试想一下:Tesla自动驾驶、华尔街自动交易算法、智能家居、能够实现日内闪电般运抵的交通网络和纽约市警察局发布的开放数据,它们都有哪些共同点?
一方面,它们预示着我们的世界正以曲速般变化,我们捕获和解析的数据比以往更多,速度比以往更快。
但是,如果仔细观察你会发现,这些应用程序都需要一种特殊的数据:
- 自动驾驶汽车持续收集所处环境中的变化数据
- 自动交易算法持续收集市场的变化数据
- 智能家居系统持续监控房屋内的变化,调整温度,识别侵入者,对于使用者总是有求必应(“Alexa,播放一些轻松的音乐”)。
- 零售行业精确高效地监控资产运转状况,使得日内运抵的成本足够低廉且能够为绝大多数人所使用。
- 纽约警察局通过跟踪车辆来更好地履行其职责(例如,分析911报警电话的响应次数)
这些应用程序均依赖一种衡量事物随时间的变化的数据形式,这里的时间不只是一个度量标准,而是一个坐标的主坐标轴。
这就是时间序列数据,它渐渐在我们的世界中发挥更大的作用。
软件开发人员的使用模式早已反映了这一点,在过去的24个月中,时间序列数据库(TSDB)已经成为增长最快的类别:
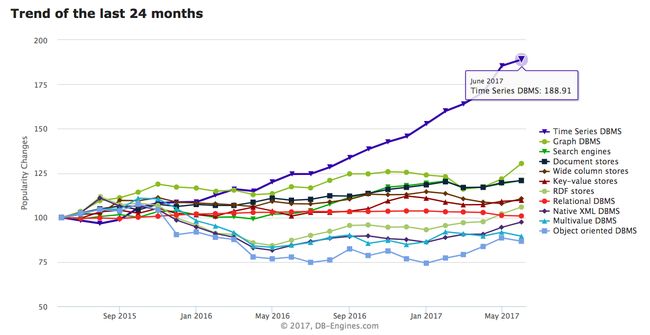
数据来源:DB-Engines,2017年6月. https://db-engines.com/en/ranking_categories
我们开发了一款新的开源时间序列数据库,经常有人问TSDB的趋势如何,他们通常会问以下三个问题:
- 时间序列数据是什么?
- 何时需要使用时间序列数据库?
- 使用(或不使用)TimescaleDB的理由是什么?
起初,这些材料是为我们在4月份开源数据库大会Percona Live中的演讲而准备的,现在我们将其发布在本文中,并在深思熟虑后尝试具体回答一下这些问题,并尽可能分享给更多的人。
那么我们开始吧。
时间序列数据是什么?
有些人将“时间序列数据”视为按时间顺序存储的一连串随时间推移测量相同事物的数据点,这样解释没错,但只描述了浅层信息。
