1. 摘要
Kaggle是一个数据分析建模的应用竞赛平台,有点类似KDD-CUP(国际知识发现和数据挖掘竞赛),企业或者研究者可以将问题背景、数据、期望指标等发布到Kaggle上,以竞赛的形式向广大的数据科学家征集解决方案。
泰坦尼克号的沉没是历史上最臭名昭著的海难之一。
1912年4月15日,在她的处女航中,泰坦尼克号与冰山相撞后沉没,2224名乘客和船员中有1502人遇难。
这一耸人听闻的悲剧震惊了国际社会,并为船只带来了更好的安全监管。
造成这样的损失的原因之一是没有足够的救生艇给乘客和船员。
尽管在沉船事故中幸存下来的运气有一些因素,但一些群体比其他群体更有可能存活下来,比如妇女、儿童和上层社会。
在这个挑战中,要求完成对可能存活下来的人的分析。
特别地,要求应用机器学习的工具来预测哪些乘客在这场悲剧中幸存了下来。
Titanic生存预测是Kaggle上参赛人数最多的竞赛之一。它要求参赛选手通过训练数据集分析出什么类型的人更可能幸存,并预测出测试数据集中的所有乘客是否生还。
2. 数据来源及说明
2.1 数据来源
数据来自kaggle竞赛中Titanic数据集:Titanic: Machine Learning from Disaster
2.2 数据说明
下载数据集中的test.csv和train.csv两个文件,其中,train.csv用于数据的分析和建模,包含乘客的生存信息;test.csv用于预测模型并生成结果文件。
2.3 实践技能
二分类问题—— logistic regression
pandas, numpy数据处理
matplotlib 可视化
3.分析目的和思路
本文主要根据train数据的分析并建立模型,预测test数据中乘客在沉船事件中的生存情况。思路主要分为以下几个过程:
(1)读入train和test数据;(2)查看缺失值并对缺失值进行处理;(3)不同变量跟生存情况的关系分析;(4)建立模型并预测;(5)提交预测结果,查看网站排名。
4.初探数据
4.1 导入数据
import pandas as pd #数据分析
import numpy as np #科学计算
from pandas import Series,DataFrame
data_train = pd.read_csv("train.csv") #把csv文件读入成dataframe格式
data_train

4.2 查看数据集信息

它告诉我们,训练数据中总共有891名乘客,但是很不幸,我们有些属性的数据不全,比如说:
Age(年龄)属性只有714名乘客有记录
Cabin(客舱)更是只有204名乘客是已知的
5.初步数据分析
仅仅最上面的对数据了解,依旧无法给我们提供想法和思路。我们再深入一点来看看我们的数据,看看每个/多个 属性和最后的Survived之间有着什么样的关系呢?
5.1 乘客各属性分布
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(12,12)) #figsize用于控制图片的大小
fig.set(alpha=0.2)
plt.subplot2grid((2,3),(0,0))
data_train.Survived.value_counts().plot(kind='bar') #柱状图
plt.title(u"获救情况(1为获救)") #标题
plt.ylabel(u"人数")
plt.subplot2grid((2,3),(0,1))
data_train.Pclass.value_counts().plot(kind='bar')
plt.title(u"人数")
plt.ylabel(u"乘客等级分布")
plt.subplot2grid((2,3),(0,2))
plt.scatter(data_train.Survived, data_train.Age)
plt.ylabel(u"年龄") #set the y axis label
plt.grid(b=True, which='major', axis='y') #format the grid line style of our graphs
plt.title(u"按年龄看获救分布(1为获救)")
plt.subplot2grid((2,3),(1,0), colspan=2)
data_train.Age[data_train.Pclass == 1].plot(kind='kde')
data_train.Age[data_train.Pclass == 2].plot(kind='kde')
data_train.Age[data_train.Pclass == 3].plot(kind='kde')
plt.xlabel(u"年龄")
plt.ylabel(u"密度")
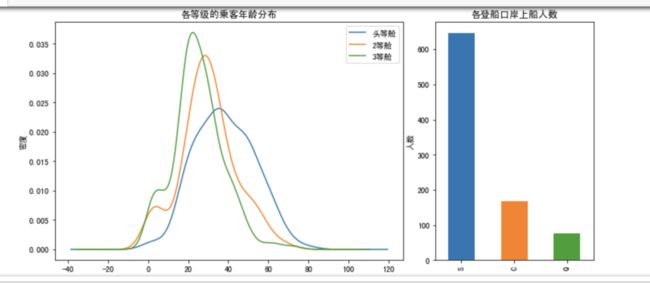
plt.title(u"各等级的乘客年龄分布")
plt.legend((u'头等舱',u'2等舱',u'3等舱'), loc='best')
plt.subplot2grid((2,3),(1,2))
data_train.Embarked.value_counts().plot(kind='bar')
plt.title(u"各登船口岸上船人数")
plt.ylabel(u"人数")
plt.show()

