关系抽取概述及研究进展Relation Extraction Progress
关系抽取的概述及研究进展
- 关系抽取任务概述
- 关系抽取的定义
- 关系抽取的公开的主流评测数据集
- ACE 2005
- SemiEval 2010 Task8 Dataset:
- NYT(New York Times Corpus)
- TACRED数据集
- fewshot数据集(清华)
- 关系抽取的主流方法
- 数据集榜单
- NYT数据集最新论文效果榜单
- SemEval-2010 Task 8数据集最新论文效果榜单
- TACRED数据集及最新榜单
- FewRel
- 关系抽取相关的经典论文
- 相关代码资源
- 参考文献
关系抽取任务概述
下面主要从关系抽取的定义、关系抽取的主流评测数据集、关系抽取的主流方法、关系抽取相关的经典论文、相关代码资源几个方面进行介绍。
转载请注明出处:https://blog.csdn.net/CSDN_wujian/article/details/100136621
关系抽取的定义
关系抽取是从一段文本中提取出发生在两个实体或多个实体之间的语义关系的任务。关系抽取Relation Extraction,也称关系分类Relation Classification(判断实体Entity之间属于哪种关系,多分类问题)
根据处理数据源的不同,关系抽取可以分为以下三种:
- 面向结构化文本的关系抽取:包括表格文档、XML文档、数据库数据等
- 面向非结构化文本的关系抽取:纯文本
- 面向半结构化文本的关系抽取:介于结构化和非结构化之间
根据抽取文本的范围不同,关系抽取可以分为以下两种:
- 句子级关系抽取:从一个句子中判别两个实体间是何种语义关系
- 语料(篇章)级关系抽取:不限定两个目标实体所出现的上下文
根据所抽取领域的划分,关系抽取又可以分为以下两种:
- 限定域关系抽取:在一个或者多个限定的领域内对实体间的语义关系进行抽取,限定关系的类别,可看成是一个文本分类任务
- 开放域关系抽取:不限定关系的类别
关系抽取的公开的主流评测数据集
ACE 2005
包含599 docs. 定义了7 种关系
(收费的)官网:https://www.ldc.upenn.edu/language-resources/data/obtaining,官网注册会员,花钱购买
SemiEval 2010 Task8 Dataset:
- 19 types
- train data: 8000, test data: 2717
- 关系:Cause-Effect、Instrument-Agency、Product-Producer、Content-Container、Entity-Origin、Entity-Destination、Component - Whole、Member-Collection、Message-Topic、Other
- 数据集介绍:https://blog.csdn.net/qq_29883591/article/details/88567561
NYT(New York Times Corpus)
NYT是远监督关系抽取(distantly supervised relationship extraction)所用的标准预料数据,发布于 Riedel et al, 2010.该篇论文中。
包含的文本来源于纽约时报New York Times所标注的语料,其中的命名实体是通过 Stanford NER 工具并结合 Freebase知识库进行标注的。命名实体对之间的关系是链接和参考外部的Freebase知识库中的关系,结合远监督方法所得到的。
Example:
Elevation Partners, the $1.9 billion private equity group that was founded by Roger McNamee
(founded_by, Elevation_Partners, Roger_McNamee)
- 53 种关系
- train data: 522611 sentences; 需要注意的是,这里面有近80%的句子的标签为NA
- test data: 172448 sentences;
TACRED数据集
TACRED 是一个大规模的关系抽取数据集,包含106,264 样本,和41种关系类型,文本内容主要是新闻文本和 TAC Knowledge Base Population (TAC KBP) 竞赛的文本语料. 例如(e.g., per:schools_attended and org:members) or “no_relation ” 这些样本来自于TAC KBP 竞赛中的人为标注和众包。
Example:
Billy Mays, the bearded, boisterious pitchman who, as the undisputed king of TV yell and sell, became an inlikely pop culture icon, died at his home in Tampa, Fla, on Sunday.
