什么是路由自动注入
路由自动注入概念学习自nuxt,我们不需要在 router.js 中每次手动输入代码引入模块而是自动根据 文件目录格式 生成 router.js
我们把这个功能独立成一个 webpack 插件,并对相关功能进行了完善,而且实现了 vue-router 的所有核心功能
更详细使用指南和文档可以查看我们的 github仓库
举一个简单的列子,比如你的目录长这样
src ├── views │ ├── Login │ │ └── Index.vue │ └── User │ ├── Account │ │ └── Index.vue │ ├── Home │ │ └── Index.vue │ └── Index.vue
规则很简单,如果目录的一层是 Index.vue ,则目录名便是当前的路由名字,如果是子文件夹则是第二层路由,之后自动生成的 router.js 会长成这样
{
component: () =>
import('@/views/Login/Index.vue'),
name: 'login',
path: '/login'
},
{
component: () =>
import('@/views/User/Index.vue'),
name: 'user',
path: '/user'
},
{
component: () =>
import('@/views/User/Account/Index.vue'),
name: 'user-account',
path: '/user/account'
},
{
component: () =>
import('@/views/User/Home/Index.vue'),
name: 'user-home',
path: '/user/home'
}
这里值得一提的是其实生成的 router.js 是没有必要加入到版本控制当中的,因为不论在开发( development )还是生产( production )第一次构建项目都会自动生成,比如你项目用到了 git 和 eslint ,那么应该把它放在 .gitignore 和 .eslintignore 中
为什么使用路由自动注入
方便
不用每次去引用模块,只用创建文件夹, router.js 会自动生成
统一路由命名

如果有完整的 code review 这个问题是不会存在的,但我们稍微做了一点简便,只要 code review 文件夹的命名就好了,最终生成的路由path会以驼峰命名,生成的name会以驼峰命名并且以连字符 - 连接不同层级的路由
统一路由层级

如图片中的列子,我们无法从文件的命名去判断路由到底在几级,而且经常写的时候,明明是2级或3级路由却和1级路由在一层路由下,这是很不规范而且与逻辑不符的
对比一下使用自动注入划分层级后的路由
src/views ├── Index.vue ├── NotFound.vue ├── Withdraw │ ├── Index.vue │ └── Result │ ├── Description │ │ └── Index.vue │ └── Index.vue └── WithdrawHistory └── Index.vue
可以从目录结构看出路由的层级
我们再来看看生成的路由,不同层级的路由名字通过连字符 - 连接,层级很清晰
{
component: () => import('@/views/Withdraw/Index.vue'),
name: 'withdraw',
path: '/withdraw'
},
{
component: () => import('@/views/Withdraw/Result/Index.vue'),
name: 'withdraw-result',
path: '/withdraw/result'
},
{
component: () => import('@/views/Withdraw/Result/Description/Index.vue'),
name: 'withdraw-result-description',
path: '/withdraw/result/description'
},
{
component: () => import('@/views/WithdrawHistory/Index.vue'),
name: 'withdrawHistory',
path: '/withdrawHistory'
},
为什么选择 vue-router-invoke-webpack-plugin
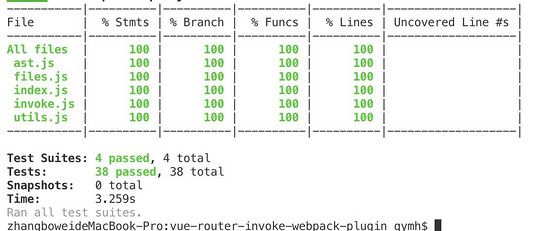
完善的单元测试
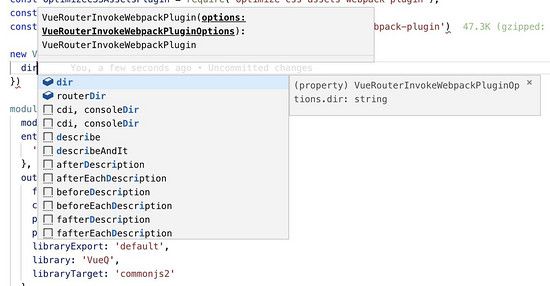
