使用PyTorch实现CNN
使用PyTorch实现CNN
文章目录
- 使用PyTorch实现CNN
- 1. 导入所需包:
- 2. 获取数据集
- 2.1 获取数据集,并对数据集进行预处理
- 2.2 获取迭代数据:`data.DataLoader()`
- 3. 定义网络结构
- 4. 定义损失和优化器
- `model.parmaters()`含义:
- 5. 训练网络
- 损失图:
- 如果使用MSELoss:平方差损失
- 7. 测试网络:精确度:0.98
- 8. 其他实验:
- 8.1 全连接第一层增加ReLU激活函数:提高了0.02
- 8.2 去掉批量归一化:降低了0.01
- 8.3 使用LeakyReLU激活函数:降低0.01
- 8.4 使用PReLU激活函数:提升0.01
- 卷积方法的使用:`torch.nn.Conv2d()`
- 反卷积方法的使用:`torch.nn.ConvTranspose2d()`
1. 导入所需包:
import torch
from torch.utils import data # 获取迭代数据
from torch.autograd import Variable # 获取变量
import torchvision
from torchvision.datasets import mnist # 获取数据集
import matplotlib.pyplot as plt
2. 获取数据集
2.1 获取数据集,并对数据集进行预处理
(1)对原有数据转成Tensor类型
(2)用平均值和标准偏差归一化张量图像
# 数据集的预处理
data_tf = torchvision.transforms.Compose(
[
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.5],[0.5])
]
)
data_path = r'C:\Users\liev\Desktop\myproject\yin_test\MNIST_DATA_PyTorch'
# 获取数据集
train_data = mnist.MNIST(data_path,train=True,transform=data_tf,download=False)
test_data = mnist.MNIST(data_path,train=False,transform=data_tf,download=False)
第一次下载的输出:
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
Processing...
Done!
注意:
- 对数据的预处理还有很多。
- 第一次获取数据集时,参数download=True,会下载MNIST数据集所有文件,包括训练集和测试集
- 获取MNIST数据集的步骤:
-
如果本地没有数据集:
-
train_data = mnist.MNIST(data_path,train=True,transform=data_tf,download=True) -
等待下载,直到下载完成
-
train_data = mnist.MNIST(data_path,train=True,transform=data_tf,download=False) test_data = mnist.MNIST(data_path,train=False,transform=data_tf,download=False) -
获取测试集和训练集
-
-
如果本地有数据集
-
train_data = mnist.MNIST(data_path,train=True,transform=data_tf,download=False) test_data = mnist.MNIST(data_path,train=False,transform=data_tf,download=False)
-
2.2 获取迭代数据:data.DataLoader()
train_loader = data.DataLoader(train_data,batch_size=128,shuffle=True)
test_loader = data.DataLoader(test_data,batch_size=100,shuffle=True)
注意:
- DataLoader返回的是所有的数据,只是分成了每批次为参数batch_size的数据
- DataLoader的shuffle参数,True 决定了是否能多次取出batch_size,False,则表明只能取出数据集大小的数据。
3. 定义网络结构
| CNN网络结构 | 输入shape | 卷积核 | 激活函数 | 输出图像 |
|---|---|---|---|---|
| conv1 | [128,1,28,28] | [3,3,1,16] | ReLU | [128, 16, 14, 14] |
| conv2 | [128, 16, 14, 14] | [3,3,16,32] | ReLU | [128, 32, 7, 7] |
| conv3 | [128, 32, 7, 7] | [3,3,32,64] | ReLU | [128, 64, 4, 4] |
| conv4 | [128, 64, 4, 4] | [3,3,64,64] | ReLU | [128, 64, 2, 2] |
代码实现:
# 定义网络结构
class CNNnet(torch.nn.Module):
def __init__(self):
super(CNNnet,self).__init__()
self.conv1 = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=1,
out_channels=16,
kernel_size=3,
stride=2,
padding=1),
torch.nn.BatchNorm2d(16),
torch.nn.ReLU()
)
self.conv2 = torch.nn.Sequential(
torch.nn.Conv2d(16,32,3,2,1),
torch.nn.BatchNorm2d(32),
torch.nn.ReLU()
)
self.conv3 = torch.nn.Sequential(
torch.nn.Conv2d(32,64,3,2,1),
torch.nn.BatchNorm2d(64),
torch.nn.ReLU()
)
self.conv4 = torch.nn.Sequential(
torch.nn.Conv2d(64,64,2,2,0),
torch.nn.BatchNorm2d(64),
torch.nn.ReLU()
)
self.mlp1 = torch.nn.Linear(2*2*64,100)
self.mlp2 = torch.nn.Linear(100,10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.mlp1(x.view(x.size(0),-1))