(per:city_of_death, Billy Mays, Tampa)
fewshot数据集(清华)
The Few-Shot Relation Classification Dataset (FewRel) .该数据集包含70000条句子,100种关系,每种关系包含700条句子。通过 Wikipedia 语料和众包完成。The few-shot learning(小样本学习) task follows the C-way K-shot meta learning setting. 它是目前最大的监督关系抽取的数据集,也是目前最大的FewShot学习的数据集,FewRel数据获取
关系抽取的主流方法
- 有监督的学习方法:该方法将关系抽取任务当做分类问题,根据训练数据设计有效的特征,从而学习各种分类模型,然后使用训练好的分类器预测关系。该方法的问题在于需要大量的人工标注训练语料,而语料标注工作通常非常耗时耗力。
- 半监督的学习方法:该方法主要采用Bootstrapping进行关系抽取。对于要抽取的关系,该方法首先手工设定若干种子实例,然后迭代地从数据从抽取关系对应的关系模板和更多的实例。
- 无监督的学习方法:该方法假设拥有相同语义关系的实体对拥有相似的上下文信息。因此可以利用每个实体对对应上下文信息来代表该实体对的语义关系,并对所有实体对的语义关系进行聚类。
这三种方法中,有监督学习法因为能够抽取并有效利用特征,在获得高准确率和高召回率方面更有优势,是目前业界应用最广泛的一类方法。
限定域关系抽取方法:
- 基于模板的关系抽取方法:通过人工编辑或者学习得到的模板对文本中的实体关系进行抽取和判别,受限于模板的质量和覆盖度,可扩张性不强
- 基于机器学习的关系抽取方法:将关系抽取看成是一个分类问题
其中基于机器学习的关系抽取方法又可分为 有监督 和 弱监督。
有监督的关系抽取方法:
- 基于特征工程的方法:需要显示地将关系实例转换成分类器可以接受的特征向量
- 基于核函数的方法:直接以结构树为处理对象,在计算关系之间距离的时候不再使用特征向量的内积而是用核函数
- 基于神经网络的方法:直接从输入的文本中自动学习有效的特征表示,端到端
弱监督的关系抽取方法:不需要人工标注大量数据。
- 远监督方法(distant supervision):用开放知识图谱自动标注训练样本,不需要人工逐一标注,属弱监督关系抽取的一种。
开放域关系抽取方法:
- 不需要预先定义关系类别,使用实体对上下文中的一些词语来描述实体之间的关系。
华盛顿大学课程中关系分类的方法总结:
- Hand-built patterns
- Bootstrapping methods
- Supervised methods
- Distant supervision
- Unsupervised methods
Supervised RE: summary