5.2 属性与获救结果的关联统计
# 看看各乘客等级的获救情况
fig = plt.figure(figsize=(12,12))
fig.set(alpha=0.2)
Survived_0 = data_train.Pclass[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Pclass[data_train.Survived == 1].value_counts()
df = pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True)
plt.title(u"各乘客等级的获救情况")
plt.xlabel(u"乘客等级")
plt.ylabel(u"人数")
plt.show()

# 看看各性别的获救情况
fig = plt.figure()
fig.set(alpha=0.2)
Survived_m = data_train.Survived[data_train.Sex == 'male'].value_counts()
Survived_f = data_train.Survived[data_train.Sex == 'female'].value_counts()
df = pd.DataFrame({u'男性':Survived_m, u'女性':Survived_f})
df.plot(kind='bar', stacked=True)
plt.title(u"按性别获救情况")
plt.xlabel(u"性别")
plt.ylabel(u"人数")
plt.show()

# 再来看看各种舱级别情况下各性别的获救情况
fig = plt.figure(figsize=(15,5))
fig.set(alpha=0.65) #设置图像透明度
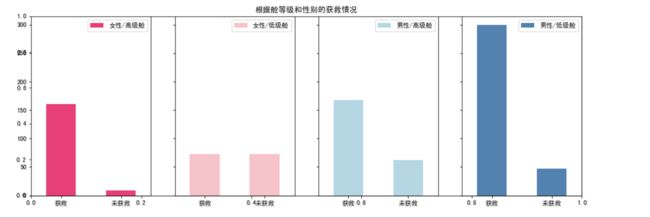
plt.title(u"根据舱等级和性别的获救情况")
ax1 = fig.add_subplot(141)
data_train.Survived[data_train.Sex == 'female'][data_train.Pclass != 3].value_counts().plot(kind='bar', label="female highclass", color='#FA2479')
ax1.set_xticklabels([u"获救", u"未获救"], rotation=0)
ax1.legend([u"女性/高级舱"], loc='best')
ax2 = fig.add_subplot(142, sharey=ax1)
data_train.Survived[data_train.Sex == 'female'][data_train.Pclass == 3].value_counts().plot(kind='bar', label="female lowclass", color='pink')
ax2.set_xticklabels([u"获救", u"未获救"], rotation=0)
plt.legend([u"女性/低级舱"], loc='best')
ax3 = fig.add_subplot(143, sharey=ax1)
data_train.Survived[data_train.Sex == 'male'][data_train.Pclass != 3].value_counts().plot(kind='bar', label="male highclass", color='lightblue')
ax3.set_xticklabels([u"获救", u"未获救"], rotation=0)
plt.legend([u"男性/高级舱"], loc='best')
ax4 = fig.add_subplot(144, sharey=ax1)
data_train.Survived[data_train.Sex == 'male'][data_train.Pclass == 3].value_counts().plot(kind='bar', label="male lowclass", color='steelblue')
ax4.set_xticklabels([u"获救", u"未获救"], rotation=0)
plt.legend([u"男性/低级舱"], loc='best')
plt.show()
# 各登船港口的获救情况
fig = plt.figure()
fig.set(alpha=0.2)
Survived_0 = data_train.Embarked[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Embarked[data_train.Survived == 1].value_counts()
df = pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True)
plt.title(u"各登陆港口的获救情况")
plt.xlabel(u"登陆港口")
plt.ylabel(u"人数")
plt.show()

