Perceptual Losses for Real-Time Style Transfer and Super-Resolution翻译
原文链接:https://www.jianshu.com/p/b728752a70e9。《基于感知损失函数的实时风格转换和超分辨率重建》
Abstract
摘要:我们考虑的图像转换的问题,即将一个输入图像变换成一个输出图像。最近热门的图像转换的方法通常是训练前馈卷积神经网络,将输出图像与原本图像的逐像素差距作为损失函数。并行的工作表明,高质量的图像可以通过用预训练好的网络提取高级特征、定义并优化感知损失函数来产生。我们组合了一下这两种方法各自的优势,提出采用感知损失函数训练前馈网络进行图像转换的任务。本文给出了图像风格化的结果,训练一个前馈网络去解决实时优化问题(Gatys等人提出的),和基于有优化的方法对比,我们的网络产生质量相当的结果,却能做到三个数量级的提速。我们还实验了单图的超分辨率重建,同样采用感知损失函数来代替求逐像素差距的损失函数
关键词:风格转换,超分辨率重建,深度学习
一. 简介
许多经典问题可以被分为图像转换任务,即一个系统接收到一些输入图像,将其转化成输出图像。用图像处理来举例,比如图像降噪,超分辨率重建,图像上色,这都是输入一个退化的图像(噪声,低分辨率,灰度),输出一个高质量的彩色图像。从计算机视觉来举例,包括语义分割,深度估计,其中的输入是一个彩色图像,输出是图像对场景的语义或几何信息进行了编码。
一个处理图像转换任务的方法是在有监督模式下训练一个前馈卷积神经网络,用逐像素差距作损失函数来衡量输出图像和输入图像的差距。这个方法被Dong等人用来做了超分辨率重建,被Cheng等人做了图像上色,被Long等人做了图像分割,被Eigen等人做了深度和表面预测。这个方法的优势在于在测试时,只需要一次前馈的通过已训练好的网络。
然而,这些方法都用了逐像素求差的损失函数,这个损失函数无法抓住输入及输出图像在感知上的差距。举个例子,考虑两张一模一样的图像,只有1像素偏移上的差距,尽管从感知上这俩图片一模一样,但用逐像素求差的方法来衡量的话,这俩图片会非常的不一样。
同时,最近的一些工作证明,高质量的图像可以通过建立感知损失函数(不基于逐像素间的差距,取而代之的是从预训练好的CNN中提取高层次的图像特征来求差)图像通过使损失函数最小化来生成,这个策略被应用到了特征倒置[6](Mahendran等),特征可视化[7] (Simonyan等/Yosinski等),纹理综合及图像风格化[9,10] (Gatys等)。这些方法能产生很高质量的图片,不过很慢,因为需要漫长的迭代优化过程。
在这篇论文中,我们结合了两类方法的优势。我们训练一个用于图像转换任务的前馈网络,且不用逐像素求差构造损失函数,转而使用感知损失函数,从预训练好的网络中提取高级特征。在训练的过程中,感知损失函数比逐像素损失函数更适合用来衡量图像之间的相似程度,在测试的过程中,生成器网络能做到实时转换。
我们实验了两个任务,图像风格化和单图的超分辨率重建。这两种都有天生的缺陷:图像风格化没有唯一正确的输出,超分辨率重建的话,我们可以从一个低分辨率图像重建出很多高分辨率的图像。比较好的是,这两个任务都需要对输入的图像进行语义上的理解。图像风格化中,输出图片从语义维度来看必须跟输入图像比较接近,尽管颜色和纹理会发生质的变化。超分辨率重建任务中,必须从视觉上模糊的低分辨率输入来推断出新的细节。原则上,一个为任何任务训练的高质量的神经网络应该能隐式的学习输入图像的相关语义;然而在实践中我们不需要从头开始学习:使用感知损失函数,允许从损失网络直接转移语义信息到转换网络。