- Supervised approach can achieve high accuracy
- At least, for some relations
- If we have lots of hand-labeled training data
- But has significant limitations!
- Labeling 5,000 relations (+ named entities) is expensive
- Doesn’t generalize to different relations
- Next: beyond supervised relation extraction
- Distantly supervised relation extraction
- Unsupervised relation extraction
Reference:https://courses.cs.washington.edu/courses/cse517/13wi/slides/cse517wi13-RelationExtraction.pdf
数据集榜单
参考:http://nlpprogress.com/english/relationship_extraction.html
NYT数据集最新论文效果榜单
The main metrics used are either precision at N results or plots of the precision-recall
评测指标:横坐标为召回率Recall,纵坐标为精准率Precision,画出PR(precision-recall)曲线,例如目前最新最好的效果为Recall=0.1时,Precision=0.849;Recall=0.3时,Precision=0.728
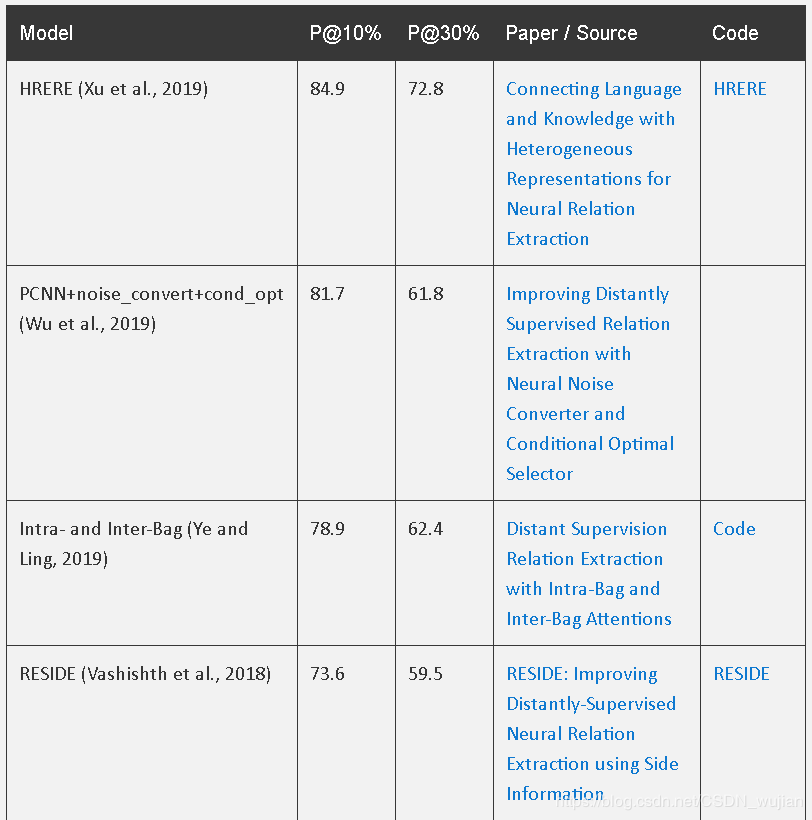
SemEval-2010 Task 8数据集最新论文效果榜单
评测指标:macro-averaged F1,在评测时不考虑“Other”这一种关系。
对各个混淆矩阵分别计算Precision和Recall,从而使用宏精准率macro_precison、宏召回率macro_recall、宏F1 macro_F1

![]()
分类模型的效果评估

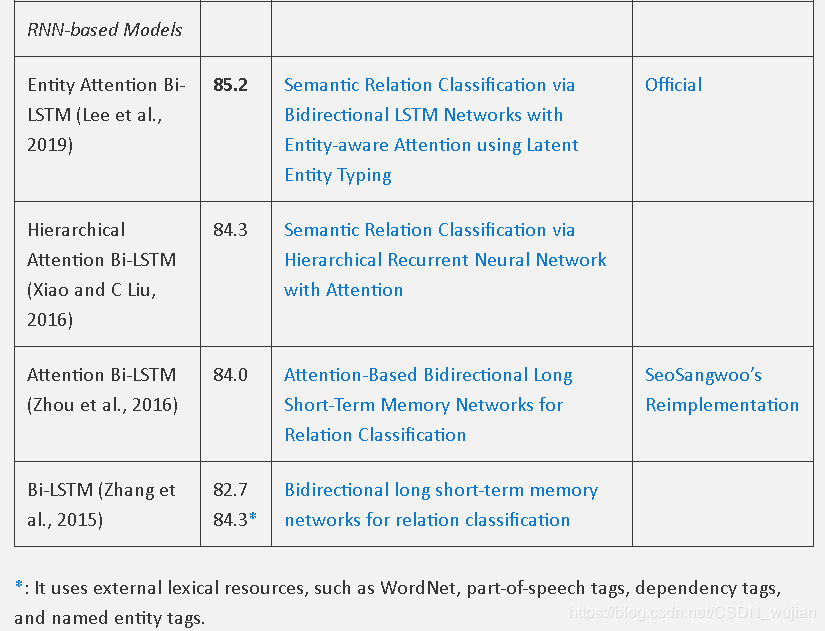
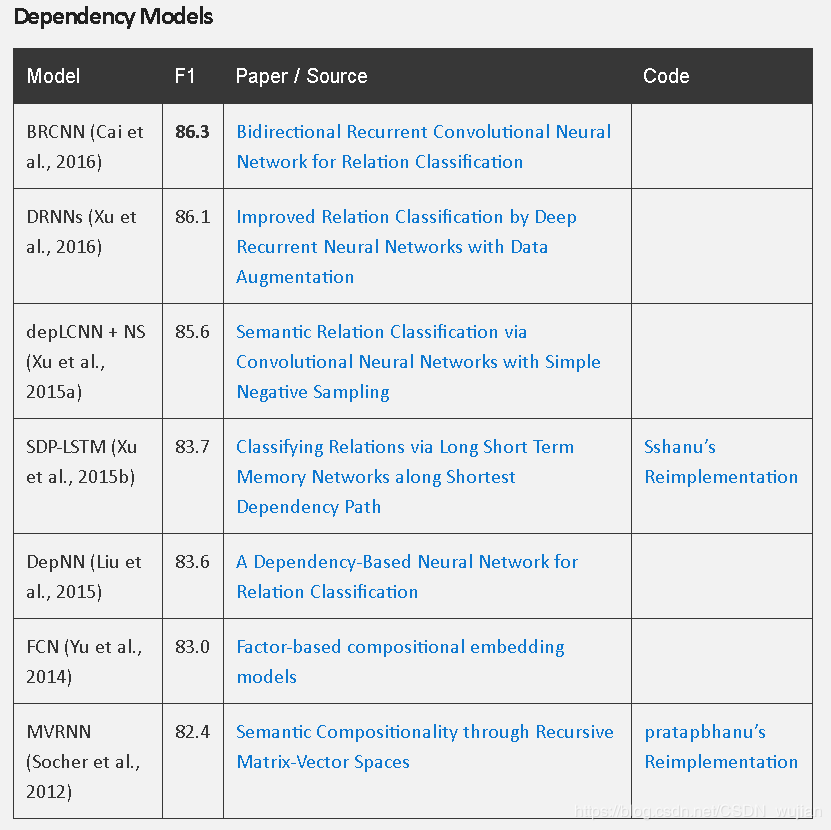
TACRED数据集及最新榜单
The main evaluation metric used is micro-averaged F1 over instances with proper relationships (i.e. excluding the no_relation type).