cabin的值计数太分散了,绝大多数Cabin值只出现一次。感觉上作为类目,加入特征未必会有效
那我们一起看看这个值的有无,对于survival的分布状况,影响如何吧
fig = plt.figure()
fig.set(alpha=0.2)
Survived_cabin = data_train.Survived[pd.notnull(data_train.Cabin)].value_counts()
Survived_nocabin = data_train.Survived[pd.isnull(data_train.Cabin)].value_counts()
df=pd.DataFrame({u'有':Survived_cabin, u'无':Survived_nocabin}).transpose()
df.plot(kind='bar', stacked=True)
plt.title(u"按Cabin有无看获救情况")
plt.xlabel(u"Cabin有无")
plt.ylabel(u"人数")
plt.show()

6.简单数据预处理
大体数据的情况看了一遍,对感兴趣的属性也有个大概的了解了。
下一步该处理这些数据,为机器学习建模做准备。
这里的数据预处理,其实就包括feature engineering过程
先从最突出的数据属性开始,Cabin和Age有丢失数据对下一步工作影响太大。
先说Cabin,暂时我们就按照刚才说的,按Cabin有无数据,将这个属性处理成Yes和No两种类型吧。
再说Age:
通常遇到缺值的情况,我们会有几种常见的处理方式:
- 如果缺值的样本占总数比例极高,我们可能就直接舍弃了,作为特征加入的话,可能反倒带入noise,影响最后的结果了
- 如果缺值的样本适中,而该属性非连续值特征属性(比如说类目属性),那就把NaN作为一个新类别,加到类别特征中
- 如果缺值的样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个step(比如这里的age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中。
- 有些情况下,缺失的值个数并不是特别多,那我们也可以试着根据已有的值,拟合一下数据,补充上。
本例中,后两种处理方式应该都是可行的,我们先试试拟合补全吧(虽然说没有特别多的背景可供我们拟合,这不一定是一个多么好的选择)
我们这里用scikit-learn中的RandomForest来拟合一下缺失的年龄数据(注:RandomForest是一个用在原始数据中做不同采样,建立多颗DecisionTree,再进行average等等来降低过拟合现象,提高结果的机器学习算法)
from sklearn.ensemble import RandomForestRegressor
# 使用RandomForestClassifier 填补缺失的年龄属性
def set_missing_ages(df):
# 把已有的数值型特征取出来丢进Random Forest Regressor 中
age_df = df[['Age', 'Fare', 'Parch', 'SibSp', 'Pclass']]
# 乘客分成已知年龄和未知年龄两部分
known_age = age_df[age_df.Age.notnull()].values
unknown_age = age_df[age_df.Age.isnull()].values
# y 为目标年龄
y = known_age[:, 0]
# X 为 特征属性值
X = known_age[:, 1:]
# fit到RandomForestRegressor 中
rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
rfr.fit(X, y)
# 用得到的模型进行未知年龄结果预测
predictedAges = rfr.predict(unknown_age[:, 1::])
#用得到的预测结果填补原缺失数据
df.loc[(df.Age.isnull()), 'Age'] = predictedAges
return df, rfr
def set_Cabin_type(df):
df.loc[(df.Cabin.notnull()),'Cabin'] = "Yes"
df.loc[(df.Cabin.isnull()), 'Cabin'] = "No"
return df
data_train, rfr = set_missing_ages(data_train)
data_train = set_Cabin_type(data_train)
data_train

因为逻辑回归建模时,需要输入的特征都是数值型特征,我们通常会先对类目型的特征因子化。
以Cabin为例,原本一个属性维度,因为其取值可以是[‘yes’,’no’],而将其平展开为’Cabin_yes’,’Cabin_no’两个属性:
- 原本Cabin取值为yes的,在此处的”Cabin_yes”下取值为1,在”Cabin_no”下取值为0
- 原本Cabin取值为no的,在此处的”Cabin_yes”下取值为0,在”Cabin_no”下取值为1
我们使用pandas的”get_dummies”来完成这个工作,并拼接在原来的”data_train”之上,如下所示:
dummies_Cabin = pd.get_dummies(data_train['Cabin'], prefix='Cabin')
dummies_Embarked = pd.get_dummies(data_train['Embarked'], prefix='Embarked')
dummies_Sex = pd.get_dummies(data_train['Sex'], prefix='Sex')
dummies_Pclass = pd.get_dummies(data_train['Pclass'], prefix='Pclass')
df = pd.concat([data_train, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
df

