首届中文NL2SQL挑战赛:千支队伍参赛,国防科大夺冠

(图片由AI科技大本营付费下载自视觉中国)
整理 | Jane
出品 | AI科技大本营(ID:rgznai100)
【导语】
10月12日,追一科技主办的首届中文NL2SQL挑战赛在激烈的决赛中落下帷幕,冠军由国防科技大学学生组成的「不上90不改名字」队伍获得。
此次比赛是中文NLP领域首次举办NL2SQL主题比赛,成为国内NLP技术比赛领域参赛规模最大的赛道之一。
赛事情况:国内外千支队伍,角逐Top5
(一)千支队伍挑战NL2SQL,角逐五强
任务上的创新、应用上的潜力,NL2SQL比赛一经推出,就受到了学界和工业界的广泛关注。据了解:
(1)自6月24日比赛启动以来,海内外共有1457支队伍、1630名选手报名参赛,参与院校数达170所,其中227支队伍、318名选手提交成绩。广泛的参与,使得NL2SQL成为国内NLP技术比赛领域参赛规模最大的赛道之一。
(2)参赛选手构成上,学生及科研人员占比48%,企业技术员工占比52%。学生参赛队伍来自众多知名院校,如北京大学、清华大学、复旦大学、上海交通大学、南京大学、浙江大学、中国科学技术大学、哈尔滨工业大学、西安交通大学等。
(3)虽然本次比赛的数据内容是中文形式,但仍然吸引了美国、英国、新加坡、日本、澳大利亚、加拿大等海外顶级院校参与,包括卡内基梅隆、墨尔本大学、新加坡国立大学、南安普顿大学、新南威尔士大学、布里斯托大学、昆士兰大学等。
(4)来自中国移动、平安集团、搜狗、达闼科技、中兴通讯、网宿科技、国双科技、捷通华声等众多企业的技术人员,也成为参赛队伍的重要力量。
从初赛、复赛到决赛,记录频频被刷新。比赛初期,排行榜头部选手们的分数聚集在0.58左右,已经超过了比赛方所提供的baseline。随后,选手通过各种讨论、交流,加深对数据集理解,不断探索更优的方案,从而提高成绩,头部选手的分数很快突破了0.80大关。在8月12日初赛结束时,比赛榜上的头部分数已经达到0.89,已经接近WikiSQL的成绩。
复赛阶段采用线上运行的方式来进行评测,测试集不可下载,并且内容对选手不可见。同时,测试集在保证数据分布与初赛测试集一致同时,加入更多在初赛中没有出现过的表格数据,届时,将对选手方案提出更高挑战。
(5)通过复赛,角逐出了本届大赛的五强队伍。
10 月 12 日,五强队伍在决赛前紧锣密鼓的做了专业细致的准备,在决赛现场带来了精彩的答辩,经过现场专家评委的提问打分后,评选出
首届中文NL2SQL挑战赛冠、亚、季军及优胜奖队伍。
-
冠军:不上90不改名字
张啸宇,国防科技大学16级博士生,从事自然语言处理相关研究,Kaggle Master;
赛斌,国防科技大学18级硕士生,从事大数据挖掘与应用相关研究;
王苏宏,从事NLP教育培训行业相关研究工作,曾在Kaggle大赛中获金牌、银牌。
-
亚军:BugCreater
戴威,清华大学硕士,现于北京国双科技数据科学团队负责NLP方向工作;
戴泽辉,清华大学博士,现于北京国双科技从事NLP方面的研究和工作;
陈华杰,哈尔滨工业大学硕士,现于北京国双科技从事NLP相关工作。
-
季军:Model S
陈曦,现于上海观安信息从事安全日志分析,业务风控等领域研究工作;
辜乘风,现于上海观安信息从事人工智能安全相关研究;
黄伊,现于妙盈科技从事金融领域文本分析、建模等相关工作。
-
优胜奖:老哥们不放假吗
赵猛,浙江大学计算机专业2018级硕士生,现于浙江大学数据智能实验室从事NLP相关研究。
-
优胜奖:大佬带我飞
戴志港,华南理工大学2019级硕士生,从事计算机视觉相关研究;
祝其乐,佛罗里达大学博士生,从事计算机视觉和自然语言处理相关研究和工作。

(决赛后五强队伍与专家评委合影留念)