micro_F1: 对各混淆矩阵中对应元素(TP、FN、FP、TN)分别求平均值,从而使用微精准率micro_precison、微召回率micro_recall、微F1 micro_F1
![]()
![]()

FewRel
few-shot learning:样本种类很多,选取其中的C个类别进行学习,每个类别选取K个样本,进行学习,然后预测这C个类别中样本,即C-Way-K-Shot小样本学习,内在主要是判断每种类别之间的差异,相似样本之间进行类比。例如,小朋友学习认识小动物,选取5种动物,每种动物选取2张照片,进行学习,然后在一堆这5种动物的照片给他指认,这就是一个5-Way-2-Shot的一个小样本学习。FewShot介绍
http://www.zhuhao.me/fewrel/
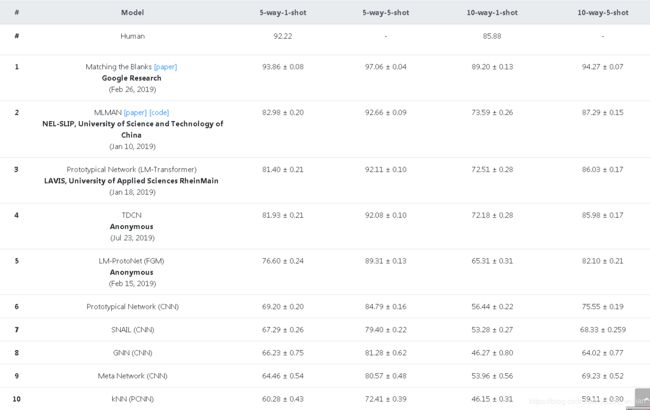
关系抽取相关的经典论文
https://www.cnblogs.com/theodoric008/p/7874373.html
-
Relation Classification via Convolutional Deep Neural Network
论文信息:Zeng et al. Proceedings of COLING 2014
模型名称:DNN
论文内容:第一次把CNN卷积神经网络用在关系分类中,使用Lexical Level Features特征:实体1词向量、实体2词向量、实体1的左右词的词向量、实体2的左右词的词向量、实体1和实体2在Wordnet中的上位语义词的词向量,以及 Sentence Level Features特征:[Word Features, Position Features],最后将Lexical Level Features和 Sentence Level Features进行拼接,利用CNN,max pooling进行分类。在SemEval2008数据集上实现了F值0.827的效果。该论文开启了CNN深度学习模型在关系抽取的先河,后续很多论文都引用这篇论文。
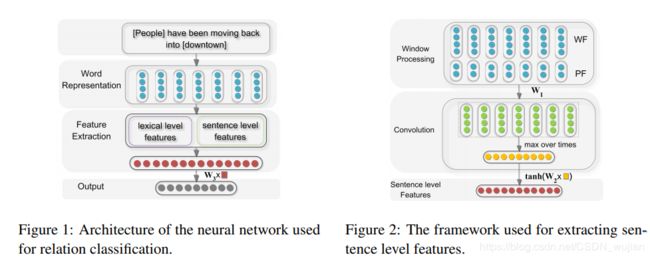
-
Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks
论文信息:Zeng et al. 2015 EMNLP
模型名称:PCNN
论文内容:非常经典的文章,分段式的max pooling -
Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification
作者信息:中科大自动化所 Zhou ACL 2016
模型名称:BLSTM + ATT
论文内容:简单有效。使用BLSTM对句子建模,并使用word级别的attention机制。 -
Neural Relation Extraction with Selective Attention over Instances
作者信息:清华 Lin et al. 2016
模型名称:CNN+ATT / PCNN+ATT
论文内容:使用CNN/PCNN作为sentence encoder, 并使用句子级别的attention机制。近几年标杆的存在,国内外新论文都要把它拖出来吊打一遍。 -
Deep Residual Learning forWeakly-Supervised Relation Extraction
作者信息:Yi Yao Huang 台湾国立大学 EMNLP 2017
模型名称:ResCNN-9
论文内容:本文使用浅层(9)ResNet作为sentence encoder, 在不使用piecewise pooling 或者attention机制的情况下,性能和PCNN+ATT 接近。这就证明使用更fancy的CNN网络作为sentence encoder完全是有可能有用的。不光光可以在本任务中验证,其他的NLP任务同样可以使用。可以参考知乎笔记: https://zhuanlan.zhihu.com/p/31689694 -
Distant Supervision for Relation Extraction with Sentence-Level Attention and Entity Descriptions
作者信息:Ji 2017 中科院自动化所 AAAI 2017
模型名称:APCNNs(PCNN + ATT) + D
论文内容:引入实体描述信息,个人认为没什么亮点,引入外部信息固然有效,但是很多时候实际问题中遇到的实体大多是找不到实体描述信息的。参考知乎笔记: https://zhuanlan.zhihu.com/p/35051652 -