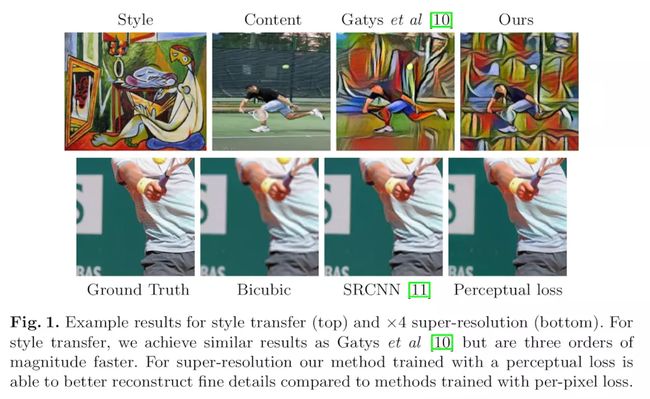
图1:我们的结果,第一行是风格化,第二行是4倍的超分辨率重建
对于图像风格化,我们的前馈网络用来解决优化问题[10];我们的结果跟[10]中很相似(无论是质量还是目标函数的值),但能达成3个数量级的速度飞升。对于超分辨率重建,我们证实:把逐像素求差损失函数改成感知损失函数,能带来视觉享受级的4倍和8倍超分辨率重建。
二. 相关工作
前馈图像转换:最近几年前馈图像转换任务应用十分广泛,很多转换任务都用了逐像素求差的方式来训练深度卷积神经网络。
语义分割的方法[3,5,12,13,14,15]产生了密集的场景标签,通过在在输入图像上以完全卷积的方式运行网络,配上逐像素分类的损失函数。[15]跨越了逐像素求差,通过把CRF当作RNN,跟网络的其他部分相加训练。我们的转换网络的结构是受到[3]和[14]的启发,使用了网络中下采样来降低特征图谱的空间范围,其后紧跟一个网络中上采样来产生最终的输出图像。
最近的方法在深度估计[5,4,16]和表面法向量估计[5,17]上是相似的,它们把一张彩色输入图像转换成有几何意义的图像,是用前馈神经网络,用逐像素回归[4,5]或分类[17]的损失函数。一些方法把逐像素求差改换成了惩罚图像梯度或是用CRF损失层来强制促使输出图像具有一致性。[2]中一个前馈模型用逐像素求差的损失函数训练,用于将灰度图像上色。
感知的优化:有一定数量的论文用到了优化的方法来产生图像,它们的对象是具有感知性的,感知性取决于从CNN中提取到的高层次特征。图像可以被生成用于最大限度提升分类预测的分数[7,8],或是个体的特征[8]用来理解训练网络时的函数编码。相似的优化技巧同样可以用于产生高可信度的迷惑图像[18,19]。
Mahendran和Vedaldi从卷积网络中反转特征,通过最小化特征重建损失函数,为了能理解保存在不同网络层中的图像信息;相似的方法也被用来反转局部二进制描述符[20]和HOG特征[21].
Dosovitskiy和Brox的工作是跟我们的最相关的,它们训练了一个前馈神经网络去倒置卷积特征,快速的逼近了[6]提出的优化问题的结局方案,然而他们的前馈网络是用的逐像素重建损失函数来训练,而我们的网络是直接用了[6]用的特征重建损失函数。
风格转换:Gatys等人展示艺术风格转换,结合了一张内容图和另一张风格图,通过最小化根据特征重建的代价函数,风格重建用的代价函数也是基于从预训练模型中提取的高级特征;一个相似的方法之前也被用于做纹理合成。他们的方法产出了很高质量的记过,不过计算代价非常的昂贵因为每一次迭代优化都需要经过前馈、反馈预训练好的整个网络。为了克服这样一个计算量的负担,我们训练了一个前馈神经网络去快速获得可行解。
图像超分辨率重建。图像超分辨率重建是一个经典的问题,很多人提出了非常广泛的技术手段来做图像超分辨率重建。Yang等人提供了一个对普通技术的详尽评价,在广泛采用CNN之前,它们把超分辨率重建技术归类成了一种基于预测的方法.(bilinear, bicubic, Lanczos, [24]), 基于边缘的方法[25,26] ,统计的方法[27,28,29],基于块的方法[25,30,31,32,33] ,稀疏字典方法[37, 38]。最近在单图超分辨率放大方向取得成就的表现是用了三层卷积神经网络,用逐像素求差的方式算损失函数。其他一些有艺术感的方法在[39,40,41]
