【Keras-SqueezeNet】CIFAR-10(上)
系列连载目录
- 请查看博客 《Paper》 4.1 小节 【Keras】Classification in CIFAR-10 系列连载
学习借鉴
- github:BIGBALLON/cifar-10-cnn
- 知乎专栏:写给妹子的深度学习教程
- SqueezeNet Caffe 代码:https://github.com/DeepScale/SqueezeNet/blob/master/SqueezeNet_v1.0/train_val.prototxt
- SqueezeNet Keras 代码:https://github.com/rcmalli/keras-squeezenet/blob/master/keras_squeezenet/squeezenet.py
参考
- 【Keras-CNN】CIFAR-10
- 本地远程访问Ubuntu16.04.3服务器上的TensorBoard
- caffe代码可视化工具
硬件
- TITAN XP
文章目录
- 1 理论基础
- 2 SqueezeNet 代码实现
- 2.1 squeezenet
- 2.2 squeezenet_he_regular
- 2.3 squeezenet_he_regular_bn
- 2.4 squeezenet_he_regular_bn_no_conv10
- 2.5 squeezenet_he_regular_bn_dropout
- 2.6 squeezenet_del_slim
- 2.7 squeezenet_stride_slim
- 2.8 squeezenet_stride_slim_1
- 2.9 squeezenet_stride_slim_2
- 3 squeezenet with bypass connection
- 3.1 simple bypass connection
- 3.2 complex bypass connection
- 3 总结
1 理论基础
参考【MobileNet】《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
精度相当,参数量更少,计算量更少,速度更快
2 SqueezeNet 代码实现
2.1 squeezenet
figure 2 in the paper

1)导入库,设置好超参数
import os
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"]="0"
import keras
from keras.datasets import cifar10
from keras import backend as K
from keras.layers import Input, Conv2D, GlobalAveragePooling2D, Dense, BatchNormalization, Activation, MaxPooling2D
from keras.models import Model
from keras.layers import concatenate
from keras import optimizers,regularizers
from keras.preprocessing.image import ImageDataGenerator
from keras.initializers import he_normal
from keras.callbacks import LearningRateScheduler, TensorBoard, ModelCheckpoint
num_classes = 10
batch_size = 64 # 64 or 32 or other
epochs = 300
iterations = 782
DROPOUT=0.2 # keep 80%
CONCAT_AXIS=3
weight_decay=1e-4
DATA_FORMAT='channels_last' # Theano:'channels_first' Tensorflow:'channels_last'
log_filepath = './squeezenet'
2)数据预处理并设置 learning schedule
def color_preprocessing(x_train,x_test):
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
mean = [125.307, 122.95, 113.865]
std = [62.9932, 62.0887, 66.7048]
for i in range(3):
x_train[:,:,:,i] = (x_train[:,:,:,i] - mean[i]) / std[i]
x_test[:,:,:,i] = (x_test[:,:,:,i] - mean[i]) / std[i]
return x_train, x_test
def scheduler(epoch):
if epoch < 100:
return 0.01
if epoch < 200:
return 0.001
return 0.0001
# load data
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
x_train, x_test = color_preprocessing(x_train, x_test)
3)定义网络结构
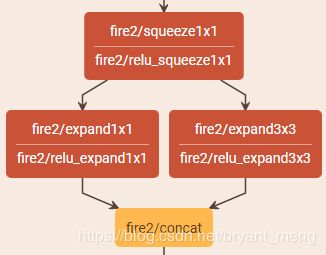
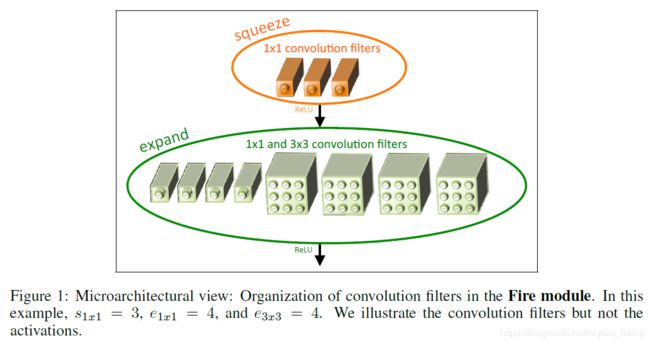
def fire_module(x,squeeze,expand,channel_axis):
x = Conv2D(squeeze,(1,1),padding='same')(x)# valid