其他人可能会认为是一连串与时间戳配对的数值,这些数值由一个名称和一组归类维度(或称“标签”)所定义。这也许是一种为时间序列数据建模的方式,却不是数据自身的定义。
我们继续深入。
以下是一个基础示例,设想这个传感器从三个环境中收集数据:分别是城市、农场和工厂。在这里,每一个数据源定期发送新的读数,创建一系列随时间推移收集到的测量结果。
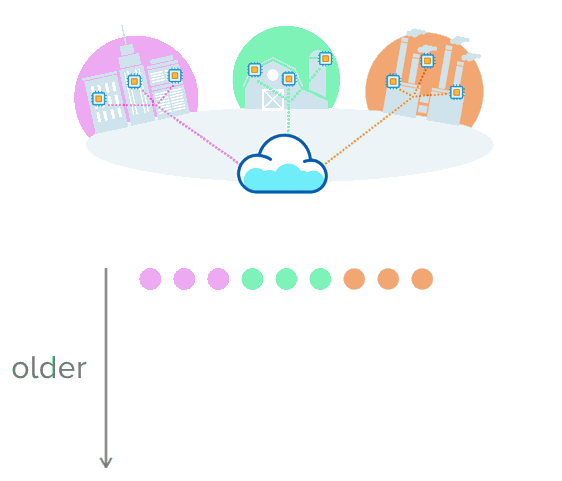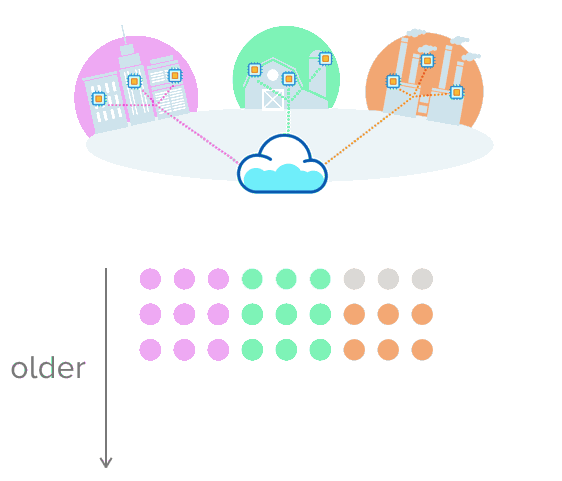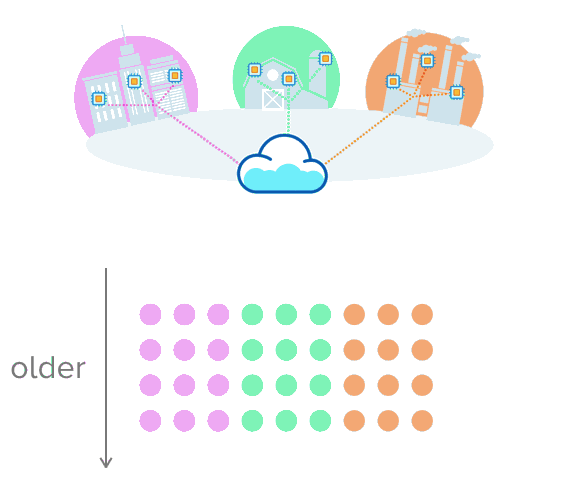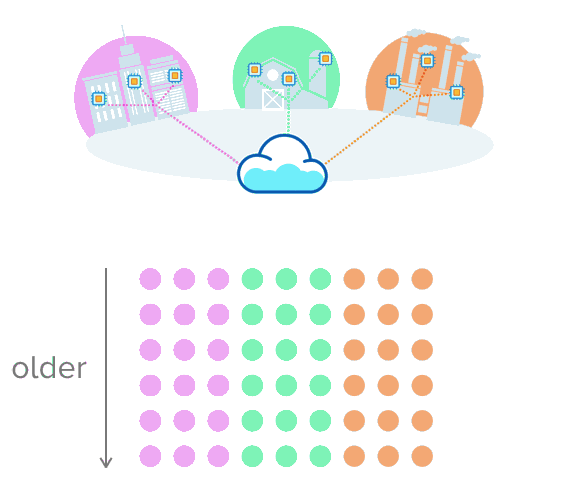
接下来是另一个示例,这是一份纽约市的实际数据,这些数据展示了2016年前几秒出租车的乘坐情况。正如你所见,每一行都是在特定时间收集的“测量结果”。

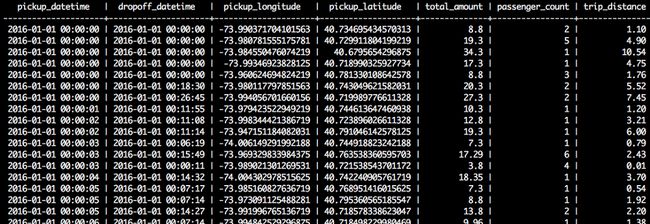
2016年前几秒纽约出租车乘坐数据。数据源:http://www.nyc.gov/html/tlc/html/about/trip_record_data.shtml
还有许多其他类型的时间序列数据,例如:DevOps监控数据、移动/Web应用程序事件流、工业机器数据、科学测量结果。
这些数据集主要有以下三个共同点:
- 抵达的数据几乎总是作为新条目被记录
- 数据通常按照时间顺序抵达
- 时间是一个主坐标轴(既可以是规则的时间间隔,也可以是不规则的)
换句话说,时间序列数据的处理过程通常是伴随数据的抵达而进行的。虽然在事后需要纠正错误的数据,或处理延迟数据或无序数据,但这些都是例外情况,不属于标准范畴。
你可能会问:这与在数据库中添加字段有何区别?
那么,这取决于:你的数据集如何跟踪变化?是更新当前条目,还是插入新的条目?