三. 方法
像图2中展示的那样,我们的系统由两部分组成:一个图片转换网络fw 和一个损失网络 φ(用来定义一系列损失函数l1, l2, l3),图片转换网络是一个深度残差网络,参数是权重W,它把输入的图片x通过映射 y=fw(x)转换成输出图片y,每一个损失函数计算一个标量值li(y,yi), 衡量输出的y和目标图像yi之间的差距。图片转换网络是用SGD训练,使得一系列损失函数的加权和保持下降。
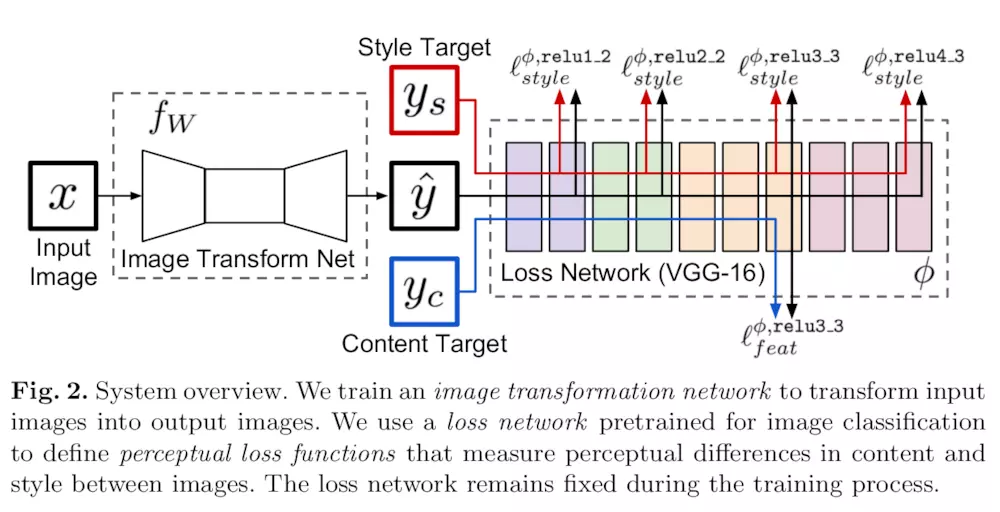
图2:系统概览。左侧是Generator,右侧是预训练好的vgg16网络(一直固定)
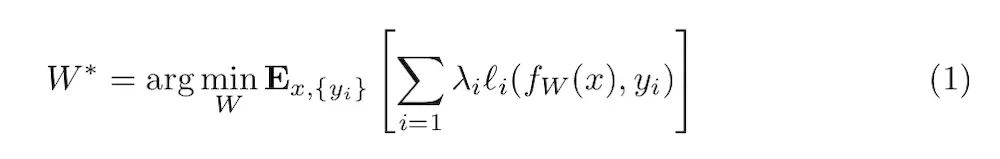
为了明确逐像素损失函数的缺点,并确保我们的损失函数能更好的衡量图片感知及语义上的差距,我们从最近的优化迭代生成图片的系列工作中得到了灵感[6,7,8,9,10],这些方法共同的关键点在于CNN是预先训练好用于图像分类的,这个CNN已经学会感知和语义信息编码,这正是我们希望在我们的损失函数中做的。所以我们用了一个预训练好用于图像分类的网络φ,来定义我们的损失函数。之后使用同样是深度卷积网络的损失函数来训练我们的深度卷积转换网络。
损失网络φ是能定义一个特征(内容)损失lfeat和一个风格损失lstyle,分别衡量内容和风格上的差距。对于每一张输入的图片x我们有一个内容目标yc一个风格目标ys,对于风格转换,内容目标yc是输入图像x,输出图像y,应该把风格Ys结合到内容x=yc上。我们为每一个目标风格训练一个网络。对于单图超分辨率重建,输入图像x是一个低分辨率的输入,目标内容是一张真实的高分辨率图像,风格重建没有使用。我们为每一个超分辨率因子训练一个网络。
3.1 图像转换网络
我们的图像转换网络结构大致上遵循Radford提出的指导方针[42]。我们不用任何的池化层,取而代之的是用步幅卷积或微步幅卷积(http://www.jiqizhixin.com/article/1417)做网络内的上采样或者下采样。我们的神经网络有五个残差块[42]组成,用了[44]说的结构。所有的非残差卷积层都跟着一个空间性的batch-normalization[45],和RELU的非线性层,最末的输出层除外。最末层使用一个缩放的Tanh来确保输出图像的像素在[0,255]之间。除开第一个和最后一个层用9x9的kernel,其他所有卷积层都用3x3的kernels,我们的所有网络的精确结构可以在支撑文档中看。
输入和输出:对于风格转换,输入和输出都是彩色图片,大小3x256x256。对于超分辨率重建,有一个上采样因子f,输出是一个高分辨率的图像3x288x288,输入是一个低分辨率图像 3x288/fx288/f,因为图像转换网络是完全卷积,所以在测试过程中它可以被应用到任何分辨率的图像中。
下采样和上采样:对于超分辨率重建,有一个上采样因子f,我们用了几个残差块跟着Log2f卷及网络(stride=1/2)。这个处理和[1]中不一样,[1]在把输入放进网络之前使用了双立方插值去上采样这个低分辨率输入。不依赖于任何一个固定的上采样插值函数,微步长卷积允许上采样函数和网络的其他部分一起被训练。