比赛成绩的快速提升,充分体现出选手们的投入与方案的优秀,同时也侧面反映出,目前积累的许多技术方案都可以在NL2SQL这一个新任务上发挥作用,大家也意识到,只要有充分的数据来支撑, 目前人工智能领域的方法论可以有效地为数据库乃至结构化数据提供自然语言的交互方式。追一科技联合创始人兼CTO刘云峰博士表示,“此次挑战赛参与规模远超预期,显示出NL2SQL在学术和工业应用上的潜力,数据库的交互创新,正在受到越来越多关注”。
(二)挑战中文数据集
本次比赛发布了首个大规模的中文NL2SQL数据集。数据主要覆盖金融领域与通用领域,包括4,870张表格数据、49,752条标注数据。在这样大规模、多领域的数据集上,可以达到90%以上准确率,说明模型具有不错的泛化能力,相比于传统方案需要设计复杂而又繁琐的逻辑规则,新方案可以极大地降低技术上的工作量及维护系统的难度,实现十倍、百倍甚至更高的效率提升。
对比国外的WikiSQL、Spider、WikiTableQuestions等大规模英文NL2SQL数据集,本次比赛的数据集在兼顾数据规模的同时,引入了不一样的技术难点,例如口语化表达、结合表格内容、命名实体链接、更复杂的SQL语法等挑战,难度更高的同时,也更贴近于真实应用场景。
NL2SQL:当NLP唤醒数据库的灵魂六问
(一)什么是NL2SQL?
NL2SQL是自然语言处理技术的一个研究方向,可以将人类的自然语言自动转化为相应的SQL 语句(Structured Query Language结构化查询语言),进而可以与数据库直接交互、并返回交互的结果。比如我们问:大众 10 万到 20 万之间的车型有几种?NL2SQL可以让机器理解这样的自然语言,并从表格中检索出答案。
(二)NL2SQL应用前景,可以用在哪些场景,解决什么问题?
NL2SQL可以用在基于结构化知识的智能交互(问答),比如用户问“我上个月在南京的差旅住宿,花了多少钱?”这里面有时间上个月,地点南京,项目差旅等多个维信息检索需求,甚至更复杂、更多维的问题,AI也可以解答。
NL2SQl也可以用在搜索引擎的优化上,让搜索引擎更“聪明”。现在的信息检索技术,在检索文本时,对于文本中存在的表格内容是无区别对待的,也当做普通的文本来处理;结合NL2SQL,可以让检索模型结合普通文本及表格类文本进行更智能的检索。
NL2SQL的应用,一方面,在用户端让用户体验、感受更好,更加便捷、快速地获取获取信息服务,另一方面,在企业的IT和运营管理上,也会大大降低人力投入、繁琐的工作量。而且,能够有效地激活企业数据库知识价值,让数据库通过AI,可以直接面对面地服务用户,从而减少了专业人士、中间流程带来的信息壁垒。
具体场景上,在存在结构化知识的领域里,有多种NL2SQL的应用机会。
保险:保费查询、客户信息查询等内部业务数据查询
证券:覆盖行情信息、行业研报报表、财务报表等结构化数据
出行:支持酒店信息、火车票与飞机票查询等出行场景问答
电商:商品销量、商品详情、商品筛选与推荐等电商场景问答
零售:产品信息、活动细则等新零售场景问答
生活:话费查询、缴费查询、业务查询等日常生活问答
(三)NL2SQL背后都有哪些“黑科技”?
NL2SQL,让非专业人士,不需要学习和掌握数据库程序语言,就可以自由地查询各种丰富的数据库:
说句话就行。
没有条条框框的限制,内容和信息更加丰富。以前是程序员写一个“模板”,在这个模板里查询内容。
NL2SQL的实现,运用了大量前沿的人工智能算法模型,比如运用了多个预训练语言模型,相当于AI大脑,让AI读懂用户语言;运用了图神经网络,让AI“看到”数据库, 一目十行过目不忘,而且更加清晰地分清每个表格内容。
(四)NL2SQL在学术中的定位是怎么样的呢?