当你为sensor_x收集新读数时,是覆盖以往的读数,还是在新的一行创建全新的读数?尽管这两种方法都能为你提供系统的当前状态,但只有第二种方法才能跟踪系统的所有状态。
简而言之:时间序列数据集跟踪整个系统的改动并不断插入新数据,而不是更新原有数据。
时间序列数据之所以如此强大,是因为将系统的每个变化都记录为新的一行,从而可以去衡量变化:分析过去的变化,监测现在的变化,以及预测未来将如何变化。
因此,我们这样定义时间序列数据:统一表示系统、过程或行为随时间变化的数据。
这不仅是一个学术上的区别:通过围绕“变化”的定义,我们可以开始找出当下我们应该收集却没有收集的时间序列数据集。
事实上,我们发现人们早已坐拥时间序列数据,但他们却没意识到这一点。
假设你正在维护一个Web应用程序,每次用户登录时,你可以在“users”表的某行中更新用户的“last_login”时间戳,但是如果将每次登录作为一个单独的事件处理,并随着时间推移收集这些数据又会有怎样的效果?届时你可以:跟踪历史登录活动,了解随时间推移用户使用的增减情况,根据访问App的频率或更多指标区分用户。
这个示例说明了一个关键点:通过保留数据固有的时间序列性质,我们能够保留有关数据随时间变化的有用信息。
(事实上,这个示例还说明了另一点:事件数据同样也是时间序列数据)
当然,按照这种方式存储数据会带来一个明显的问题:最终你会以相当快的速度得到大量的数据,时间序列数据很快会堆积起来。
数据量太大会给记录和查询操作带来严重的性能问题
这也是人们正逐渐转向时间序列数据库的原因。
我为什么需要一个时间序列数据库?
你可能会问:为什么我不能用一个“常规”(也就是非时间序列)的数据库?
事实上你可以使用非时间序列数据库,也确实有人这样做:
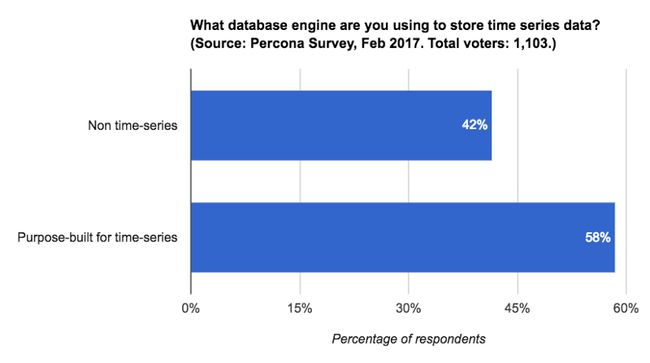
数据源:Percona,2017年2月. https://www.percona.com/blog/2017/02/10/percona-blog-poll-database-engine-using-store-time-series-data/
那么为什么大部分调查对象使用时间序列数据库而不是常规数据库呢?为什么TSDB如今成为增长最快的数据库?
有两个原因:(1)规模(2)可用性
规模:时间序列数据累计速度非常快。(例如,一辆联网汽车每小时能收集25GB数据。)常规数据库在设计之初并非处理这种规模的数据,关系型数据库处理大数据集的效果非常糟糕;NoSQ数据库L可以很好地处理规模数据,但是让然比不上一个针对时间序列数据微调过的数据库。相比之下,时间序列数据库(可以基于关系型数据库或NoSQL数据库)将时间视作一等公民,通过提高效率来处理这种大规模数据,并带来性能的提升,包括:更高的容纳率(Ingest Rates)、更快的大规模查询(尽管有一些比其他数据库支持更多的查询)以及更好的数据压缩。
可用性:TSDB通常还包括一些共通的对时间序列数据分析的功能和操作:数据保留策略、连续查询、灵活的时间聚合等。即使当下不考虑规模(例如,您刚开始收集数据),这些功能仍可提供更好的用户体验,使你的生活更轻松。
这就是为什么开发人员越来越多地采用时间序列数据库,并将它们用于各种使用场景的原因:
- 监控软件系统: 虚拟机、容器、服务、应用
- 监控物理系统: 设备、机器、接入的设备、环境、我们的房屋、我们的身体
- 资产跟踪应用: 汽车、卡车、物理容器、运货托盘(Pallets)
- 金融交易系统: 传统证券、新兴的加密数字货币
- 事件应用程序: 跟踪用户、客户的交互数据
- 商业智能工具: 跟踪关键指标和业务的总体健康情况
- 更多场景
但即使如此,你仍需选择最适合你的数据模型和写入和读取模式的时间序列数据库。
使用(或不使用)TimescaleDB的理由是什么?