x = self.mlp2(x)
return x
model = CNNnet()
print(model)
输出:
CNNnet(
(conv1): Sequential(
(0): Conv2d(1, 16, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv3): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv4): Sequential(
(0): Conv2d(64, 64, kernel_size=(2, 2), stride=(2, 2))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(mlp1): Linear(in_features=256, out_features=100, bias=True)
(mlp2): Linear(in_features=100, out_features=10, bias=True)
)
4. 定义损失和优化器
(1)使用交叉熵损失
(2)使用Adam优化器
loss_func = torch.nn.CrossEntropyLoss()
opt = torch.optim.Adam(model.parameters(),lr=0.001)
-
model.parmaters()含义: -
使用损失和优化器的步骤:
- 获取损失:
loss = loss_func(out,batch_y) - 清空上一步残余更新参数:
opt.zero_grad() - 误差反向传播:
loss.backward() - 将参数更新值施加到
net的parmeters上:opt.step()
- 获取损失:
5. 训练网络
loss_count = []
for epoch in range(2):
for i,(x,y) in enumerate(train_loader):
batch_x = Variable(x) # torch.Size([128, 1, 28, 28])
batch_y = Variable(y) # torch.Size([128])
# 获取最后输出
out = model(batch_x) # torch.Size([128,10])
# 获取损失
loss = loss_func(out,batch_y)
# 使用优化器优化损失
opt.zero_grad() # 清空上一步残余更新参数值
loss.backward() # 误差反向传播,计算参数更新值
opt.step() # 将参数更新值施加到net的parmeters上
if i%20 == 0:
loss_count.append(loss)
print('{}:\t'.format(i), loss.item())
torch.save(model,r'C:\Users\liev\Desktop\myproject\yin_test\log_CNN')
if i % 100 == 0:
for a,b in test_loader:
test_x = Variable(a)
test_y = Variable(b)
out = model(test_x)
# print('test_out:\t',torch.max(out,1)[1])
# print('test_y:\t',test_y)
accuracy = torch.max(out,1)[1].numpy() == test_y.numpy()
print('accuracy:\t',accuracy.mean())
break
plt.figure('PyTorch_CNN_Loss')
plt.plot(loss_count,label='Loss')
plt.legend()
plt.show()
输出:
0: 2.313704252243042
accuracy: 0.11
20: 1.1835652589797974
40: 0.5378416776657104
60: 0.41440480947494507
80: 0.18270650506019592
100: 0.18721994757652283
accuracy: 0.92
......
380: 0.032591354101896286
400: 0.024792633950710297
accuracy: 1.0
420: 0.03427279368042946
440: 0.04764523729681969
460: 0.01753203198313713
损失图:
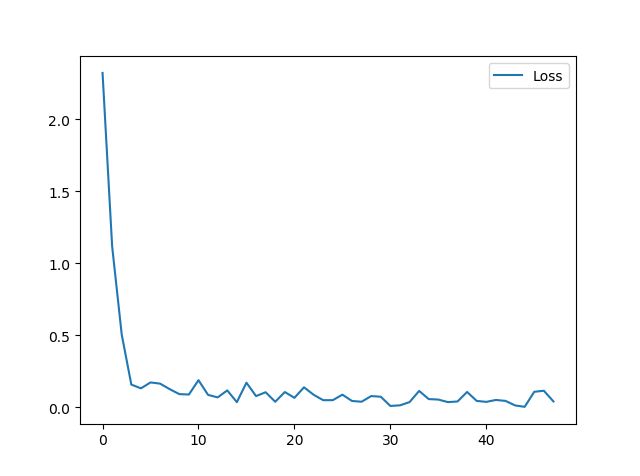
如果使用MSELoss:平方差损失
将真实值转为one-hot形式
def one_hot(data):
hot = np.zeros([10])
hot[data] = 1
return hot
# 并且在计算损失前,加入下面一行代码,将真实值转为one-hot形式
y = [one_hot(i) for i in y]
7. 测试网络:精确度:0.98
注意点:
- 获取accuracy时的问题:
- 获取的预测值shape:【128,10】
- 真实值shape:【128】,无one-hot编码
- 转换预测值:使用torch.max() 获取最后输出的每张图片预测值的最大值
# 测试网络
model = torch.load(r'C:\Users\liev\Desktop\myproject\yin_test\log_CNN')
accuracy_sum = []
for i,(test_x,test_y) in enumerate(test_loader):
test_x = Variable(test_x)
test_y = Variable(test_y)
out = model(test_x)
# print('test_out:\t',torch.max(out,1)[1])
# print('test_y:\t',test_y)
accuracy = torch.max(out,1)[1].numpy() == test_y.numpy()
accuracy_sum.append(accuracy.mean())
print('accuracy:\t',accuracy.mean())
print('总准确率:\t',sum(accuracy_sum)/len(accuracy_sum))
# 精确率图
print('总准确率:\t',sum(accuracy_sum)/len(accuracy_sum))
plt.figure('Accuracy')
plt.plot(accuracy_sum,'o',label='accuracy')
plt.title('Pytorch_CNN_Accuracy')
plt.legend()
plt.show()
输出:
accuracy: 0.98
accuracy: 1.0
accuracy: 1.0
accuracy: 1.