NL2SQL这一任务的本质,是将用户的自然语言语句转化为计算机可以理解并执行的规范语义表示(formal meaning representation),是语义分析(Semantic Parsing)领域的一个子任务。NL2SQL是由自然语言生成SQL,那么自然也有NL2Bash、NL2Python、NL2Java等类似的研究。下面是来自NL2Bash Dataset的一条数据,
NL: Search for the string ’git’ in all the files under current directory tree without traversing into ’.git’ folder and excluding files that have ’git’ in their names.
Bash: find . -not -name ".git" -not -path "*.git*" -not –name "*git*" | xargs -I {} grep git {}
虽然生成的程序语言不同,但核心任务与NL2SQL相同,都是需要计算机理解自然语言语句,并生成准确表达语句语义的可执行程序式语言。广义来说,KBQA也与NL2SQL技术有着千丝万缕的联系,其背后的做法也是将用户的自然语言,转化为逻辑形式,只不过不同的是转化的逻辑形式是SPARQL,而不是SQL。通过生成的查询语句在知识图谱中的执行,进而可以直接得到用户的答案,进而可以提升算法引擎的用户体验。

目前,NL2SQL方向已经有WikiSQL、Spider、WikiTableQuestions、ATIS等诸多公开数据集。不同数据集都有各自的特点,在这里分别来简单介绍一下这四个数据集,各有特色。
(1)WikiSQL
是Salesforce在2017年提出的一个大型标注NL2SQL数据集,也是目前规模最大的NL2SQL数据集。其中包含了26,375张表、87,726条自然语言问句及相应的SQL语句。下图是其中的一条数据样例,包括一个table、一条SQL语句及该条SQL语句所对应的自然语言语句。
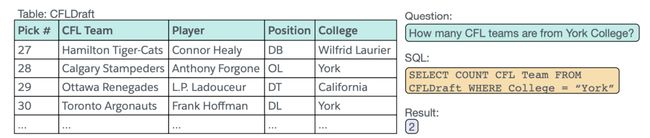
该数据集自提出之后,已经有17次公开提交。因为SQL的形式较为简单,不涉及到高级用法、Question所对应的正确表格已经给定、不需要联合多张表格等诸多问题的简化,目前在SQL执行结果准确率这一指标上已经达到了91.8%。
(2)Spider
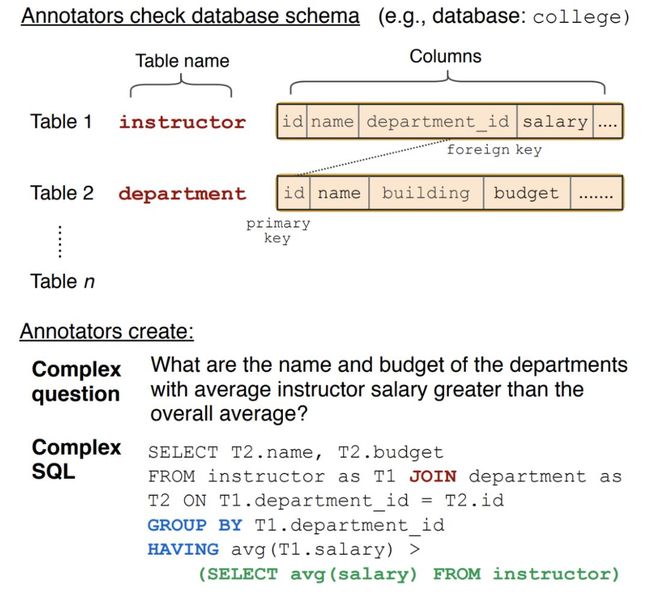