x = Activation('relu')(x)
left = Conv2D(expand,(1,1),padding='same')(x)# valid
left = Activation('relu')(left)
right = Conv2D(expand,(3,3),padding='same')(x)
right = Activation('relu')(right)
x = concatenate([left, right],axis=channel_axis)
return x
4)搭建网络
用 3)中设计好的模块来搭建网络,整体 architecture 如下:

def squeezenet(img_input,classes=10):
x = Conv2D(96, (3, 3), strides=(2, 2), padding='same')(img_input)# valid
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2),padding='same',data_format=DATA_FORMAT)(x)
# fire 2,3,4
x = fire_module(x,squeeze=16,expand=64,channel_axis=CONCAT_AXIS)
x = fire_module(x,squeeze=16,expand=64,channel_axis=CONCAT_AXIS)
x = fire_module(x,squeeze=32,expand=128,channel_axis=CONCAT_AXIS)
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2),padding='same',data_format=DATA_FORMAT)(x)
# fire 5,6,7,8
x = fire_module(x,squeeze=32,expand=128,channel_axis=CONCAT_AXIS)
x = fire_module(x,squeeze=48,expand=192,channel_axis=CONCAT_AXIS)
x = fire_module(x,squeeze=48,expand=192,channel_axis=CONCAT_AXIS)
x = fire_module(x,squeeze=64,expand=256,channel_axis=CONCAT_AXIS)
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2),padding='same',data_format=DATA_FORMAT)(x)
# fire 9
x = fire_module(x,squeeze=64,expand=256,channel_axis=CONCAT_AXIS)
x = Conv2D(10, (1,1),strides=(1,1), padding='same')(x)
x = Activation('relu')(x)
x = GlobalAveragePooling2D()(x)
out = Dense(classes, activation='softmax')(x)
return out
5)生成模型
img_input=Input(shape=(32,32,3))
output = squeezenet(img_input)
model=Model(img_input,output)
model.summary()
参数量如下:
Total params: 729,144
Trainable params: 729,144
Non-trainable params: 0
6)开始训练
# set optimizer
sgd = optimizers.SGD(lr=.1, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
# set callback
tb_cb = TensorBoard(log_dir=log_filepath, histogram_freq=0)
change_lr = LearningRateScheduler(scheduler)
cbks = [change_lr,tb_cb]
# set data augmentation
datagen = ImageDataGenerator(horizontal_flip=True,
width_shift_range=0.125,
height_shift_range=0.125,
fill_mode='constant',cval=0.)
datagen.fit(x_train)
# start training
model.fit_generator(datagen.flow(x_train, y_train,batch_size=batch_size),
steps_per_epoch=iterations,
epochs=epochs,
callbacks=cbks,
validation_data=(x_test, y_test))
model.save('squeezenet.h5')
7)结果分析
training accuracy 和 training loss
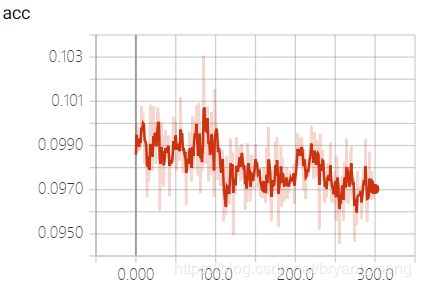
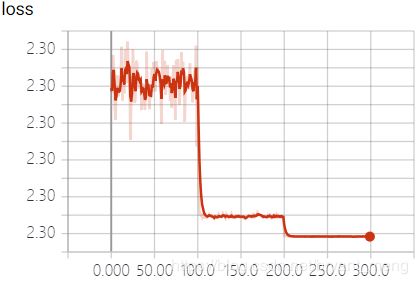
test accuracy 和 test loss
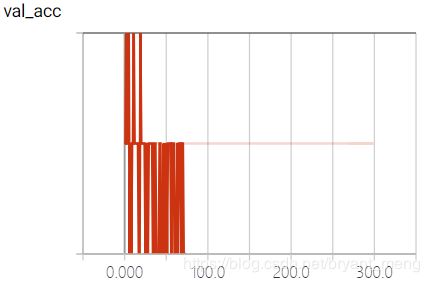
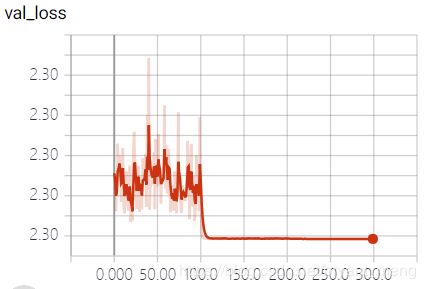
这种情况怎么分析呢?loss几乎没动,精度也在 1 / c l a s s e s 1/classes 1/classes 附近!代码实现?网络设计?网络参数的初始化?超参数?头大!
