此作业的要求参见[https://edu.cnblogs.com/campus/nenu/2019fall/homework/6583]
git源码 https://e.coding.net/kangzhe/kangzheruanjiangongcheng.git
词频统计 SPEC 20180918
老五在寝室吹牛他熟读过《鲁滨逊漂流记》,在女生面前吹牛热爱《呼啸山庄》《简爱》和《飘》,在你面前说通读了《战争与和平》。但是,他的四级至今没过。你们几个私下商量,这几本大作的单词量怎么可能低于四级,大家听说你学习《构建之法》,一致推举你写个程序名字叫wf,统计英文作品的单词量并给出每个单词出现的次数,准备用于打脸老五。
希望实现以下效果。以下效果中数字纯属编造。
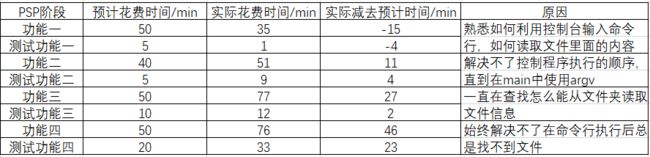
功能1 小文件输入。 为表明程序能跑,结果真实而不是迫害老五,请他亲自键
盘在控制台下输入命令。
>type test.txt
My English is very very pool.
>wf -s test.txt
total 5
very 2
my 1
english 1
is 1
pool 1
为了评估老五的词汇量而不是阅读量,total一项中相同的单词不重复计数数,出现2
次的very计数1次。
因为用过控制台和命令行,你早就知道,上面的">"叫做命令提示符,是操作系统的一部分,而不是你的程序的一部分。
此功能完成后你的经验值+10.
功能一部分代码如下:
def text_one(file_dir): total = 0 i = 0 patt = re.compile("\w+") #读取文件中的单词 counts = collections.Counter(patt.findall( open(file_dir, 'rt').read())) #计算相同单词的数量 for key, value in counts.most_common(): if counts[key] > 1: i = i + 1 file = open(file_dir, "r") for line in file.readlines(): #按空格切分 word = line.split(" ") total += len(word) #计算排除相同单词的单词数 print("total", total - i) print("\n") #输出键值对 for key, value in counts.most_common(): print(key, value)
运行效果如下:

难点:刚开始不太清楚如何出一个txt格式的文件中读取文件内容,之后再琢磨正则上花费了一点功夫,但是主要还是wf -s test.txt这个困扰我很久,偶然看到以前一个学长发的博客,重新再python环境中装了软件才得以解决。
功能2 支持命令行输入英文作品的文件名,请老五亲自录入。
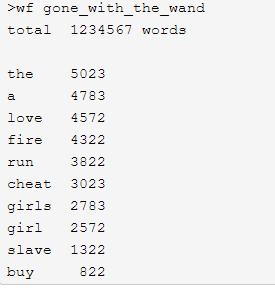
此功能完成后你的经验值+30. 输入文件最大不超过40MB. 如果你的程序中途崩
了,会被老五打脸,不增加经验值。
代码如下:
def text_two(file_dir_name): #拼接文件名 file_dir = file_dir_name + ".txt" total = 0 i = 0 patt = re.compile("\w+") counts = collections.Counter(patt.findall( open(file_dir, 'rt').read())) #统计相同单词数 for key, value in counts.most_common(): if counts[key] > 1: i = i + 1 file = open(file_dir, "r") #对内容进行正则化 word = re.findall(r'[a-z0-9^-]+', file.read().lower()) total = len(word) print("total", total - i,end="") print(" words") print("\n") for key, value in counts.most_common(10): print(key, value)
运行效果如下:
难点:要辨别什么时候执行第一个功能,什么时候执行第二个功能是我在编写程序时遇到的一个困难,后来在网上百度也无果的情况下,在询问以前学长才知道可以给主函数的argv传入参数控制功能的执行。
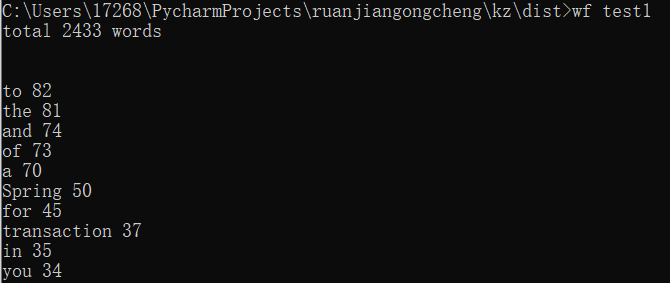
功能3 支持命令行输入存储有英文作品文件的目录名,批量统计。

因为单词量巨大,只列出出现次数最多的10个单词。
此功能完成后你的经验值+8.
代码如下:
def text_three(file_folder): #找到文件下的文档 file_names = os.listdir(file_folder) for file_name in file_names: print(file_name) #遍历每个文件,输出单词 for file_name in file_names: file_dir = "C:\\Users\\17268\\PycharmProjects\\ruanjiangongcheng\\kz\\dist\\folder\\" + file_name total = 0 i = 0 patt = re.compile("\w+") counts = collections.Counter(patt.findall( open(file_dir, 'rt').read())) for key, value in counts.most_common(): if counts[key] > 1: i = i + 1 file = open(file_dir, "r") for line in file.readlines(): word = line.split(" ") total += len(word) print(file_dir) print("total", total - i) for key, value in counts.most_common(10): print(key, value) print("----")
运行效果如下:

难点:第一个难点是如何从文件夹下遍历文本的名称,第二个难点是如何访问遍历出来的文本的内容,第三个难点是如何在控制台控制程序遍历列表。
功能4 从控制台读入英文单篇作品,这不是为了打脸老五,而是为了向你女朋
友炫酷,表明你能提供更适合嵌入脚本中的作品(或者如她所说,不过是更灵活
的接口)。如果读不懂需求,请教师兄师姐,或者 bing: linux 重定向,尽管
这个功能在windows下也有,搜索关键词中加入linux有利于迅速找到。
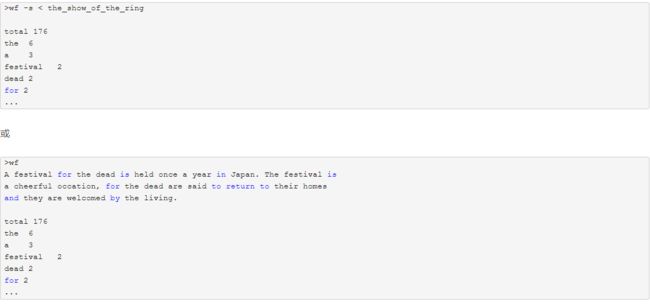
由于对python语言的类库还不是掌握的太明白,所以一些功能没有实现,只是写出了一些代码,代码如下:
def text_four(): str = input() file_dir = "C:\\Users\\17268\\PycharmProjects\\ruanjiangongcheng\\kz\\dist\\test4.txt" str = str.lower() with open(file_dir, "w", encoding='utf-8') as f: f.write(str) f.close() total = 0 i = 0 patt = re.compile("\w+") counts = collections.Counter(patt.findall( open(file_dir, 'rt').read())) for key, value in counts.most_common(): if counts[key] > 1: i = i + 1 file = open(file_dir, "r") for line in file.readlines(): word = line.split(" ") total += len(word) print("total", total - i) for key, value in counts.most_common(): print(key, value)
难点:功能四无法做到在程序中重定向,也不是太懂控制台输入的命令。
psp