types支持
vue-router-invoke-webpack-plugin 中独特的路由划分思维
当我们的页面过多的时候,比如项目有60多个甚至70多个单页面,文件不可能会放在一个目录下,一般这种时候,我们会按 功能 将相似功能的路由放在一个目录下,我们之前也是这么做的,其实这么做也是没啥问题的,但在路由自动注入下,我们提出了另外一种思路按路由 层级 划分
什么是层级划分呢,简单的一句话就是根据页面所在的相对url地址进行划分,举个列子,我们的首页如下
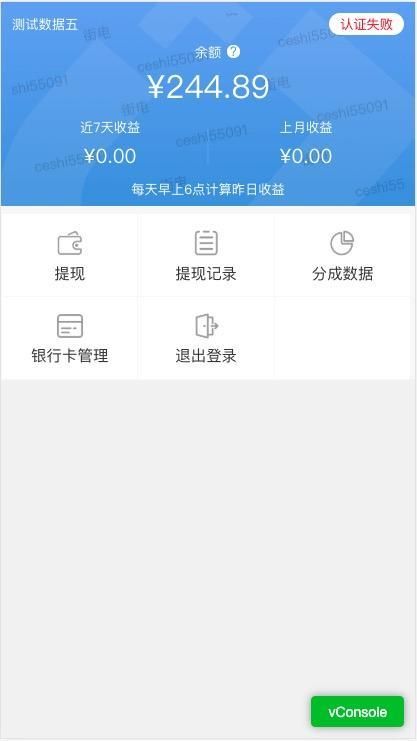
首页的路由为 / ,我们把首页当作根路由,那么可以进入的一级路由分别为 提现 提现记录 分成数据 等,点击提现后,我们进入了提现路由 /withdraw
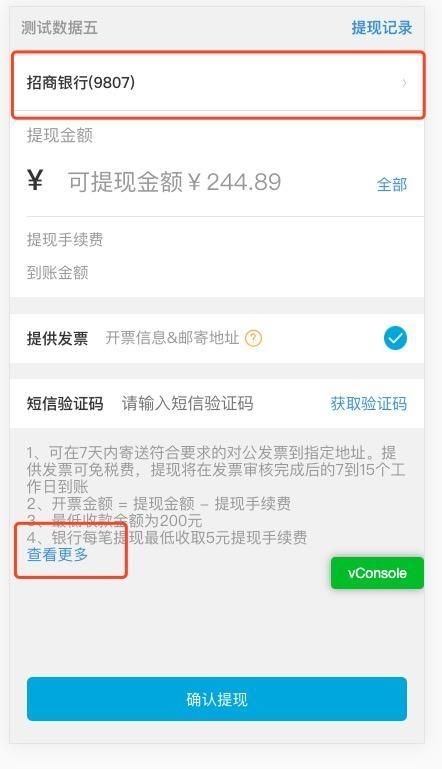
进入提现页面后,会有两处可点击,这两处便是二级页面,放在一级页面的子文件夹中,按刚才的说法,路由目录(截取部分)便是这样
src/views ├── Bank │ └── Index.vue ├── DivideData │ └── Index.vue ├── Index.vue ├── NotFound.vue ├── Withdraw │ ├── BankDetails │ │ └── Index.vue │ ├── Description │ │ └── Index.vue │ └── Index.vue └── WithdrawHistory └── Index.vue
其实一般这么分下来,相似功能的是会在一个文件夹下面的,也实现了按功能分路由的思路,而且这种层级划分是一目了然的,很容易可以看出路由的从属关系
但有时候也会遇到一个麻烦,就是有些页面可能出现在当前层级下面,也可能出现在另外一个层级下面,按功能分的时候也有这种,就是功能可能存在于两个功能点之间,这种情况其实可以考虑下在哪个层级的权重重一点或者从用户的点击习惯考虑,哪个位置进去会多一点就放在哪个层级下面
vue-router-invoke-webpack-plugin 中独特的文件结构
也许大家会有疑问,为啥非要写成 Index.vue 并多加一层文件夹封装,直接命名 vue 文件不好吗,用过 nuxt 的同学可能也会感觉到这一点的区别,这也是我们在 nuxt 的基础上增加的一个 feature ,为了更友好的封装一个单页面
举个列子,如果你的项目没有引用ui库,很多业务组件需要自己写,除了常用的组件会放在目录最外面的 components 文件,其余的对应一个单页面的业务组件你会放在哪里呢,这就是我们预留的位置,比如一个目录结构如下
src/views ├── Audit │ ├── Index.vue │ ├── components │ │ └── AuditItem.vue │ └── images │ └── AuditIntro.png
Audit 是我们的审批页面,其中用到了一个只有当前页面所用的 AuditItem.vue 组件,也引用了一个只有当前页面所用到的图片 AuditIntro.png ,独特的文件结构就是为了这种需求而生的,当前页面的组件图片放在一个文件夹中会更清晰,但值得一提的是,你也需要在插件中设置 ignore 去忽略掉不被我们解析的目录,比如这样
plugins: [
new VueRouterInvokeWebpackPlugin({
dir: 'src/views',
alias: '@/views',
language: 'javascript',
ignore: ['images', 'components', 'template.vue']
})
];
那么 images components template.vue 会被忽略不解析
聊一聊路由权限控制
关于前端控制路由权限,前段时间看到过一个文章,感觉实现思路稍微复杂了点,其实有一个比较简单的思路,就是后端给定当前用户没有权限的路由,然后前端在 beforeEach 钩子中去匹配,如果匹配到没有权限则直接跳404或者没有权限的页面就行了,如果用 vue-router-invoke-webpack-plugin 写会这么写
apis.getForbiddenRoute
export default {
// 请求当前没有权限的路由列表
async getForbiddenRoute() {
return ['/single/user'];
}
};
plugins: [
new VueRouterInvokePlugin({
// 观察的目录
dir: 'demos/src',
// 观察目录的别名