2.2 squeezenet_he_regular
改变网络初始化策略为 he_normal,加入 L2 regularization
对所有 Conv2D 进行如下修改,加入kernel_initializer="he_normal",kernel_regularizer=regularizers.l2(weight_decay)
x = Conv2D(64, (3, 3), strides=(2, 2), padding='same',
kernel_initializer="he_normal",kernel_regularizer=regularizers.l2(weight_decay))(img_input)
其它部分代码同 squeezenet
参数量如下(不变):
Total params: 729,144
Trainable params: 729,144
Non-trainable params: 0
- squeezenet
Total params: 729,144
结果分析如下:
training accuracy 和 training loss
![]()
![]()
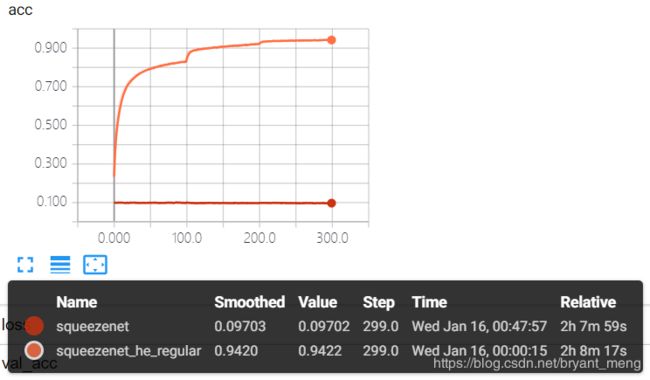
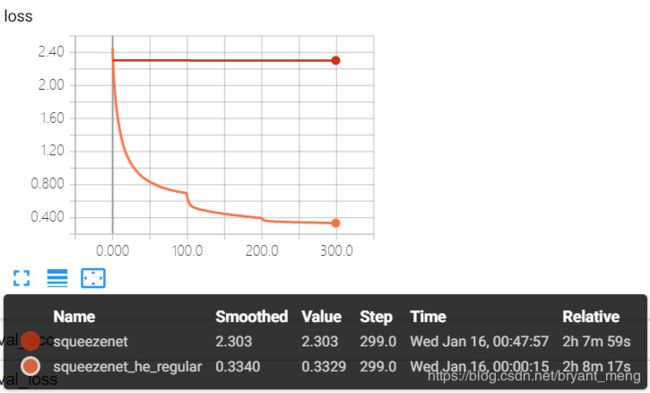
test accuracy 和 test loss
![]()
![]()
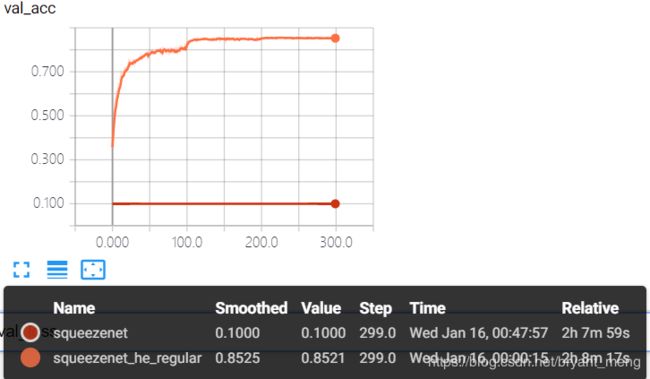
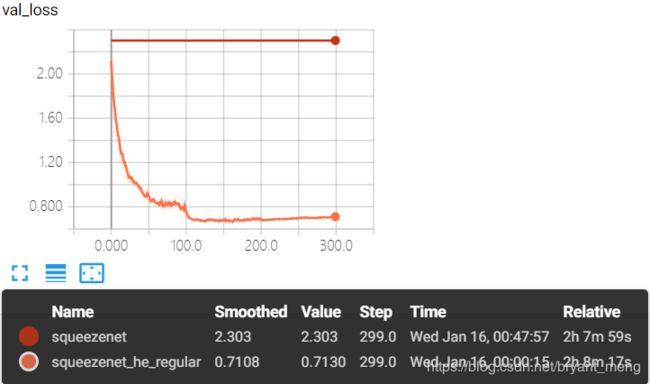
算是表现正常吧,精度有 85%+,有过拟合现象
2.3 squeezenet_he_regular_bn
在所有 Conv2D 与 Activation 之间加入 Batch Normalization 操作
x = Conv2D(64, (3, 3), strides=(2, 2), padding='same',
kernel_initializer="he_normal",kernel_regularizer=regularizers.l2(weight_decay))(img_input)# valid
x = BatchNormalization(momentum=0.9, epsilon=1e-5)(x)
x = Activation('relu')(x)
其它部分代码同:squeezenet_he_regular
参数量如下(增了一点点):
Total params: 741,088
Trainable params: 735,116
Non-trainable params: 5,972
- squeezenet
