评测指标(metrics)
评测指标(metrics)
metric主要用来评测机器学习模型的好坏程度,不同的任务应该选择不同的评价指标, 分类,回归和排序问题应该选择不同的评价函数. 不同的问题应该不同对待,即使都是 分类问题也不应该唯评价函数论,不同问题不同分析.
回归(Regression)
- 均方误差(MSE)
(1) l ( y , y ^ ) = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 l(y, \hat{y})=\frac{1}{n}\sum_{i=1}^{n}(y_i-\hat{y}_i)^2 \tag{1} l(y,y^)=n1i=1∑n(yi−y^i)2(1)
- 均方根误差(RMSE)
(2) l ( y , y ^ ) = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 l(y, \hat{y})=\sqrt{\frac{1}{n}\sum_{i=1}^{n}(y_i-\hat{y}_i)^2} \tag{2} l(y,y^)=n1i=1∑n(yi−y^i)2(2)
- 平均绝对误差(MAE)
(3) l ( y , y ^ ) = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ l(y, \hat{y})=\frac{1}{n}\sum_{i=1}^{n}|y_i-\hat{y}_i| \tag{3} l(y,y^)=n1i=1∑n∣yi−y^i∣(3)
- R Squared
(4) R 2 = 1 − ( ∑ i = 1 n ( y i − y ^ i ) 2 ) / n ( ∑ i = 1 n ( y i − y ˉ i ) 2 ) / n R^2=1-\frac{(\sum_{i=1}^{n}(y_i-\hat{y}i)^2)/n}{(\sum{i=1}^{n}(y_i-\bar{y}_i)^2)/n} \tag{4} R2=1−(∑i=1n(yi−yˉi)2)/n(∑i=1n(yi−y^i)2)/n(4)
其中: y ^ \hat{y} y^是预测值, y y y是真实值, n n n是样本个数, y ˉ \bar{y} yˉ是 y y y的平均值.
分类(Classification)
- 准确率和错误率
(5) a c c ( y , y ^ ) = 1 n ∑ i = 1 n y i = y i ^ acc(y,\hat{y})=\frac{1}{n}\sum_{i=1}^{n}y_i=\hat{y_i} \tag{5} acc(y,y^)=n1i=1∑nyi=yi^(5)
(6) e r r o r ( y , y ^ ) = 1 − a c c ( y , y ^ ) error(y, \hat{y})=1-acc(y,\hat{y}) \tag{6} error(y,y^)=1−acc(y,y^)(6)
- 混淆矩阵,精准率和召回率
对于二分类问题,可将样例根据其真是类别与学习器预测类别的组合划分为真正例(true positive, TP),假正例(false positive, FP),真反例(ture negative, TN),假反例(false negative, FN), 则有:TP+FP+TN+FN=样例总数. 分类结果的混淆矩阵(confusion matrix)如下:
则有精准率P和召回率R定义如下: (7) P = T P T P + F P P=\frac{TP}{TP+FP} \tag{7} P=TP+FPTP(7)
(8) R = T P T P + F N R=\frac{TP}{TP+FN} \tag{8} R=TP+FNTP(8)
则F1值定义如下: (9) 1 F 1 = 1 2 ⋅ ( 1 P + 1 R ) \frac{1}{F_1}=\frac{1}{2} \cdot (\frac{1}{P}+\frac{1}{R}) \tag{9} F11=21⋅(P1+R1)(9)
(10) F 1 = 2 P R P + R F_1=\frac{2PR}{P+R} \tag{10} F1=P+R2PR(10)

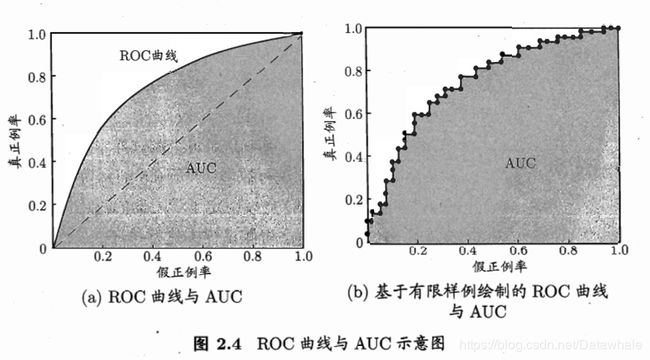
- ROC和AUC
ROC全称是"受试者工作特征"(Receiver Operating Characteristic)曲线. 根据学习器的预测结果堆样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算出两个重要的值,分别以他们作为横纵坐标作图,就得到"ROC曲线". 其中ROC曲线的横轴是"假正例率"(False Positive Rate, FPR), 纵轴是"真正例率"(True Positive Rate, TPR), 注意这里不是上文提高的P和R. 其中:
(11) T P R = T P T P + F N TPR=\frac{TP}{TP+FN} \tag{11} TPR=TP+FNTP(11) (12) F P R = F P T N + F P FPR=\frac{FP}{TN+FP} \tag{12} FPR=TN+FPFP(12)
现实使用中,一般使用有限个测试样例绘制ROC曲线,此时需要有有限个(真正例率,假正例率)坐标对. 绘图过程如下:
- 给定 m + m^+ m+个正例和 m − m^- m−个反例,根据学习器预测结果对样例进行排序,然后将分类阈值设为最大,此时真正例率和假正例率都为0,坐标在(0,0)处,标记一个点.