图3,和[6]相似,我们用了优化的方式去找一个图像y,能使得针对某些层的特征(内容)损失最小化,使用了预训练好的vgg16网络,在我们用较高层重建的时候,图像的内容和空间结构被保留了,但是颜色,纹理和精确的形状改变了。
对于图像转换,我们的网络用了两个stride=2的卷积去下采样输入,紧跟着的是几个残差块,接下来是两个卷积层(stride=1/2)来做上采样。虽然输入和输出有着相同的大小,但是先下采样再上采样的过程还是有一些其他好处。
首当其冲的好处是计算复杂性。用一个简单的实现来举例,一个3x3的卷积有C个fiters,输入尺寸C x H x W需要9HWC^2 的乘加,这个代价和3x3卷积有DC个filter,输入尺寸DCxH/DxW/D是一样的。在下采样之后,我们可以因此在相同计算代价下用一个更大的网络。
第二个好处是有效的感受野大小。高质量的风格转换需要一致的改变图片的一大块地方;因此这个优势就在于在输出中的每个像素都有输入中的大面积有效的感受野。除开下采样,每一个附加的3x3卷积层都能把感受野的大小增加2倍,在用因子D进行下采样后,每个3x3的卷积不是增加了感受野的大小到2D,给出了更大的感受野大小但有着相同数量的层。
残差连接:He[43]等人用了残差连接去训练非常深的网络用来做图像分类,它们证明了残差连接能让网络更容易的去学习确定的函数,这在图像转换网络中也是一个很有吸引力的研究,因为在大多数情况下,输出图像应该和输入图像共享结构。因此我们网络的大体由几个残差块组成,每个包含两个3x3的卷积层,我们用[44]中设计的残差块,在附录中有。
3.2 感知损失函数
我们定义了两个感知损失函数,用来衡量两张图片之间高级的感知及语义差别。要用一个预训练好用于图像分类的网络模型。在我们的试验中这个模型是VGG-16[46],使用Imagenet的数据集来做的预训练。

图4 和[10]一样,我们用了优化的方式去找到一张图y,最小化从VGG16的某几层取出来的风格损失。图像y只保存风格特征不保存空间结构。
特征(内容)损失:我们不建议做逐像素对比,而是用VGG计算来高级特征(内容)表示,这个取法和那篇artistic style使用VGG-19提取风格特征是一样的,公式:
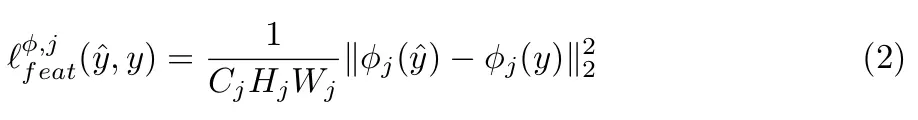
如在[ 6 ]和在图3重现的,找到一个图像 Y使较低的层的特征损失最小,往往能产生在视觉上和y不太能区分的图像,如果用高层来重建,内容和全局结构会被保留,但是颜色纹理和精确的形状不复存在。用一个特征损失来训练我们的图像转换网络能让输出非常接近目标图像y,但并不是让他们做到完全的匹配。
风格损失:特征(内容)损失惩罚了输出的图像(当它偏离了目标y时),所以我们也希望去惩罚风格上的偏离:颜色,纹理,共同的模式,等方面。为了达成这样的效果Gatys等人提出了以下风格重建的损失函数。
让φj(x)代表网络φ的第j层,输入是x。特征图谱的形状就是Cj x Hj x Wj、定义矩阵Gj(x)为Cj x Cj矩阵(特征矩阵)其中的元素来自于:
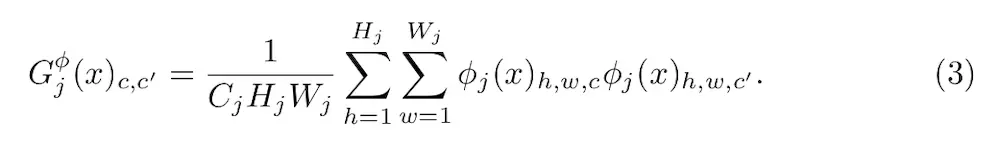
