Keras Fine Tuning(微调)(2)
目录
Keras Fine Tuning(微调)(1)
Keras Fine Tuning(微调)(2)
Keras Fine Tuning(微调)(3)
数据集下载:https://download.csdn.net/download/github_39611196/10940372
接上一篇博客: Keras Fine Tuning(微调)(1) ,本文主要介绍Keras中的fine tuning(微调),通过对西瓜、南瓜、番茄数据集进行分类来进行实例说明。
与上一篇博客冻结所有层不同,本片博客主要介绍对除最后四层外的VGG 16模型的网络层进行冻结,然后不做数据增强的数据集进行训练。
代码:
from keras.applications import VGG16
# 加载VGG模型
vgg_conv = VGG16(weights='imagenet', include_top=False, input_shape=(image_size, image_size, 3))
# 冻结除所有层
for layer in vgg_conv.layers[:-4]:
layer.trainable = False
# 检查每一层trainable属性的状态
for layer in vgg_conv.layers:
print(layer, layer.trainable)
from keras import models
from keras import layers
from keras import optimizers
# 创建模型
model = models.Sequential()
# 加入vgg的基础卷积网络
model.add(vgg_conv)
# 加入新的网络层
model.add(layers.Flatten())
model.add(layers.Dense(1024, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(3, activation='softmax')) # softmax 用于分类的激活函数
# 输出模型
model.summary()
# 训练模型
# 不做数据增强(Data Augmentation)
train_datagen = ImageDataGenerator(rescale=1./ 255)
validation_datagen = ImageDataGenerator(rescale=1./ 255)
# batch size
train_batchsize = 100
val_batch_size = 10
# 训练数据的数据生成器
train_generator = train_datagen.flow_from_directory(train_dir, target_size=(image_size, image_size), batch_size=train_batchsize, class_mode='categorical') # categorical用于分类的时候使用
# 测试数据的数据生成器
validation_generator = validation_datagen.flow_from_directory(validation_dir, target_size=(image_size, image_size), batch_size=val_batchsize, class_mode='categorical', shuffle=False)
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4), metrics=['acc'])
# 训练模型
history = model.fit_generator(train_generator, steps_per_epoch=train_generator.samples/ train_generator.batch_size, epochs=20, validation_data=validation_generator, validation_steps=validation_generator.samples/validation_generator.batch_size, verbose=1)
# 保存模型
model.save('last4_layers.h5')
# 显示正确率和损失曲线
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'b', label="Training acc")
plt.plot(epochs, val_acc, 'r', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'b', label='Training loss')
plt.plot(epochs, val_loss, 'r', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
# 显示错误分类的结果
validation_generator =validation_datagen.flow_from_directory(validation_dir, target_size=(image_size, image_size), batch_size=val_batchsize, class_mode='categorical', shuffle=False)
# 从生成器中获取文件名
fnames = validation_generator.filenames
# 从生成器中获取ground truth
ground_truth = validation_generator.classes
# 从生成器中获取类标签到类索引的映射
label2index = validation_generator.class_indices
# 从生成器中获取类索引到类标签的映射
idx2label = dict((v, k) for k, v in label2index.items())
# 通过生成器获取模型的预测值
predictions = model.predict_generator(validation_generator, steps=validation_generator.samples/ validation_generator.batch_size, verbose=1)
predicted_classes = np.argmax(predictions, axis=1)
errors =np.where(predicted_classes != ground_truth)[0]
print("No of errors = {}/{}".format(len(errors),validation_generator.samples))
# 显示分类错误的结果
for i in range(len(errors)):
pred_class = np.argmax(predictions[errors[i]])
pred_label = idx2label[pred_class]
title = 'Original label:{}, Prediction :{}, confidence : {:.3f}'.format(
fnames[errors[i]].split('/')[0],
pred_label,
predictions[errors[i]][pred_class])
original = load_img('{}/{}'.format(validation_dir,fnames[errors[i]]))
plt.figure(figsize=[7,7])
plt.axis('off')
plt.title(title)
plt.imshow(original)
plt.show()准确率:
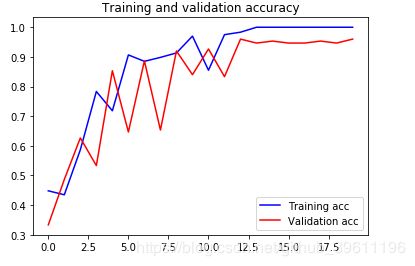
loss:
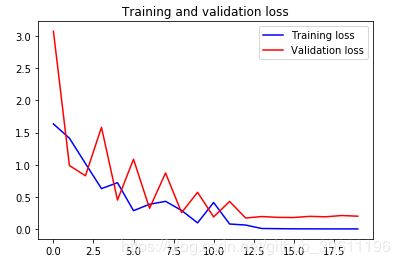
错误率:

分类错误的图片(部分):