Total params: 729,144 - squeezenet_he_regular
Total params: 729,144
结果分析如下:
training accuracy 和 training loss
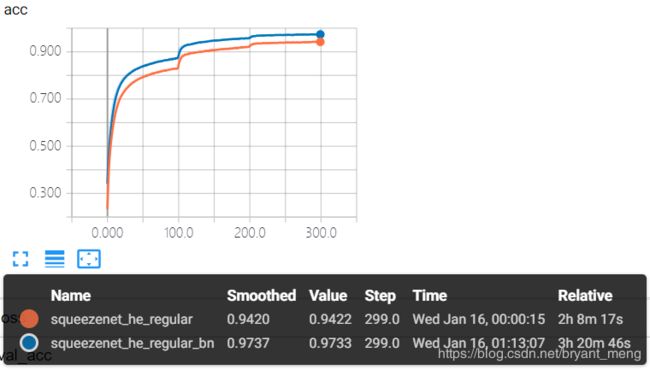
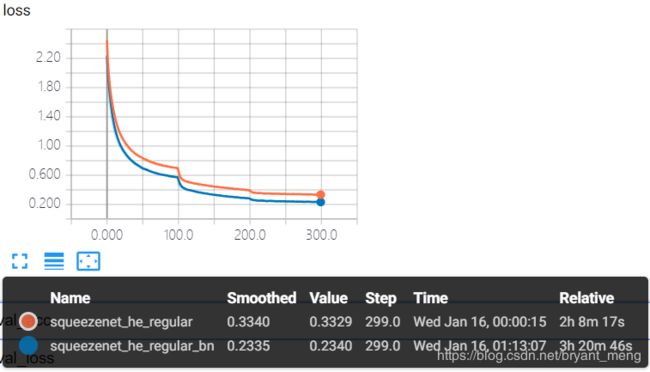
test accuracy 和 test loss
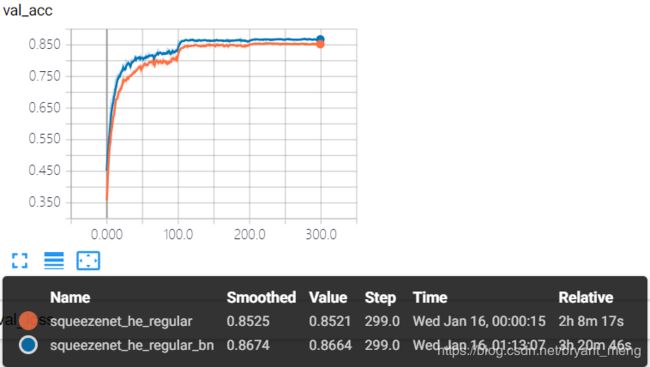
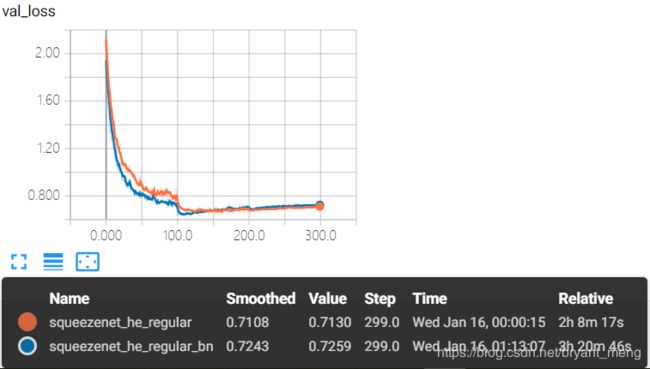
精度有提升 86%+,有过拟合现象,也正常,由 table1 可知,整个网络一共有4次 down sampling,分别在conv1,conv1 后,fire4后,fire8 后。最后一次 down sampling 之后,resolution 为 2*2,后续的 fire9 和 conv10 会受到 padding 的严重影响。
2.4 squeezenet_he_regular_bn_no_conv10
去掉 conv10,因为 cifar-10 类别少,所以 channels 从 512 一下子降到 10 有些突兀,可能会损失很多信息,不像 imagenet,从 512 到 1000。
其它部分代码同:squeezenet_he_regular_bn
参数量如下:
Total params: 740,938
Trainable params: 734,986
Non-trainable params: 5,952
- squeezenet
Total params: 729,144 - squeezenet_he_regular
Total params: 729,144 - squeezenet_he_regular_bn
Total params: 741,088
结果分析如下:
test accuracy 和 test loss
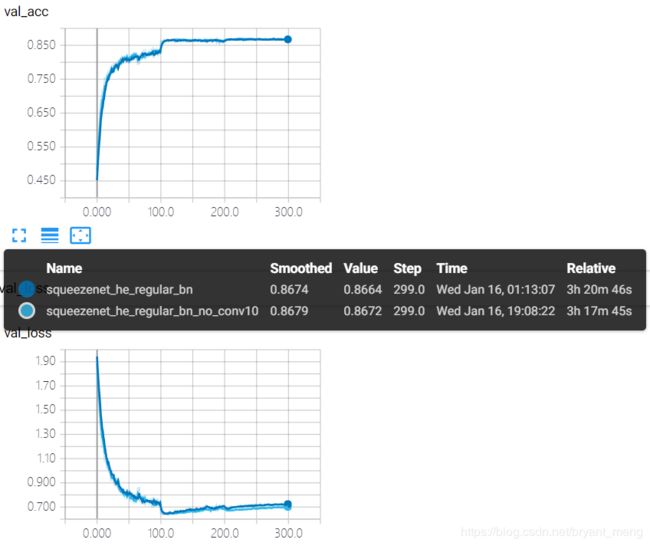
不相上下,过拟合现象还是没有缓解
2.5 squeezenet_he_regular_bn_dropout
在 2.3 小节 squeezenet_he_regular_bn 的基础上,fire module 9 之后,加一个 50% 的 dropout
from keras.layers import Dropout
DROPOUT = 0.5
在 def squeezenet(img_input,classes=10): 函数中,加一句
x=Dropout(DROPOUT)(x)
其它代码同 squeezenet_he_regular_bn