如果我们把φj(x)理解成一个Cj维度的特征,每个特征的尺寸是Hj x Wj,那么上式左边Gj(x)就是与Cj维的非中心的协方差成比例。每一个网格位置都可以当做一个独立的样本。这因此能抓住是哪个特征能带动其他的信息。梯度矩阵可以很搞笑的倍计算,通过调整φj(x)的形状为一个矩阵ψ,形状为Cj x HjWj,然后Gj(x)就是ψψT/CjHjWj。
风格重建的损失是定义的很好的,甚至当输出和目标有不同的尺寸是,因为有了梯度矩阵,所以两者会被调整到相同的形状。
就像[10]中介绍的,如图5重建,能生成一张图片y使得风格损失最小,从而保存了风格上的特征,但是不保存空间上的结构特征。
为了表示从一个集合层的风格重建,而不是由单层重建,我们把Lstyle(y^,y)定义成一个损失的集合(针对每一个层的损失求和)。
3.3简单损失函数
除了感知损失,我们还定义了两种简单损失函数,仅仅用了低维的像素信息
像素损失:像素损失是输出图和目标图之间标准化的差距。如果两者的形状都是CxHxW,那么像素损失就是Lpixel(y,y) = ||y^-y||₂²/CHW。这只能被用在我们有完全确定的目标,让这个网络去做完全匹配。
全变差正则化:为使得输出图像比较平滑,我们遵循了前人在特征反演上的研究[6,20],超分辨率重建上的研究[48,49]并且使用了全变差正则化lTV(y)。(全变差正则化一般用在信号去噪)
四. 实验
我们实验了两个图像变换任务:风格转换和单图超分辨率重建。风格转换中,前人使用优化来生成的图像,我们的前馈网络产生类似的定性结果,但速度快了三个数量级。单图像超分辨率中,用了卷积神经网络的都用的逐像素求差的损失,我们展示了令人振奋的的有质量的结果,通过改用感知损失。
4.1风格转换
风格转换的目标是产生一张图片,既有着内容图的内容信息,又有着风格图的风格信息,我们为每一种风格训练了一个图像转换网络,这几种风格图都是我们手工挑选的。然后把我们的结果和基础Gatys的结果做了对比。
基线:作为基线,我们重现了Gatys等人得方法,给出风格和内容目标ys和yc,层i和J表示特征和风格重建。y通过解决下述问题来获得。
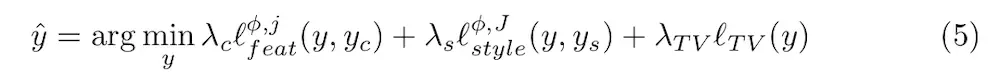
λ开头的都是参数,y初始化为白噪声,用LBFGS优化。我们发现,无约束的优化方程通常会导致输出图片的像素值跑到[0,255]之外,做一个更公平的比较,对基线,我们用L-BFGS投影,每次迭代都把图片y调整到[0,255],在大多数情况下,运算优化在500次迭代之内收敛到满意的结果,这个方法比较慢因为每一个LBFGS迭代需要前馈再反馈通过VGG16网络。
训练细节:我们的风格转换网络是用COCO数据集训练的,我们调整每一个图像到256x256,共8万张训练图,batch-size=4,迭代40000次,大约跑了两轮。用Adam优化,初始学习速率0.001.输出图被用了全变量正则化(strength 在1e-6到1e-4之间),通过交叉验证集选择。不用权重衰减或者dropout,因为模型在这两轮中没有过拟合。对所有的风格转换实验我们取relu2_2层做内容,relu1_2,relu2_2,relu3_3和relu4_3作为风格。VGG-16网络,我们的实验用了Torch和cuDNN,训练用了大约4个小时,在一个GTX Titan X GPU上。