- 将分类阈值依次设为每个样本的预测值,即依次将每个样本划分为正例.
- 假设前一个坐标点是(x,y),若当前为真正例,则对应坐标为 ( x , y + 1 m + ) (x,y+\frac{1}{m^+}) (x,y+m+1), 若是假正例,则对应坐标为 ( x + 1 m − , y ) (x+\frac{1}{m^-}, y) (x+m−1,y)
线段连接相邻的点.理想的图和现实的图对比如下图(其中对角线对应于"随机猜测"模型):
为了进行比较,较为合理的判别依据是ROC曲线下面的面积,即AUC(Area Under ROC Curve). 从上图看出,AUC可估算为:
(13) A U C = 1 2 ∑ i = 1 m − 1 ( x i + 1 − x i ) ⋅ ( y i + y i + 1 ) AUC=\frac{1}{2}\sum_{i=1}^{m-1}(x_{i+1}-x_i)\cdot(y_i+y_{i+1}) \tag{13} AUC=21i=1∑m−1(xi+1−xi)⋅(yi+yi+1)(13)
AUC考虑是样本排序的质量,因此它和排序误差有紧密联系.给定 m + m^+ m+个正例和 m − m^- m−个负例,另 D + D^+ D+和 D − D^- D−分别表示正和反例的集合,则排序损失定义为: (14) l r a n k = 1 m + m − ∑ x + ∈ D + ∑ x − ∈ D − ( I ( f ( x + ) < f ( x − ) ) + 1 2 I ( f ( x + ) = f ( x − ) ) ) l_{rank}=\frac{1}{m^+m^-}\sum_{x^+ \in D^+}\sum_{x^- \in D^-}(I(f(x^+)<f(x^-))+\frac{1}{2}I(f(x^+)=f(x^-))) \tag{14} lrank=m+m−1x+∈D+∑x−∈D−∑(I(f(x+)<f(x−))+21I(f(x+)=f(x−)))(14)
即考虑每一对正反例,若正例的预测值小于反例,则记一个"罚分", 若相等,则记0.5个"罚分". 其实 l r a n k l_{rank} lrank对应的是ROC曲线之上的面积,则有:
(15) A U C = 1 − l r a n k AUC=1-l_{rank} \tag{15} AUC=1−lrank(15)
- CTR和CVR
- CTR
CTR(Click-Through-Rate)即点击通过率,是互联网广告常用的术语,指网络广告(图片广告/文字广告/关键词广告/排名广告/视频广告等)的点击到达率,即该广告的实际点击次数(严格的来说,可以是到达目标页面的数量)除以广告的展现量(Show content). (16) c t r = 点 击 次 数 展 示 量 ctr=\frac{点击次数}{展示量} \tag{16} ctr=展示量点击次数 (16)- CVR
CVR (Conversion Rate): 转化率。是一个衡量CPA广告效果的指标,简言之就是用户点击广告到成为一个有效激活或者注册甚至付费用户的转化率. (17) c v r = 点 击 量 转 化 量 cvr=\frac{点击量}{转化量} \tag{17} cvr=转化量点击量 (17)
参考
- 周志华 西瓜书
- 李航 统计学习方法
- https://baike.baidu.com/item/CVR/20215345
- https://baike.baidu.com/item/CTR/10653699?fr=aladdin
- https://www.cnblogs.com/shenxiaolin/p/9309749.html