参数量如下(不变):
Total params: 741,088
Trainable params: 735,116
Non-trainable params: 5,972
- squeezenet
Total params: 729,144 - squeezenet_he_regular
Total params: 729,144 - squeezenet_he_regular_bn
Total params: 741,088 - squeezenet_he_regular_bn_no_conv10
Total params: 740,938
结果分析如下:
test accuracy 和 test loss
![]()
![]()
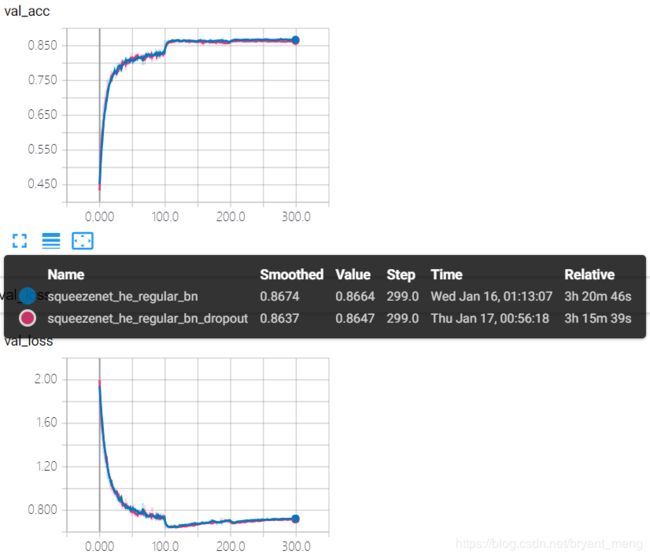
加了 dropout 之后效果好像还差一些,也没有缓解过拟合现象,感觉还是因为 resolution 降的太多。
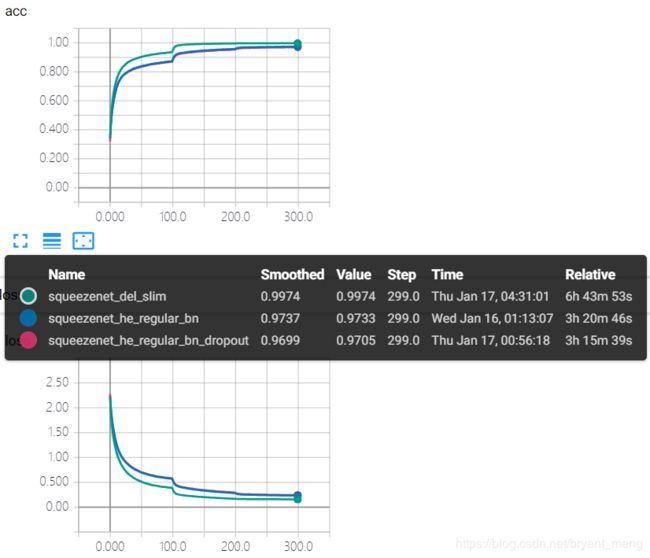
2.6 squeezenet_del_slim
在 2.5 小节的基础上,结合 table 1,将 conv1 的 stride 改为1,删掉 maxpooling1、maxpooling4,其它代码同squeezenet_he_regular_bn
参数量如下(不变):
Total params: 741,088
Trainable params: 735,116
Non-trainable params: 5,972
- squeezenet
Total params: 729,144 - squeezenet_he_regular
Total params: 729,144 - squeezenet_he_regular_bn
Total params: 741,088 - squeezenet_he_regular_bn_no_conv10
Total params: 740,938 - squeezenet_he_regular_bn_dropout
Total params: 741,088
结果分析如下:
training accuracy 和 training loss
![]()
![]()
![]()
test accuracy 和 test loss
![]()
![]()
![]()
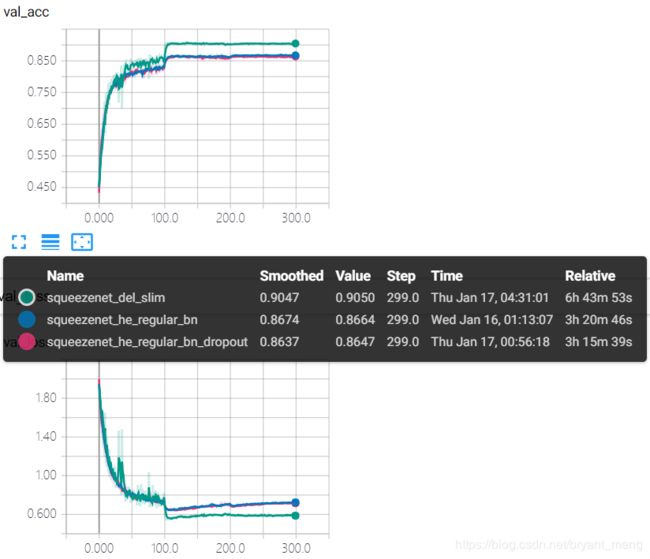
虽然 parameters 没有增加,但是因为删除了 max pooling,增大了 feature map 的 resolution,所以时间变慢了许多,前期波动较大,精度突破了 90%+。缓解了过拟合现象!