定性结果:在图6中我们展示了结果的对比,比较了我们的记过和那些基础方法,用了一些风格和内容图。所有的参数λ都是一样的,所有的训练集都是从MS-COCO2014验证集里抽选的。我们的方法能达到和基本方法一样的质量。
尽管我们的模型是用256x256的图片训练的,但在测试时候可以用在任何图像上面,在图7中我们展示了一些测试用例,用我们的模型训练512大小的图片

图6,用我们的图像生成网络做图像风格转换。我们的结果和Gatys相似,但是更快(看表1)。所有生成图都是256x256的

图7我们的网络在512x512图上的测试样例,模型用一个全卷积操作来达成高分辨率的图像(测试时),风格图和图6一样。
通过这些结果可以明确的是,风格转换网络能意识到图像的语义内容。举个例子,在图7中的海滩图像,人们是很明显的被识别了出来,但背景被风格扭曲了;同样的,猫脸很明显的被识别了出来,但他的身体并没有被识别出来。一个解释是:VGG16网络是被训练用来分类的,所以对于图片的主体(人类和动物)的识别要比那些背景保留完整的多。
定量结果:基本方法和我们的方法都是使公式5最小化。基本方法针对一张图进行明确的优化(针对要输出的图像)我们的方法训练一个解决方案(能在前馈中处理任意一张图片Yc)我们可以量化的比较这两种方法,通过衡量它们成功减少代价函数的幅度。(公式5)
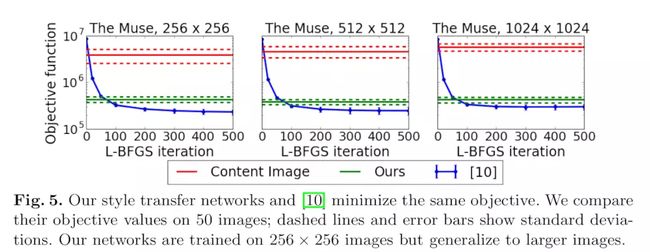
我们用我们的方法和它们的方法一起训练了五十张图片(从MSCOCO验证集中得到)使用The Muse by Pablo Picasso当作一个风格图。对于基础方法我们记录了函数在每一个迭代过程的值。对我们的方法我们对每一张图片记录了公式5的值。我们还计算了公式5的值,当y和输出图像yc相等时,结果显示在表5,我们看到内容图Yc达到了非常高的损失,和我们的方法在50-100之间差不多。
尽管我们的网络用256x256的尺寸训练的,但他们在512,1024的情况下都能成功的使代价函数最小化,结果展示在表5中。我们可以看到哪怕在高分辨率下,和普通方法达成相同损失的时间也差不多。

表1 速度(秒级)的比较:我们的网络vs普通的基于优化的网络。我们的方法能给出相似质量的结果,(看图6)但能加速百倍。两种方法都是在GTX TitanX GPU上测试的。
速度:在表1中我们比较了运行的时间(我们的方法和基础方法)对于基础方法,我们记录了时间,对所有的图像大小比对,我们可以看出我们方法的运行时间大致是基本方法迭代一次时间的一半。跟基本方法500次迭代的相比,我们的方法快了三个数量级。我们的方法在20fps里产生512x512的图片,让他可能应用在实时图像转换或者视频中。
4.2 单图超分辨率重建
在单图超分辨率重建中,任务是从一个低分辨率的输入,去产生一个高分辨率的输出图片。这是一个固有的病态问题,因为对一个低分辨率图像,有可能对应着很多种高分辨率的图像。当超分辨率因子变大时,这个不确定性会变得更大。对于更大的因子(x4 x8),高分辨率图像中的好的细节很可能只有一丁点或者根本没有出现在它的低分辨率版本中。
为了解决这个问题,我们训练了超分辨率重建网络,不使用过去使用的逐像素差损失函数,取而代之的是一个特征重建损失函数(看section 3)以保证语义信息可以从预训练好的损失网络中转移到超分辨率网络。我们重点关注x4和x8的超分辨率重建,因为更大的因子需要更多的语义信息。
