【笔记3-5】CS224N课程笔记 - 依存分析
CS224N(五)Dependency Parsing
- 依存语法和依存结构
- 依存分析
- 基于转换的依存分析
- 贪婪转换依存分析
- 神经依存分析
【笔记3-1】CS224N课程笔记 - 深度自然语言处理
【笔记3-2】CS224N课程笔记 - 词向量表示 word2vec
【笔记3-3】CS224N课程笔记 - 高级词向量表示
【笔记3-4】CS224N课程笔记 - 分类与神经网络
【笔记3-6】CS224N课程笔记 - RNN和语言模型
【笔记3-7】CS224N课程笔记 - 神经机器翻译seq2seq注意力机制
【笔记3-8】CS224N课程笔记 - 卷积神经网络
CS224n:深度学习的自然语言处理(2017年冬季)1080p https://www.bilibili.com/video/av28030942/
涉及到的论文:
Globally Normalized Transition-Based Neural Networks (Daniel Andor, Chris Alberti, DavidWeiss, Aliaksei Severyn, Alessandro Presta, Kuzman Ganchev, Slav Petrov and Michael Collins,2016)
https://arxiv.org/pdf/1603.06042.pdf
A Fast and Accurate Dependency Parser using Neural Networks (Danqi Chen, Christopher D. Manning,2014)
https://cs.stanford.edu/people/danqi/papers/emnlp2014.pdf
Incrementality in Deterministic Dependency Parsing (Joakim Nivre,2004)
https://www.aclweb.org/anthology/W04-0308
依存语法和依存结构
与编译器中的解析树类似,NLP中的解析树用于分析句子的句法结构。使用的结构主要有两种类型——constituency和dependency。
Constituency Grammar:使用短语结构语法将单词放入嵌套的组件中。
Dependency Parsing:句子的从属结构显示哪些词依赖于(修饰或是)哪些词。这些单词之间的二元非对称关系称为依赖关系,并被描述为从head到dependent。通常这些依赖关系形成一个树结构。经常用语法关系的名称进行分类(主语,介词宾语,同位语等)。有时会将假根节点作为head添加到树中,所以每个单词都依赖于一个节点。
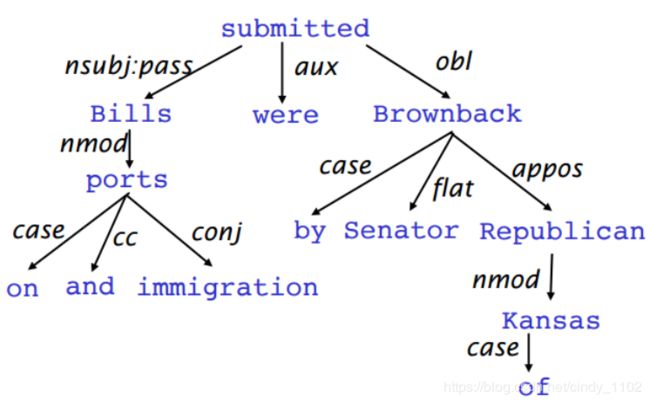
依存分析
依存分析:分析给定输入句的语法依赖结构。依存解析器的输出是依赖树,其中输入句的单词通过类型化依赖关系连接。在形式上,依存关系问题要求从输入语句(包含单词 S = w 0 w 1 . . . w n S=w_0w_1...w_n S=w0w1...wn)到依存关系树创建一个映射。
依存分析有两个子问题:
- 学习:给定一组用依赖关系图标注的句子训练集D,导出一个解析模型M,该模型可用于解析新句子。
- 解析:给定一个解析模型M和一个句子S,根据M推导出S的最优依赖关系图D。
基于转换的依存分析
基于转换的依存解析依赖于状态机,状态机定义可能的转换,以创建从输入语句到依赖项树的映射。学习问题是根据状态机的过渡历史,建立预测状态机下一个过渡的模型。解析问题是根据前面推导的模型,构造输入句子的最优转换序列。大多数基于转换的系统不使用正式语法。
贪婪转换依存分析
这个转换系统是一个状态机,它由状态以及这些状态之间的转换组成。该模型推导一系列从某种初始状态到几种终端状态之一的转换。
- 状态 state:
对于任意一个句子 S = w 0 w 1 . . . w n S=w_0w_1...w_n S=w0w1...wn,状态是以下三者的组合 c = ( σ , β , A ) c=(\sigma,\beta,A) c=(σ,β,A)
σ \sigma σ是一个包含 S S S 中的 w i w_i wi 的堆栈(stack); β \beta β 是包含 w i w_i wi的缓冲区(buffer);A是依存弧 ( w i , r , w j ) (w_i,r,w_j) (wi,r,wj)的集合,其中 w i , w j w_i,w_j wi,wj来自于句子S, r r r表示依存关系。
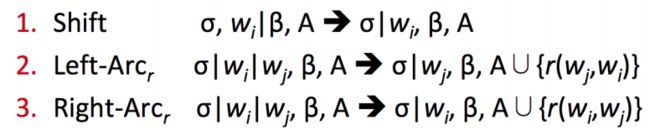
对于任意一个句子 S = w 0 w 1 . . . w n S=w_0w_1...w_n S=w0w1...wn,初始状态 c 0 c_0 c0可以表示为 ( [ w 0 ] σ , [ w 1 , . . . , w n ] β , ∅ ) ([w_0]_{\sigma},[w_1,...,w_n]_{\beta},\varnothing) ([w0]σ,[w1,...,wn]β,∅),即只有ROOT在堆栈 σ \sigma σ 中,其他单词都在buffer β \beta β 中,暂未采取任何行动。终止状态为 ( σ , [ ] β , A ) (\sigma,[]_{\beta},A) (σ,[]β,A) - 转换 transition:
状态之间的转换有三种:
Shift:删除缓冲区中的第一个单词,并将其推到堆栈顶部。(要求缓冲区非空)
Left-arc:往集合A中添加一个依存弧 ( w j , r , w i ) (w_j,r,w_i) (wj,r,wi),其中 w i w_i wi 是距离栈顶第二近的单词,而 w j w_j wj 是栈顶单词。将 w i w_i wi 从堆栈中移除(要求堆栈至少包含两个单词,且 w i w_i wi 不能为ROOT)
Right-arc:往集合A中添加一个依存弧 ( w i , r , w j ) (w_i,r,w_j) (wi,r,wj),其中 w i w_i wi 是距离栈顶第二近的单词,而 w j w_j wj 是栈顶单词。将 w j w_j wj 从堆栈中移除(要求堆栈至少包含两个单词)
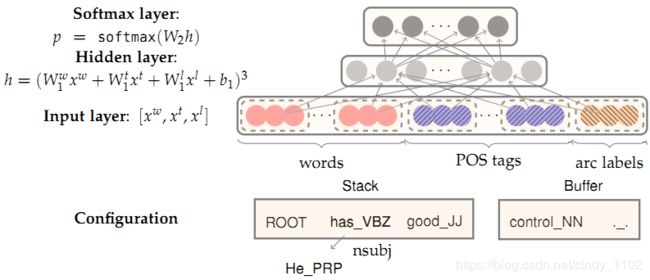
神经依存分析
依存分析有许多深入的模型,本节特别关注贪婪的基于转换的神经依存分析器。与传统的基于特征的依存分析器相比,这类模型具有相当的性能和显著的效率。与以前模型的主要区别是依赖于密集而非稀疏的特性表示。
这里介绍的模型运用前面介绍过的弧转换系统,目的是从一个初始的配置 c c c,预测出直到终止配置的转换序列,在这个过程中编码一棵分析树。每次训练,模型都会基于当前的配置 c = ( σ , β , A ) c=(\sigma,\beta,A) c=(σ,β,A)预测出一轮转化 T ∈ { s h i f t , l e f t − a r c , r i g h t − a r c } T\in \{shift, left-arc,right-arc\} T∈{shift,left−arc,right−arc}
- 特征选择
根据模型所需的复杂性,可以灵活地定义神经网络的输入。某句话的特征一般包括以下部分:
S w o r d S_{word} Sword:在堆栈 σ \sigma σ 和缓冲区 β \beta β 顶部的S(及其依赖项)中的一些单词的向量表示。
S t a g S_{tag} Stag:词性(POS)标签是由一个小的离散集合构成的,它包括 P = { N N , N N P , N N S , D T , J J , … } P = \{NN, NNP, NNS, DT, J J,…\} P={NN,NNP,NNS,DT,JJ,…}
S l a b e l S_{label} Slabel:S中的一些单词的arc-label,由一个小的离散集组成,描述依赖关系 L = { a m o d , t m o d , n s u b j , c s u b j , d o b j , … } L = \{amod, tmod, nsubj, csubj, dobj,…\} L={amod,tmod,nsubj,csubj,dobj,…}
对于单词三个特征对应的独热码,会训练出三个embedding矩阵,将稀疏的独热向量转换成稠密向量。 E w ∈ R d ∗ N w , E t ∈ R d ∗ N t , E l ∈ R d ∗ N l E^w\in\mathbb{R}^{d*N_w},E^t\in\mathbb{R}^{d*N_t},E^l\in\mathbb{R}^{d*N_l} Ew∈Rd∗Nw,Et∈Rd∗Nt,El∈Rd∗Nl - 特征选择示例
S w o r d S_{word} Sword:堆栈和缓冲区上的前3个单词 s 1 , s 2 , s 3 , b 1 , b 2 , b 3 s_1,s_2,s_3,b_1,b_2,b_3 s1,s2,s3,b1,b2,b3。堆栈上顶部两个单词的第一个和第二个最左边/最右边的子单词: l c 1 ( s i ) , r c 1 ( s i ) , l c 2 ( s i ) , r c 2 ( s i ) , i = 1 , 2 lc_1(s_i),rc_1(s_i),lc_2(s_i),rc_2(s_i),i = 1,2 lc1(si),rc1(si),lc2(si),rc2(si),i=1,2。堆栈上最前两个单词的最左边/最右边的子元素: l c 1 ( l c 1 ( s i ) ) , r c 1 ( r c 1 ( s i ) ) , i = 1 , 2 lc_1(lc_1(s_i)),rc_1(rc_1(s_i)),i = 1,2 lc1(lc1(si)),rc1(rc1(si)),i=1,2。总共包含18个元素。 ( n w = 6 + 2 ∗ 4 + 2 ∗ 2 ) (n_w=6+2*4+2*2) (nw=6+2∗4+2∗2)
S t a g S_{tag} Stag: S w o r d S_{word} Sword对应的POS标签(n_{t}=18)
S l a b e l S_{label} Slabel: S w o r d S_word Sword中除了stack/buffer中的6个单词之外其他词的arc-label - 前向传播神经网络
包含输入层 [ x w , x t , x l ] [x_w,x_t,x_l] [xw,xt,xl] 隐藏层和输出层(交叉熵损失softmax层)