2.7 squeezenet_stride_slim
在 2.5 小节的基础上,结合 table 1,将 conv1 的 stride 改为1,将 maxpooling1、maxpooling4 的 stride 改为1,其它代码同squeezenet_he_regular_bn
参数量如下(不变):
Total params: 741,088
Trainable params: 735,116
Non-trainable params: 5,972
- squeezenet
Total params: 729,144 - squeezenet_he_regular
Total params: 729,144 - squeezenet_he_regular_bn
Total params: 741,088 - squeezenet_he_regular_bn_no_conv10
Total params: 740,938 - squeezenet_he_regular_bn_dropout
Total params: 741,088 - squeezenet_del_slim
Total params: 741,088
结果分析如下:
test accuracy 和 test loss

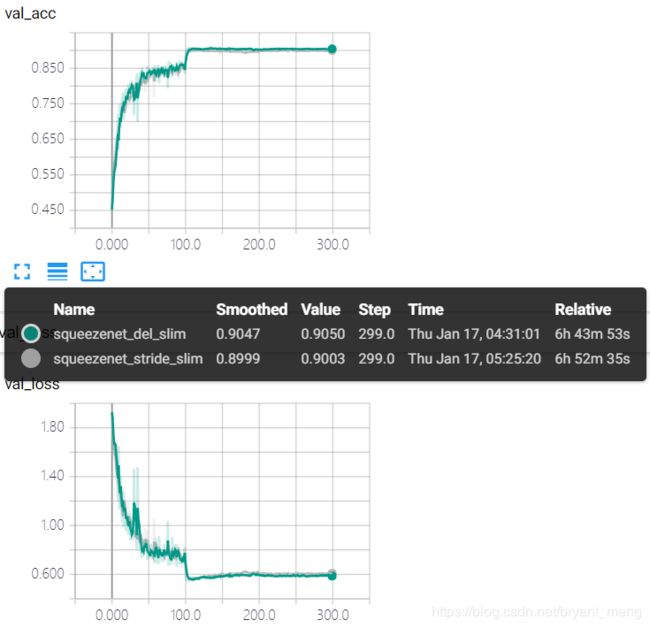
对比来看,在 SqueezeNet 上,删掉 max pooling 比将 max pooling 的 stride 改为 1 效果好
2.8 squeezenet_stride_slim_1
在 2.5 小节的基础上,结合 table 1,将 conv1 的 stride 改为1,将 maxpooling1 的 stride 改为1,其它代码同squeezenet_he_regular_bn
参数量如下(不变):
Total params: 741,088
Trainable params: 735,116
Non-trainable params: 5,972
- squeezenet
Total params: 729,144 - squeezenet_he_regular
Total params: 729,144 - squeezenet_he_regular_bn
Total params: 741,088 - squeezenet_he_regular_bn_no_conv10
Total params: 740,938 - squeezenet_he_regular_bn_dropout
Total params: 741,088 - squeezenet_del_slim
Total params: 741,088 - squeezenet_stride_slim
Total params: 741,088
结果分析如下:
test accuracy 和 test loss
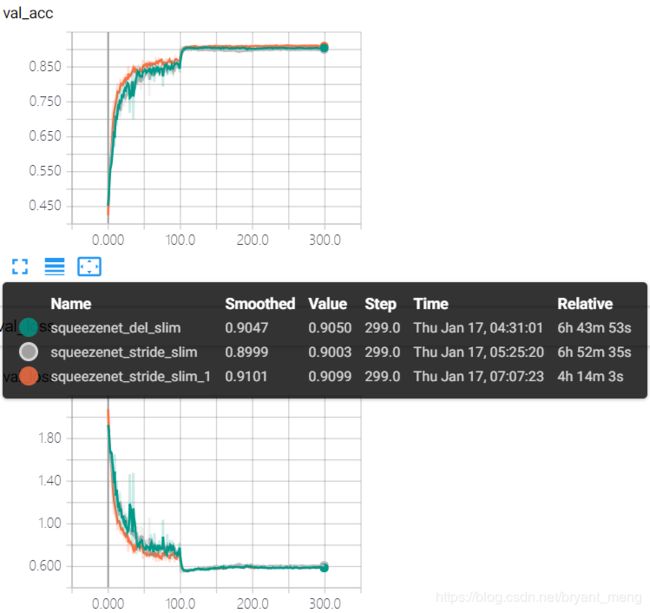
精度突破 91% 了
2.9 squeezenet_stride_slim_2
在 2.5 小节的基础上,结合 table 1,将 conv1 的 stride 改为1,将 maxpooling1 删掉,其它代码同squeezenet_he_regular_bn
参数量如下(不变):
Total params: 741,088
Trainable params: 735,116
Non-trainable params: 5,972
- squeezenet
Total params: 729,144 - squeezenet_he_regular
Total params: 729,144 - squeezenet_he_regular_bn
Total params: 741,088 - squeezenet_he_regular_bn_no_conv10
Total params: 740,938 - squeezenet_he_regular_bn_dropout
Total params: 741,088 - squeezenet_del_slim
Total params: 741,088 - squeezenet_stride_slim
Total params: 741,088 - squeezenet_stride_slim_1
Total params: 741,088
结果分析如下:
test accuracy 和 test loss
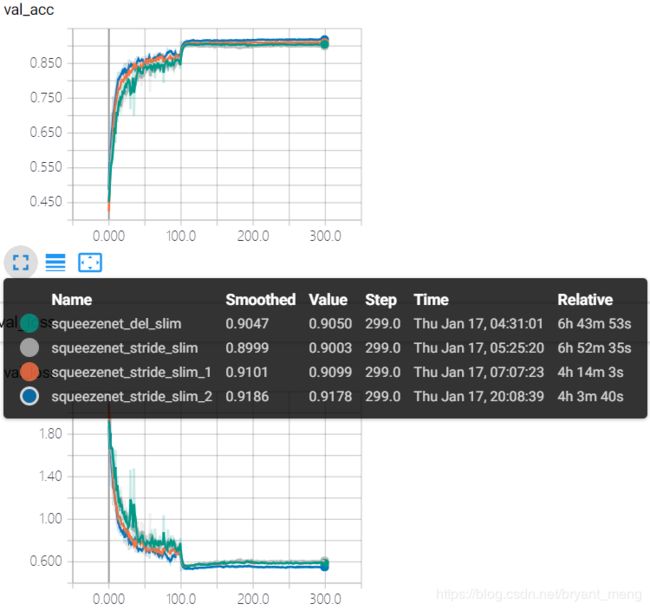

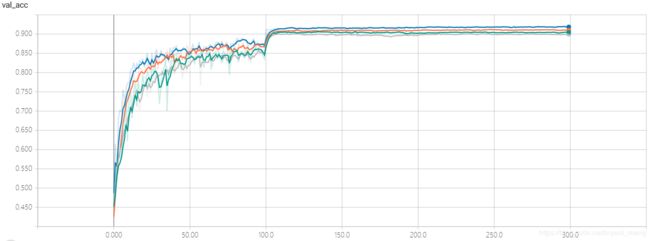
峰值差一点点到 92%,话说 max pooling 配合 stride =1 的效果还真不如不要 maxpooling,对比 squeezenet_stride_slim_1 和 squeezenet_stride_slim_2
3 squeezenet with bypass connection

上图左边是第二节的结构,中间是 3.1 simple bypass connection 的结构,右边是 3.2 complex bypass connection 的结构。
3.1 simple bypass connection
在 2.9 小节的基础上,在 fire 3、fire 5、fire 7、fire 9 中接入 simple bypass connection,代码修改如下:
- 修改 fire module 函数,新增
bypass形参,控制 simple bypass connection 结构