alias: '@/src',
// 当前语言
language: 'javascript',
// 生成router.js的位置
routerDir: 'demos',
// 忽略文件夹
ignore: ['images', 'template.vue', 'components', 'notfound.vue'],
// 404路由地址
notFound: '@/src/NotFound.vue',
// 引用的模块
modules: [
{
name: 'apis',
package: '@/apis'
}
],
// 同scrollBehavior
scrollBehavior: (to, from, savedPosition) => {
if (savedPosition) {
return savedPosition;
} else {
return { x: 0, y: 0 };
}
},
/* eslint-disable */
beforeEach: async (to, from, next) => {
// 通过绑定在静态属性上的_cachedForbiddenRoute判断是否请求过接口
if (!Vue._cachedForbiddenRoute) {
Vue._cachedForbiddenRoute = [];
await apis.getForbiddenRoute().then(res => {
Vue._cachedForbiddenRoute = res;
});
}
// 当当前页面的地址存在于禁止访问的列表中,则直接跳转到404页面
if (Vue._cachedForbiddenRoute.includes(to.path)) {
next({
name: 'notFound'
});
} else {
next();
}
}
}),
]
但话说回来,任何实现思路,前端获取的接口数据想篡改还是能绕过去的,所以还是得后端再防一层
项目实现思路
项目实现不太复杂,但要照顾到的地方很多
- 基本路由
- 动态路由
- 多层嵌套路由
- 多层嵌套动态路由
- meta替代品
- 文件不符合规则的友好处理
- 命名转换统一
- node中原生fs模块十分不友好
要考虑的小细节还挺多的,特别是当路由过于复杂的情况
但node的 fs 的坑点是我没有想到的,特别是在跨平台上,所以我们舍弃了使用原生的 fs 模块,用 chokidar 和 fs-extra 替代了 fs 的部分功能
前段时间也在学习 vue 的ast语法树,所以学习了下思路去尝试构建一棵ast,不过方法还是有区别的,vue构建语法树是通过正则拆分了 元素开始标签 元素属性 元素字符 元素结束标签 等然后拼接而成的,拼接的过程特别复杂,这个项目会简单很多,直接通过文件读取递归遍历目录就可以生成一棵 ast 了

然后通过语法树去构建字符串的 router.js ,构建的过程还比较麻烦,最后将构建好的字符串写入文件就大功告成了
项目还需要完善的地方
单元测试
现在的单元测试覆盖率已经100%了,但我觉得仍然有比较多稍微复杂的情况没有写到,之后会不仅看单元测试覆盖率,而是按想到需要测试得功能点去补充完整
测试环境
项目接入的是 circleci ,没法在 windows 下测试,平常用的开发环境也是 mac ,所以测试环境方面之后还要去研究研究其他可以支持windows的ci工具,并对不同node版本进行测试
其实现在在 windows 下也有一个bug,但我发现 nuxt 也有这个bug,所以感觉可能这不是一个bug或许是一个feature,之后也会去提一个 issue 去请教一下,也不知道是不是我电脑的问题,简单说就是 fs.watch 去监听文件目录的时候(但这里其实用的是 chokidar ,不过都一样)当去改变之前已有的文件目录的名字是改不了的, windows 下会提示你什么当前文件被引用了,需要结束掉进程这个文件名才能被修改
更友好的支持
项目目前支持的是node版本> 8.15.1,仅支持 webpack4 ,之后会支持 webpack3 和即将到来的 webpack5
更多的功能
除了刚才提到的一个简单路由的列子和设置忽略项,我们还支持了 vue-router 的其他核心功能,包括 动态路由 嵌套路由 全局路由守卫 meta替代品 等其他功能,相关功能点都写在了我们开源仓库的文档中,详细的用法和注意事项,可以访问我们的 github仓库 ,如果觉得项目还不错的话,可以给我们点一颗小星星,当然如果你在使用中发现了和预期不太一样的情况或者bug可以随时给我们提 issue
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。