总准确率: 0.9850999999999999
8. 其他实验:
8.1 全连接第一层增加ReLU激活函数:提高了0.02
测试输出:
accuracy: 0.98
accuracy: 0.99
accuracy: 0.98
accuracy: 0.99
总准确率: 0.9872999999999992
8.2 去掉批量归一化:降低了0.01
accuracy: 0.97
accuracy: 0.97
accuracy: 0.92
总准确率: 0.9746999999999996
8.3 使用LeakyReLU激活函数:降低0.01
accuracy: 0.97
accuracy: 0.98
accuracy: 1.0
总准确率: 0.9848999999999997
8.4 使用PReLU激活函数:提升0.01
accuracy: 0.97
accuracy: 1.0
accuracy: 1.0
accuracy: 0.97
总准确率: 0.9867999999999998
卷积方法的使用:torch.nn.Conv2d()
在由多个输入平面组成的输入信号上应用2D卷积。
在最简单的情况下,具有输入大小的图层的输出值
( N , C i n , H , W ) ( N , C i n , H , W ) (N,C_{in},H,W)(N,Cin,H,W) (N,Cin,H,W)(N,Cin,H,W)
和输出
( N , C o u t , H o u t , W o u t ) ( N , C o u t , H o u t , W o u t ) (N,Cout,Hout,Wout)(N,Cout,Hout,Wout) (N,Cout,Hout,Wout)(N,Cout,Hout,Wout)
可以精确地描述为:
out ( N i , C o u t j ) = bias ( C o u t j ) + ∑ k = 0 C i n − 1 weight ( C o u t j , k ) ⋆ input ( N i , k ) \text{out}(N_i,C_{out_j})=\text{bias}(C_{out_j}) + \sum_{k = 0}^{C_{in}-1}\text{weight}(C_{out_j}, k) \star\text{input}(N_i, k) out(Ni,Coutj)=bias(Coutj)+k=0∑Cin−1weight(Coutj,k)⋆input(Ni,k)
⋆是有效的2D 互相关运算符, N 是一个批量大小, C 表示多个频道, H 是输入平面的高度,以像素为单位 W 是像素的宽度。
参数说明:
| 参数 | 说明 |
|---|---|
in_channels |
输入图像中的通道数:int |
out_channels |
卷积产生的通道数 |
| kernel_size | 卷积内核的大小 |
| stride | 卷积的步幅。默认值:1 |
| padding | 将零填充添加到输入的两侧。默认值:0 |
| dilation | 内核元素之间的间距。默认值:1 |
| groups | 从输入通道到输出通道的阻塞连接数。默认值:1 |
| bias | 如果True,在输出中增加了可学习的偏差。默认:True |
计算输出图片shape:
- 输入shape格式:
( N , C i n , H i n , W i n ) (N,C_{in},H_{in},W_{in}) (N,Cin,Hin,Win)
- 输出shape格式:
( N , C o u t , H o u t , W o u t ) (N,C_{out},H_{out},W_{out}) (N,Cout,Hout,Wout)
输出图片shape的计算公式:
H o u t = ⌊ H i n + 2 × p a d d i n g [ 0 ] − d i l a t i o n [ 0 ] × ( k e r n e l _ s i z e [ 0 ] − 1 ) − 1 s t r i d e [ 0 ] + 1 ⌋ W o u t = ⌊ W i n + 2 × p a d d i n g [ 1 ] − d i l a t i o n [ 1 ] × ( k e r n e l _ s i z e [ 1 ] − 1 ) − 1 s t r i d e [ 1 ] + 1 ⌋ H_{out} = \bigg\lfloor\frac{\mathbf{H}_{\mathbf{in}}+2\times \mathbf{padding[0]}-\mathbf{dilation[0]}\times (\mathbf{kernel}\_\mathbf{size[0]}-1)-1 }{\mathbf{stride[0]}}+1 \bigg\rfloor \\ W_{out} = \bigg\lfloor\frac{\mathbf{W}_{\mathbf{in}}+2\times \mathbf{padding[1]}-\mathbf{dilation[1]}\times (\mathbf{kernel}\_\mathbf{size[1]}-1)-1 }{\mathbf{stride[1]}}+1 \bigg\rfloor Hout=⌊stride[0]Hin+2×padding[0]−dilation[0]×(kernel_size[0]−1)−1+1⌋Wout=⌊stride[1]Win+2×padding[1]−dilation[1]×(kernel_size[1]−1)−1+1⌋