def fire_module(x,squeeze,expand,channel_axis,bypass=False):
s1 = Conv2D(squeeze,(1,1),padding='same',
kernel_initializer="he_normal",kernel_regularizer=regularizers.l2(weight_decay))(x)# valid
s1 = BatchNormalization(momentum=0.9, epsilon=1e-5)(s1)
s1 = Activation('relu')(s1)
e1 = Conv2D(expand,(1,1),padding='same',
kernel_initializer="he_normal",kernel_regularizer=regularizers.l2(weight_decay))(s1)# valid
e1 = BatchNormalization(momentum=0.9, epsilon=1e-5)(e1)
e1 = Activation('relu')(e1)
e3 = Conv2D(expand,(3,3),padding='same',
kernel_initializer="he_normal",kernel_regularizer=regularizers.l2(weight_decay))(s1)
e3 = BatchNormalization(momentum=0.9, epsilon=1e-5)(e3)
e3 = Activation('relu')(e3)
output = concatenate([e1,e3],axis=channel_axis)
if bypass:
output = add([output,x])
return output
- 修改
def squeezenet(img_input,classes=10):,在需要 simple bypass connection 的地方(fire 3、5、7、9)令bypass=True,例如
x = fire_module(x,squeeze=16,expand=64,channel_axis=CONCAT_AXIS,bypass=True)
其它代码同 squeezenet_stride_slim_2
参数量如下(不变):
Total params: 741,088
Trainable params: 735,116
Non-trainable params: 5,972
- squeezenet
Total params: 729,144 - squeezenet_he_regular
Total params: 729,144 - squeezenet_he_regular_bn
Total params: 741,088 - squeezenet_he_regular_bn_no_conv10
Total params: 740,938 - squeezenet_he_regular_bn_dropout
Total params: 741,088 - squeezenet_del_slim
Total params: 741,088 - squeezenet_stride_slim
Total params: 741,088 - squeezenet_stride_slim_1
Total params: 741,088 - squeezenet_stride_slim_2
Total params: 741,088
结果分析如下:
test accuracy 和 test loss
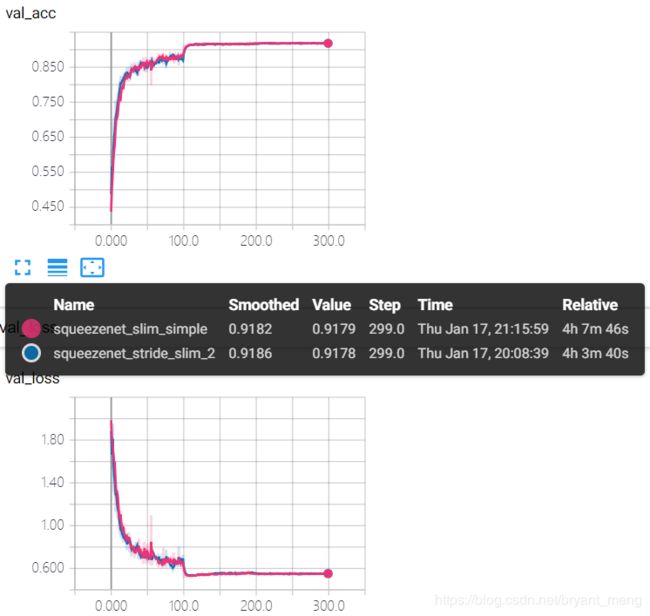
效果不是特别明显
3.2 complex bypass connection
在 2.9 小节的基础上,在 fire 3、fire 5、fire 7、fire 9 中接入 simple bypass connection,在 fire 2、fire 4、fire 6、fire 8 中接入 complex bypass connection,代码修改如下:
- 修改 fire module 函数,新增
bypass_simple和bypass_complex形参,控制 simple / complex bypass connection 结构,bypass_conv表示 bypass 中 1×1 卷积的 filters number
def fire_module(x,squeeze,expand,channel_axis,bypass_conv=0,bypass_simple=False,bypass_complex=False):
s1 = Conv2D(squeeze,(1,1),padding='same',
kernel_initializer="he_normal",kernel_regularizer=regularizers.l2(weight_decay))(x)# valid
s1 = BatchNormalization(momentum=0.9, epsilon=1e-5)(s1)
s1 = Activation('relu')(s1)
e1 = Conv2D(expand,(1,1),padding='same',
kernel_initializer="he_normal",kernel_regularizer=regularizers.l2(weight_decay))(s1)# valid