传统的指标来衡量超分辨率的是PSNR和SSIM,两者都和人类的视觉质量没什么相关的[55,56,57,58,59].PSNR和SSIM仅仅依赖于像素间低层次的差别,并在高斯噪声的相乘下作用,这可能是无效的超分辨率。另外的,PSNR是相当于逐像素差的,所以用PSNR衡量的模型训练过程是让逐像素损失最小化。因此我们强调,这些实验的目标并不是实现先进的PSNR和SSIM结果,而是展示定性的质量差别(逐像素损失函数vs感知损失)
模型细节:我们训练模型来完成x4和x8的超分辨率重建,通过最小化特征损失(用vgg16在relu2_2层提取出),用了288x288的小块(1万张MSCOCO训练集),准备了低分辨率的输入,用高斯核模糊的(σ=1.0)下采样用了双立方插值。我们训练时bacth-size=4,训练了20万次,Adam,学习速率0.001,无权重衰减,无dropout。作为一个后续处理步骤,我们执行网络输出和低分辨率输入的直方图匹配。
基础:基本模型我们用的 SRCNN[1] 为了它优秀的表现,SRCNN是一个三层的卷积网络,损失函数是逐像素求差,用的ILSVRC2013数据集中的33x33的图片。SRCNN没有训练到x8倍,所以我们只能评估x4时的差异。
SRCNN训练了超过1亿次迭代,这在我们的模型上是不可能实现的。考虑到二者的差异(SRCNN和我们的模型),在数据,训练,结构上的差异。我们训练图片转换网络x4,x8用了逐像素求差的损失函数,这些网络使用相同搞得数据,结构,训练网络去减少lfeat评测:我们评测了模型,在标准的集合5[60],集合6[61],BSD100[41]数据集,我们报告的PSNR和SSIM[54],都只计算了在Y通道上的(当转换成YCbCr颜色空间后),跟[1,39]一样。
结果:我们展示了x4倍超分辨率重建的结果(图8),和其他的方法相比,我们的模型用特征重建训练的,得到了很好的结果,尤其是在锋锐的边缘和好的细节,比如图1的眼睫毛,图2帽子的细节元素。特征重建损失在放大下引起轻微的交叉阴影图案,和基础方法比起来更好。

x8倍放大展示在图9中,我们又一次看到我们的模型在边缘和细节上的优秀。比如那个马的脚。lfeat模型不会无差别的锐化边缘;和lpixel模型相比,lfeat模型锐化了马和骑士的边缘,但是北京的树并没被锐化。可能是因为lfeat模型更关注图像的语义信息。

因为我们的Lpixel和lfeat模型有着相同的结构,数据,和训练过程,所以所有的差别都是因为lpixel和lfeat的不同导致的。lpixel给出了更低的视觉效果,更高的PSNR值,而lfeat在重建细节上有着更好的表现,有着很好的视觉结果。
5. 结论
在这篇文章中,我们结合了前馈网络和基于优化的方法的好处,通过用感知损失函数来训练前馈网络。我们对风格转换应用了这个方法达到了很好的表现和速度。对超分辨率重建运用了这个方法,证明了用感知损失来训练,能带来更多好的细节和边缘。
未来的工作中,我们期望把感知损失函数用在更多其他的图像转换任务中,如上色或者语义检测。我们还打算研究不同损失网络用于不同的任务,或者更多种不同的语义信息的数据集
作者:zhwhong
链接:https://www.jianshu.com/p/b728752a70e9
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。