是耶鲁大学在2018年新提出的一个较大规模的NL2SQL数据集。该数据集包含了10,181条自然语言问句、分布在200个独立数据库中的5,693条SQL,并且内容覆盖了138个不同的领域。虽然在数据数量上不如WikiSQL,但Spider引入了更多的SQL用法,例如Group By、Order By、Having,甚至需要Join不同表,这更贴近于真实场景,也带来了更大的难度。因此目前在榜单上,只有5次提交,在不考虑条件判断中value的情况下,准确率最高只有24.3,可见这个数据集的难度非常大。
下图是该数据集中的一条样例。在这个以College主题的数据库中,用户询问“讲师的工资高于平均工资水平的部门以及相应的预算是什么?”,模型需要根据用户的问题和已知的数据库中的各种表格、字段以及之间错综复杂的关系来生成正确的SQL。
(3)WikiTableQuestions
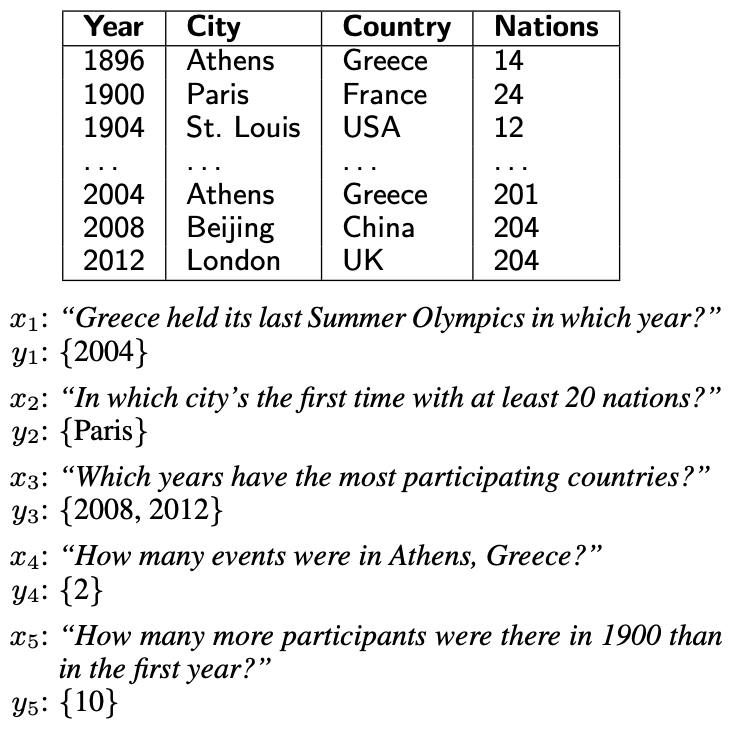
是斯坦佛大学于2015年提出的一个针对维基百科中那些半结构化表格问答的一个数据集,包含了22,033条真实问句以及2,108张表格。由于数据的来源是维基百科,因此表格中的数据是真实且没有经过归一化的,一个cell内可能包含多个实体或含义,比如“Beijing, China” or “200 km”;同时,为了可以很好地泛化到其它领域的数据,该数据集在测试集中的表格主题和实体之间的关系都是在训练集中没有见到过的。下图是该数据集中的一条示例,数据阐述的方式,展现出作者想要体现出的问答元素。
(4)而The Air Travel Information System(ATIS)
是一个年代较为久远的经典数据集,由德克萨斯仪器公司在1990年提出。该数据集获取自关系型数据库Official Airline Guide (OAG, 1990),包含27张表以及不到2000次的问询,每次问询平均7轮,93%的情况下需要联合3张以上的表来得到答案,问询的内容涵盖了航班、费用、城市、地面服务等信息。下图是取自该数据集中的一条样例,可以看得出来比之前介绍的数据集都更有难度得多。

在深度学习端到端解决方案流行之前,这一领域的解决方案主要是通过高质量的语法树和词典来构建语义解析器,再将自然语言语句转化为相应的SQL。

现在的解决方案则主要是端到端与SQL特征规则相结合。
以在WikiSQL数据集上的SOTA模型SQLova为例:首先使用BERT对Question和SQL表格进行编码和特征提取,然后根据数据集中SQL语句的句法特征,将预测生成SQL语句的任务解耦为6个子任务,分别是Select-Column、Select-Aggregation、Where-Number、Where-Column、Where-Operation以及Where-Value,不同子任务之间存在一定的依赖关系,最终使用提取到的特征,依次进行6个任务的预测。

(五)为什么发起此次比赛?