e1 = BatchNormalization(momentum=0.9, epsilon=1e-5)(e1)
e1 = Activation('relu')(e1)
e3 = Conv2D(expand,(3,3),padding='same',
kernel_initializer="he_normal",kernel_regularizer=regularizers.l2(weight_decay))(s1)
e3 = BatchNormalization(momentum=0.9, epsilon=1e-5)(e3)
e3 = Activation('relu')(e3)
output = concatenate([e1,e3],axis=channel_axis)
if bypass_simple:
output = add([output,x])
if bypass_complex:
x = Conv2D(bypass_conv,(1,1),padding='same',
kernel_initializer="he_normal",kernel_regularizer=regularizers.l2(weight_decay))(x)
x = BatchNormalization(momentum=0.9, epsilon=1e-5)(x)
x = Activation('relu')(x)
output = add([output,x])
return output
- 修改
def squeezenet(img_input,classes=10):,在需要 simple bypass connection 的地方(fire 3、5、7、9)令bypass_simple=True,在需要 complex bypass connection 的地方(fire 2、4、6、8)令bypass_complex=True,并设置bypass_conv的值例如
x = fire_module(x,squeeze=16,expand=64,channel_axis=CONCAT_AXIS,bypass_conv=128,bypass_complex=True)
x = fire_module(x,squeeze=16,expand=64,channel_axis=CONCAT_AXIS,bypass_simple=True)
参数量如下(增加了一点点):
Total params: 1,087,456
Trainable params: 1,078,924
Non-trainable params: 8,532
- squeezenet
Total params: 729,144 - squeezenet_he_regular
Total params: 729,144 - squeezenet_he_regular_bn
Total params: 741,088 - squeezenet_he_regular_bn_no_conv10
Total params: 740,938 - squeezenet_he_regular_bn_dropout
Total params: 741,088 - squeezenet_del_slim
Total params: 741,088 - squeezenet_stride_slim
Total params: 741,088 - squeezenet_stride_slim_1
Total params: 741,088 - squeezenet_stride_slim_2
Total params: 741,088 - simple bypass connection
Total params: 741,088
结果分析如下:
test accuracy 和 test loss



论文中的情况,哈哈!当然我们数据集不一样,网络也被我修改了,所以不能直接对比
3 总结
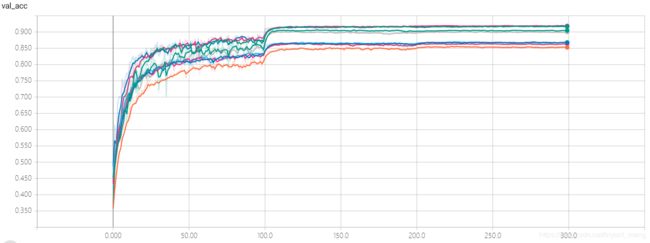
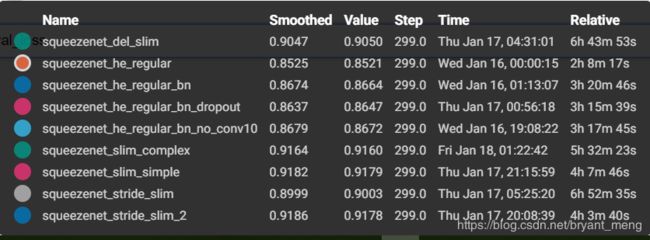
精度最高的是 squeezenet_stride_slim_2,alexnet 稍微调了下,精度能到 92%,哈哈哈,参考【Keras-AlexNet】CIFAR-10
模型大小
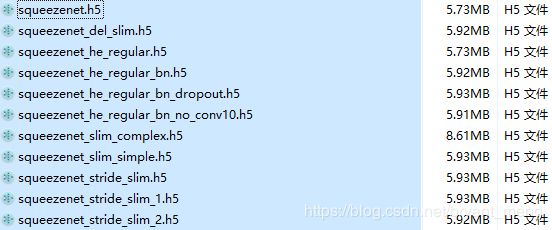
参数量
-
squeezenet
Total params: 729,144 -
squeezenet_he_regular
Total params: 729,144 -
squeezenet_he_regular_bn
Total params: 741,088 -
squeezenet_he_regular_bn_no_conv10
Total params: 740,938 -
squeezenet_he_regular_bn_dropout
Total params: 741,088 -
squeezenet_del_slim
Total params: 741,088 -
squeezenet_stride_slim
Total params: 741,088 -
squeezenet_stride_slim_1
Total params: 741,088 -
squeezenet_stride_slim_2
Total params: 741,088 -
simple bypass connection
Total params: 741,088 -
complex bypass connection
Total params: 1,087,456