我们很成功地把这些类目属性全都转成0,1的数值属性了。
这样,看起来,是不是我们需要的属性值都有了,且它们都是数值型属性呢。
接下来我们要接着做一些数据预处理的工作,比如scaling,将一些变化幅度较大的特征化到[-1,1]之, 这样可以加速logistic regression的收敛。
import sklearn.preprocessing as preprocessing
scaler = preprocessing.StandardScaler()
age_scale_param = scaler.fit(df[['Age']]) # 要以二维数组传入
df['Age_scaled'] = scaler.fit_transform(df[['Age']], age_scale_param)
# 要以二维数组传入
fare_scale_param = scaler.fit(df[['Fare']]) # 要以二维数组传入
df['Fare_scaled'] = scaler.fit_transform(df[['Fare']], fare_scale_param)
# 要以二维数组传入
df

7.逻辑回归建模
我们把需要的feature字段取出来,转成numpy格式,使用scikit-learn中的LogisticRegression建模
from sklearn import linear_model
#用正则取出我们要的属性值
train_df = df.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
# train_np = train_df.as_matrix()
# FutureWarning: Method .as_matrix will be removed in a future version. Use .values instead.
train_np = train_df.values
# y即Survival结果
y = train_np[:, 0]
# x 即特征属性值
X = train_np[:, 1:]
#fit 到RandomForestRegressor之中
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
# penalty 惩罚项目 L1,L2
clf.fit(X, y)
clf #得到一个model

接下来对训练集和测试集做一样的操作
data_test = pd.read_csv("test.csv")
data_test.loc[(data_test.Fare.isnull()), 'Fare'] = 0
# 接着我们对test_data做和train_data中一致的特征变换
# 首先用同样的RandomForestRegressor模型填上丢失的年龄
# data_test.info()
tmp_df = data_test[['Age', 'Fare', 'Parch', 'SibSp', 'Pclass']]
null_age = tmp_df[data_test.Age.isnull()].values
#根据特征属性X预测年龄并补上
X = null_age[:, 1:]
predictedAges = rfr.predict(X)
data_test.loc[(data_test.Age.isnull()), 'Age'] = predictedAges
data_test = set_Cabin_type(data_test)
dummies_Cabin = pd.get_dummies(data_test['Cabin'], prefix='Cabin')
dummies_Embarked = pd.get_dummies(data_test['Embarked'], prefix='Embarked')
dummies_Sex = pd.get_dummies(data_test['Sex'], prefix='Sex')
dummies_Pclass = pd.get_dummies(data_test['Pclass'], prefix='Pclass')
df_test = pd.concat([data_test, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df_test.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
df_test['Age_scaled'] = scaler.fit_transform(df_test[['Age']], age_scale_param)
df_test['Fare_scaled'] = scaler.fit_transform(df_test[['Fare']], fare_scale_param)
df_test

做预测取结果
test = df_test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
predictions = clf.predict(test)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].values, 'Survived':predictions.astype(np.int32)})
result.to_csv("logistic_regression_preditions.csv", index=False)
8.提交预测结果
pd.read_csv("logistic_regression_preditions.csv")

格式正确。

9. 总结
这只是简单分析处理过后出的一个baseline模型,还得优化。
这个baseline系统还有些粗糙,有待继续挖掘。
首先,Name和Ticket两个属性被我们完整舍弃了(好吧,其实是因为这俩属性,几乎每一条记录都是一个完全不同的值,我们并没有找到很直接的处理方式)。
然后,我们想想,年龄的拟合本身也未必是一件非常靠谱的事情,我们依据其余属性,其实并不能很好地拟合预测出未知的年龄。说不定我们把年龄离散化,按区段分作类别属性会更合适一些。