如果你确实需要一个时间序列数据库,已经有相当多的现成选择。你可能对某一个感到满意,但我们并未满足。
为什么我们对最先进的仍不满足?因为我们希望在大规模数据上应用SQL的全部能力,现有的数据库无一具备这项能力。
具体来说,我们发现现有的时间序列数据库:
- 在我们的许多查询试验中表现不佳(解读:高延迟)
- 甚至都不支持许多其他的查询(因数据库而异)
- 要求我们学习一门新的查询语言(解读:不是SQL语言)
- 不能与我们现有的大多数工具合用(解读:糟糕的兼容性)
- 要求我们将数据分为两个数据库:一个“常规”的关系数据库,还有一个时间序列数据库(解读:操作与开发过程极为头痛)
所以我们打造了TimescaleDB,因为我们需要它。后来其他人也想使用这个数据库,所以今年早些时候我们根据基于Apache 2的许可开源。
你何时应该考虑使用TimescaleDB?如果你想:
- 一个普通的SQL接口,用于时间序列数据,甚至是大规模数据
- 操作简单:一个数据库同时存放关系型数据和时间序列数据
- 连接(JOINs) 查询时跨关系型数据和时间序列数据连接
- PostgreSQL!(Timescale的行为表现就像PostgreSQL一样)
- 查询性能,尤其是对于广泛而多样化的查询(通过强大的二级索引支持)
- 原生支持地理空间数据 (兼容PostGIS)
- 第三方工具:Timescale支持任何使用SQL的工具,包括像Tableau这样的BI工具
同样,如果满足下列条件中的任意一条,你可能不太希望使用TimescaleDB:
- 如果你只有简单的查询模式(例如,键值查找、一维汇总)。其他数据库针对此类查询的优化更彻底。
- 如果你有稀疏数据或完全非结构化的数据 虽然TimescaleDB支持结构化和半结构化数据(包括JSON),但如果你的数据一般是稀疏或完全非结构化的,那么其他数据库中还有更好的选择。
但是,如果TimescaleDB看起来很有趣或有用,我们欢迎你进一步了解它,下载并安装,尝试一下。(亦可访问项目的Github,欢迎Star。)
延展思考:是否所有数据都是时间序列数据?
我们先回归时间序列数据话题本身。
过去十多年以来,我们生活在“大数据”时代,收集了大量有关我们所处世界的信息,并运用计算资源来理解它。尽管这个时代始于适度计算(Modest Computing)技术,但由于存在摩尔定律(Moore’s Law)、克拉底定律(Kryder’s Law)、云计算以及整个“大数据”技术产业这些主要的宏观趋势,我们捕获、存储和分析数据的能力已经以指数级的速度得到提高。
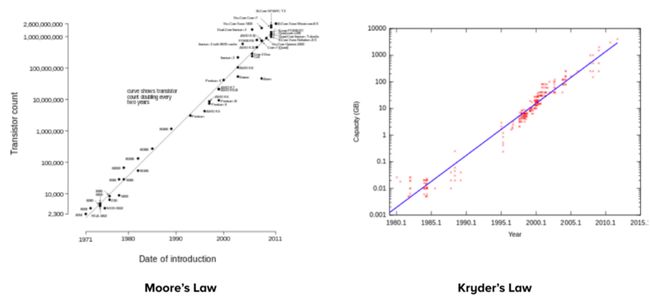
根据摩尔定律,计算能力(晶体管密度)每18个月翻一番,而克拉底定律则假定存储容量每12个月翻一番。
现在我们不再满足于观察世界状态,想要的更多,我们想度量世界随亚秒级别时间推移的变化。我们的“大数据”数据集现在正被另一种数据超越,这些数据在很大程度上依赖时间来保存正在发生的变化的信息。
但是否所有数据一开始都是时间序列数据? 回顾我们早期的Web应用示例:我们其实已坐拥时间序列数据,只是当时没有意识到。
或者想一下任何“常规”数据集,例如主流零售银行活期账户和余额、软件项目的源代码或这篇博客文章的文本。
通常我们选择存储系统的最新状态。但是如果我们反过来存储每个变化,并在查询时计算最新的状态又会如何?“常规”数据集是不是很像相应时间序列数据集的顶层视图,只是考虑到性能原因先被缓存了起来?银行是不是有交易账本?(区块链是不是分布式、不可修改的时间序列记录?)一个软件项目是不是要有版本控制(例如,Git Commit?)这篇博客文章是不是有修订历史?(撤销、重做。)
换句话说:是否所有数据集都有日志?
我们注意到许多应用程序可能永远不需要时间序列数据(而且使用“当前状态视图”效果更好)。但是随着技术进步的指数曲线的不断向前发展,似乎这些“当前状态视图”变得不是很必要了。只有以时间序列形式存储更多的数据,我们才能够更好地了解它。
是否所有数据都是时间序列数据?我们尚未找到一个很好的范例,如果你有幸找到,我们愿洗耳恭听。
无论如何,有一件事情是清楚的:时间序列数据已经出现在我们周围,现在是时候将其投入使用。
感谢阅读我们的博文,如果你觉得这篇文章有帮助并推荐或分享,我们在此表示感谢。
如果您有任何后续问题或意见,可以通过email或Twitter发送给我们。
如果您想了解有关TimescaleDB的更多信息,请查看我们的GitHub,如需帮助请联系我们。
查看英文原文:https://blog.timescale.com/what-the-heck-is-time-series-data-and-why-do-i-need-a-time-series-database-dcf3b1b18563