(1)NLP(自然语言处理)在经历多年厚积薄发之后,近些年来开始有所突破和爆发,并孕育出众多的创新机会,NL2SQL正是NLP一个新兴但非常有潜力的研究领域。
(2)从AI技术的发展规律来看,一个技术如果有专门的技术挑战赛,会非常快地加速这个技术的产业化落地,比如视觉的imagenet、人脸识别,NLP(自然语言处理)早期的分词、机器翻译,以及近期的阅读理解等领域,一些公开测试集或者挑战赛出现的时间点,恰好都是这个技术从论文走上产业化的临界点。很好的说明了技术比赛推动技术成熟的作用。
(3)AI落地一直存在一道鸿沟,就是大众认知,特别在企业服务领域,“AI技术可以解决什么问题”,“哪些AI技术可以解决我的问题”,在市场供需两者之间一直存在一道鸿沟,如何解决整个鸿沟,业内在进行各种尝试。希望这样的比赛能够成为一个平台和桥梁,除了技术开发和研究人员,更多的产业、企业伙伴乃至公众,也能够走近NL2SQL,走近NLP,走近AI,大家有更多地碰撞、分享、交流,在促进市场教育的同时,也让技术能够汲取更多的商业和应用视角,从而助推AI技术更快商业落地。
(六)NL2SQL的未来
WikiSQL数据集虽然是目前规模最大的有监督数据集,但其数据形式和难度过于简单:对于SQL语句,条件的表达只支持最基础的>、<、=,条件之间的关系只有and,不支持聚组、排序、嵌套等其它众多常用的SQL语法,不需要联合多表查询答案,真实答案所在表格已知等诸多问题的简化,所以在这个数据集上,SQL执行结果的准确率目前已经达到了91.8%。

但同时存在一个问题,这样的数据集并不符合真实的应用场景。在真实的场景中,用户问题中的值非常可能不是数据表中所出现的,需要一定的泛化才可以匹配到;真实的表之间存在错综复杂的键关联关系,想要得到真实答案,通常需要联合多张表进行查询;每一张都有不同的意义,并且每张表中列的意义也都不同,甚至可能相同名字的列,在不同的表格中所代表的含义是不同的;真实场景中,用户的问题表达会很丰富,会使用各种各样的条件来筛选数据。诸如此类的实际因素还有很多。因此,WikiSQL数据集起到的作用更多程度上是抛砖引玉,而不具备实际应用场景落地的价值。
相比之下,Spider等数据集更贴近于真实应用场景:涉及到查询语句嵌套、多表联合查询、并且支持几乎所有SQL语法的用法,用户问句的表达方式和语义信息也更丰富。但即使作者们考虑到数据集的难度,贴心地将数据集按照难度分为简单、中等和困难,数据集的难度也依然让人望而生畏,目前各项指标也都很低。
如何更好地结合数据库信息来理解并表达用户语句的语义、数据库的信息该如何编码及表达、复杂却有必要的SQL语句该如何生成,类似此类的挑战还有很多需要解决,都是非常值得探索的方向。
(*本文为 AI科技大本营整理文章,
转
载请微
信联系 1092722531
)
◆
精彩推荐
◆
2019 中国大数据技术大会(BDTC)再度来袭!豪华主席阵容及百位技术专家齐聚,15 场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读,深入解析热门技术在行业中的实践落地。
即日起,
限量 5 折票
开售,数量有限,扫码购买,先到先得!

推荐阅读
估值被砍700亿美元后,Waymo发重磅公开信:即将推出全自动驾驶打车服务
CVPR 2019论文阅读:Libra R-CNN如何解决不平衡对检测性能的影响?
多数编程语言里的0.1+0.2≠0.3?
人体姿态估计的过去、现在和未来
图灵奖得主Bengio再次警示:可解释因果关系是深度学习发展的当务之急
技术领域有哪些接地气又好玩的应用?
Python新工具:用三行代码提取PDF表格数据
国产嵌入式操作系统发展思考
2019 年诺贝尔物理学奖揭晓!三得主让宇宙“彻底改观”!
公链故事难再续?
你点的每个“在看”,我都认真当成了AI