变量:
- weight(Tensor) - 形状模块的可学习权重(out_channels,in_channels,kernel_size [0],kernel_size [1])
- 偏见(Tensor) - 形状模块的可学习偏差(out_channels)
实例代码:
import torch
conv = torch.nn.Conv2d(1,3,2,1,0)
print('conv.weight.size():\t',conv.weight.size())
print('conv.bias.size():\t',conv.bias.size())
print('conv初始化的weight数据:\n',conv.weight)
print('conv初始化的bias数据:\n',conv.bias)
输出:
conv.weight.size(): torch.Size([3, 1, 2, 2])
conv.bias.size(): torch.Size([3])
conv初始化的weight数据:
Parameter containing:
tensor([[[[ 0.2753, -0.1573],
[-0.4197, 0.1795]]],
[[[ 0.1529, 0.3869],
[ 0.0219, -0.2829]]],
[[[ 0.3727, -0.1673],
[ 0.4687, 0.3792]]]], requires_grad=True)
conv初始化的bias数据:
Parameter containing:
tensor([ 0.2909, -0.0980, 0.0066], requires_grad=True)
反卷积方法的使用:torch.nn.ConvTranspose2d()
在由多个输入平面组成的输入图像上应用2D转置卷积运算符。
该模块可以看作Conv2d相对于其输入的梯度。它也被称为分数跨度卷积或反卷积(尽管它不是实际的去卷积操作)。
参数说明:
| 参数 | 说明 |
|---|---|
| in_channels | 输入图像中的通道数 |
| out_channels | 卷积产生的通道数 |
| kernel_size | 卷积内核的大小 |
| stride | 卷积的步幅。默认值:1 |
| padding | 零填充将添加到输入中每个维度的两侧。默认值:0kernel_size - 1 - padding |
| output_padding | 在输出形状中添加到每个维度的一侧的附加大小。默认值:0 |
| groups | 从输入通道到输出通道的阻塞连接数。默认值:1 |
| bias | 如果True,在输出中增加了可学习的偏差。默认:True |
| dilation | 内核元素之间的间距。默认值:1 |
计算输出图片shape:
- 输入:
( N , C i n , H i n , W i n ) (N,C_{in},H_{in},W_{in}) (N,Cin,Hin,Win)
- 输出:
( N , C o u t , H o u t , W o u t ) (N,C_{out},H_{out},W_{out}) (N,Cout,Hout,Wout)
输出图片shape的计算公式:
H o u t = ( H i n − 1 ) × s t r i d e [ 0 ] − 2 × p a d d i n g [ 0 ] + k e r n e l _ s i z e [ 0 ] + o u t p u t _ p a d d i n g [ 0 ] W o u t = ( W i n − 1 ) × s t r i d e [ 1 ] − 2 × p a d d i n g [ 1 ] + k e r n e l _ s i z e [ 1 ] + o u t p u t _ p a d d i n g [ 1 ] \mathbf{H_{out}} = \mathbf{(H_{in}-1)}\times \mathbf{stride[0]} - 2\times \mathbf{padding[0] }+\mathbf{kernel}\_\mathbf{size[0]}+\mathbf{output}\_\mathbf{padding[0]} \\ \mathbf{W_{out}} = \mathbf{(W_{in}-1)}\times \mathbf{stride[1]} - 2\times \mathbf{padding[1] }+\mathbf{kernel}\_\mathbf{size[1]}+\mathbf{output}\_\mathbf{padding[1]} Hout=(Hin−1)×stride[0]−2×padding[0]+kernel_size[0]+output_padding[0]Wout=(Win−1)×stride[1]−2×padding[1]+kernel_size[1]+output_padding[1]
变量:
- weight(Tensor) - 形状模块的可学习权重(out_channels,in_channels,kernel_size [0],kernel_size [1])
- 偏见(Tensor) - 形状模块的可学习偏差(out_channels)