终在1.7w; htop端显示的CPU远未得到利用 (那该如何增加单个go-ycsb实例的压力呢?)
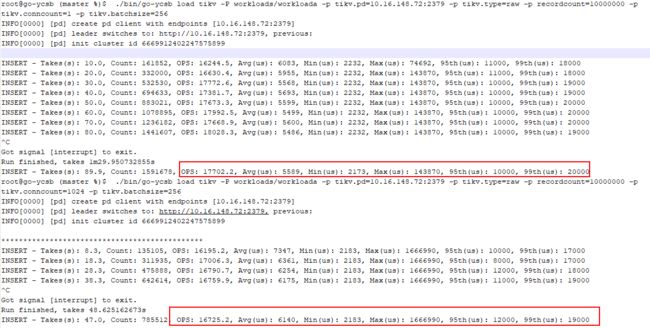 image.png
image.png
执行 ./deploy perf,火焰图如下:
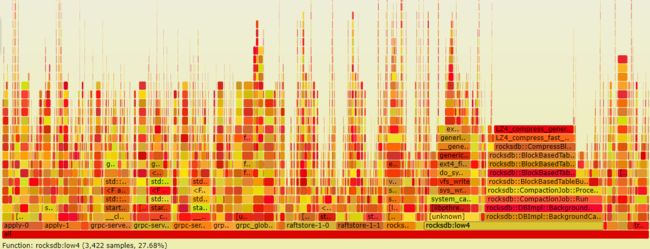
- 线程rocksdb::low4占用了主要部分,其中compaction及压缩占了很大部分,还有ext4 write; rocksdb选项有中
use-direct-io-for-flush-and-compaction,这个为何默认为false呢
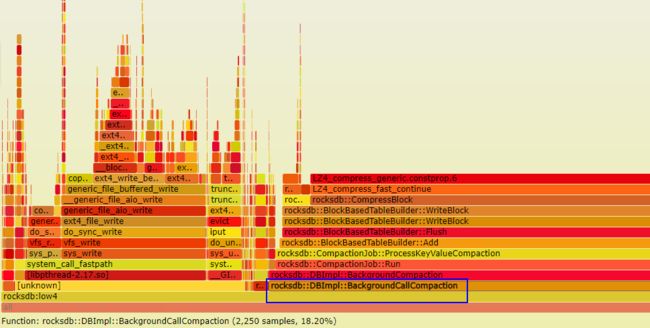 image.png
image.png -
memory allocation火焰图。各线程分配看似比较均匀, apply线程占得稍多;像std::string动态分配在rocksdb中好像很多,会有所影响
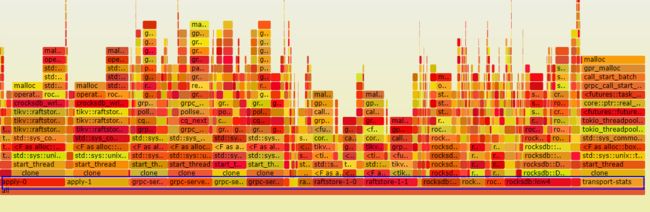 image.png
image.png
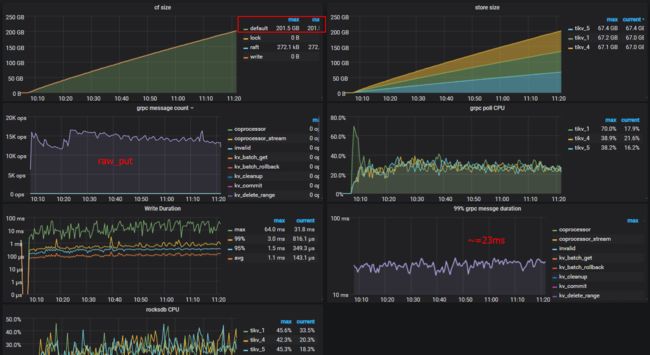
一小时后的监控部分指标截图
grpc消息P99延时大概在23ms; 总共200G,每个tikv实例承担了65G, raw_input只在1.5w。压力不够是个原因(要么再找go-ycsb提高CPU利用率的方法/参数,要么增加多个go-ycsb实例)
go-ycsb run phase
run阶段的workload种类丰富,由于时间关系,以后再来补充。此次目的是探一探raw kv insert的究竟,我想在load阶段就可以体现出来。等熟悉参数后再做run阶段的压测
Summary
此次profiling还不是很深入,这么多参数搭配,还是需好好理解一番。不过从个人经验来讲,有以下注意事项:
-
grpc-concurrency,end-point-concurrency等并发值该怎么配,与特定机器上的cores N如何适配?前面提到,启动后的线程数有194个,它们如何高效利用N需要研究; 且此次测试未发现go-ycsb单实例提高压力的方法/参数,所以默认并发为4的grpc poll cpu维持在40%以下,不太符合压测吞吐量时的要求(将CPU打满,至少是前台grpc线程的CPU) - tikv默认应该使用了jemalloc,动态分配是否尽可能采用预分配呢,以防止在hot path上受阻
- 最后面板可以再调整。参数众多,虽说用了grafana panel的折叠功能,但是想看全貌还是得不断地expand, scroll,不是很方便,刷新也容易迟缓。
- 我想应该是可以通过建立模板变量,为不同component设置不同label,想看什么直接下拉选择component name;
- 或者再加一个不同视图的dashboard,比如rocksdb是一个视图,raft是另外一个视图,grpc也是,让视图之间互相引用链接,也不错
- 若想按instance聚合而非job,则添加聚合变量为宜
rustasync社区有 issue #13谈到了给rust添加shared-nothing的线程执行器,类似seastar::future的异步机制。私以为这是个好消息,虽暂时还看不太懂里面讨论的rust async原语,但future, lock-free, no context-switch等这些好处我认为在未来多核系统上将会展现充分。持续关注这个issue