神经网络之文本情感分析(一)
情感分析 Sentiment Analysis
- 本文主要是对优达学城 深度学习 第二部分卷积神经网络中Lesson2的一个总结,主要在代码层面
- 目标:利用BP神经网络判断一段影评是正面评价(Positive)还是负面评价(Negative)
- 代码以及Solution可以在 这里进行下载(运行在jupyter notebook)
Project 1
项目1并没有直接开始搭建网络,而是从直观上对我们的数据进行分析,并且掌握一些有用的库,具体包括
- 数据的读取
- Counter类的使用
- 将文本数字化,提出一种似乎可行的解决方案
读取数据
import numpy as np
import pandas as pdreviews = pd.read_csv('reviews.txt', header=None)
reviews.head()| 0 | |
|---|---|
| 0 | bromwell high is a cartoon comedy . it ran at … |
| 1 | story of a man who has unnatural feelings for … |
| 2 | homelessness or houselessness as george carli… |
| 3 | airport starts as a brand new luxury pla… |
| 4 | brilliant over acting by lesley ann warren . … |
labels = pd.read_csv('labels.txt', header=None)
labels.head()| 0 | |
|---|---|
| 0 | positive |
| 1 | negative |
| 2 | positive |
| 3 | negative |
| 4 | positive |
Counter 类的使用
- 统计词汇在所有影评中出现的次数,并且同时统计正向的和负向的
- Counter是一种用于统计个数的类,非常好用
- split(’ ‘)可以对一条影评以空格进行分割
from collections import Counterpositive_counts = Counter()
negative_counts = Counter()
total_counts = Counter()for review, label in zip(reviews.values, labels.values):
words = review[0].split(' ')
total_counts.update(words);
if label == 'positive':
positive_counts.update(words)
else:
negative_counts.update(words)len(total_counts)74074
positive_counts.most_common(20)[(”, 550468),
(‘the’, 173324),
(‘.’, 159654),
(‘and’, 89722),
(‘a’, 83688),
(‘of’, 76855),
(‘to’, 66746),
(‘is’, 57245),
(‘in’, 50215),
(‘br’, 49235),
(‘it’, 48025),
(‘i’, 40743),
(‘that’, 35630),
(‘this’, 35080),
(’s’, 33815),
(‘as’, 26308),
(‘with’, 23247),
(‘for’, 22416),
(‘was’, 21917),
(‘film’, 20937)]
negative_counts.most_common(20)[(”, 561462),
(‘.’, 167538),
(‘the’, 163389),
(‘a’, 79321),
(‘and’, 74385),
(‘of’, 69009),
(‘to’, 68974),
(‘br’, 52637),
(‘is’, 50083),
(‘it’, 48327),
(‘i’, 46880),
(‘in’, 43753),
(‘this’, 40920),
(‘that’, 37615),
(’s’, 31546),
(‘was’, 26291),
(‘movie’, 24965),
(‘for’, 21927),
(‘but’, 21781),
(‘with’, 20878)]
那么,我们如何让神经网络“认识”这些影评呢?
- 影评都是文字,神经网络无法对文本进行直接处理,因此我们需要数字化这些影评
- 这10w条影评,经过统计一共出现了74074个单词,74074并不大
- 我们可以想到一种“一个萝卜一个坑”的方法,具体是,输入层共74074个输入,也就是说每个单词都“占了一个坑”,输入值就是这个单词出现次数
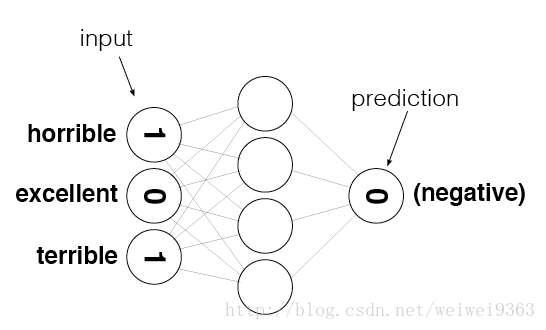
- 上图很好的解释了这种想法,假设我们有一条影评” It’s horrible and terrible”,那么horrible和terrible的位置上为1(当然,It’s的位置应该也是1,但是上图没有显示),其他都是0
- 基于上面的想法,我们需要对每个单词进行“指派门牌号”,让单词的位置进行固定,因此我们接下来进行word2index
- word2indx:给定一个单词,返回该单词在输入层上的位置
word2index = dict()for idx,word in enumerate(total_counts.keys()):
word2index[word] = idxword2index['apple']25600
End Project 1
- 我们将文本数字化,接下去我们将实现一个神经网络对我们的想法进行验证