论文名称: Learning with Noise: Enhance Distantly Supervised Relation Extraction with Dynamic Transition Matrix
作者信息: ACL 2017 Luo 北大
模型名称:CNN + ATT + TM (这名字是我给起的)
论文内容:文章出发点很好。既然远程监督数据集最大的问题在于噪音非常之多,那么对于噪音进行描述则是非常有意义的。本文创新点有两个。第一个是,我们让模型先学习从输入空间到真实标签空间的映射,再用一个转移矩阵学习从真实标签空间到数据集标签空间的错误转移概率矩阵。这不是本文提出的方法,本文在此基础之上进行改进,将该矩阵从全局共享转化为跟输入相关的矩阵,也就是文中提到的动态转移矩阵,性能有提升。第二个出创新点在于使用了课程学习。课程学习的出发点在于模型如果先学习简单样本再学习难样本,这样一种先易后难的学习方式比随机顺序学习更好。最终在NYT数据集上有小小的提升,但是本文的思路非常值得借鉴。可只可惜没有源代码。参考知乎笔记 https://zhuanlan.zhihu.com/p/36527644 -
Effectively Combining RNN and CNN for Relation Classification and Extraction
作者信息: SemEval 2018 四项任务 三项第一,一项第二 ETH Zurich
模型名称:作者没起名字
论文内容:这是一篇打比赛的文章,工程性的内容很多。核心技巧在于使用CNN, RNN模型集成。文中还提到了多种方法,不择手段提升最终模型的性能。虽然该模型训练速度可以说是非常慢了,但是还是有很多地方可以借鉴。 参考知乎笔记:https://zhuanlan.zhihu.com/p/35845948 -
Joint Extractions of Entities and Relations Based on a Novel Tagging Scheme
作者信息: Zheng 2017 中科院自动化所
模型名称:LSTM-CRF, LSTM-LSTM,LSTM-LSTM-Bias
论文内容:把关系抽取内容转换成序列标注任务 参考知乎笔记https://zhuanlan.zhihu.com/p/31003123
相关代码资源
https://github.com/thunlp/OpenNRE
https://github.com/crownpku/Information-Extraction-Chinese
https://github.com/thunlp/NRE
https://github.com/bojone/kg-2019
https://github.com/thunlp/FewRel
https://github.com/ShomyLiu/pytorch-relation-extraction
https://github.com/buppt/ChineseNRE
https://github.com/yuanxiaosc/Entity-Relation-Extraction
https://github.com/hadyelsahar/CNN-RelationExtraction
https://github.com/yuhaozhang/tacred-relation
https://github.com/roomylee/cnn-relation-extraction
https://github.com/lawlietAi/pytorch-acnn-model
https://github.com/ShulinCao/OpenNRE-PyTorch
https://github.com/thunlp/JointNRE
https://github.com/darrenyaoyao/ResCNN_RelationExtraction
https://github.com/Sshanu/Relation-Classification-using-Bidirectional-LSTM-Tree
https://github.com/yuanxiaosc/Schema-based-Knowledge-Extraction
https://github.com/thunlp/Chinese_NRE
参考文献
分类模型的效果评估
关系抽取(分类)总结:http://shomy.top/2018/02/28/relation-extraction/
知识图谱数据构建的“硬骨头”,阿里工程师如何拿下?
CIPS青工委学术专栏第3期 | 基于深度学习的关系抽取
实体关系抽取 entity relation extraction 文献阅读总结
读书笔记:关系抽取和事件抽取
Relation Extraction Survey