阶层式分群
1、使用scipy绘制树状图
from sklearn.datasets import load_iris
iris=load_iris()
import scipy.cluster.hierarchy as sch
import matplotlib.pyplot as plt
dendrogram = sch.dendrogram(sch.linkage(iris.data,method='ward'))
# method='ward' 其他选择看sch.linkage帮助,常用ward
plt.title('Dendrogram')
plt.xlabel('Iris')
plt.ylabel('Euclidean distances')
plt.show()
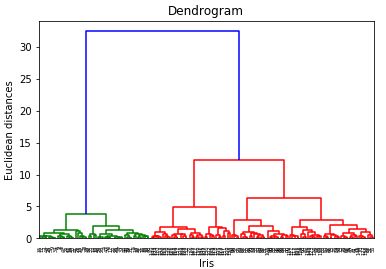
树状图
2、使用sklearn分群
from sklearn.cluster import AgglomerativeClustering
hc = AgglomerativeClustering(n_clusters=3,affinity='euclidean',linkage='ward')
# n_clusters 一般不设置,linkage常用ward,具体看函数帮助
y_hc = hc.fit_predict(iris.data)
plt.scatter(iris.data[y_hc==0,2],iris.data[y_hc==0,3],s=100,c='red',label='Cluster1')
plt.scatter(iris.data[y_hc==1,2],iris.data[y_hc==1,3],s=100,c='green',label='Cluster2')
plt.scatter(iris.data[y_hc==2,2],iris.data[y_hc==2,3],s=100,c='blue',label='Cluster3')
# 选择y_hc 分别为0,1,2的分组,使用iris.data的第3列(petal.length),第4列(petal.width)数据画图
plt.title('Culsters of Iris')
plt.xlabel('Petal.Length')
plt.ylabel('Petal.Width')
plt.legend()
plt.show()
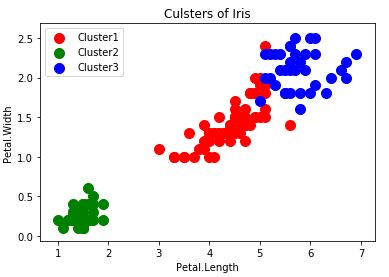
sklearn分群
k-means 分群
from sklearn.datasets import load_iris
iris=load_iris()
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3,init = 'k-means++',random_state=123)
# n_clusters指定分为几个群,其他参数设置查看KMeans帮助,
y_kmeans = kmeans.fit_predict(iris.data)
import matplotlib.pyplot as plt
plt.scatter(iris.data[y_kmeans==0,2],iris.data[y_kmeans==0,3],s=100,c='red',label='Cluster1')
plt.scatter(iris.data[y_kmeans==1,2],iris.data[y_kmeans==1,3],s=100,c='green',label='Cluster2')
plt.scatter(iris.data[y_kmeans==2,2],iris.data[y_kmeans==2,3],s=100,c='blue',label='Cluster3')
plt.scatter(kmeans.cluster_centers_[:,2],kmeans.cluster_centers_[:,3],s=100,c='yellow',label='center')
# kmeans.cluster_centers_ 得到3个群的中心点
plt.title('Culsters of Iris')
plt.xlabel('Petal.Length')
plt.ylabel('Petal.Width')
plt.legend()
plt.show()
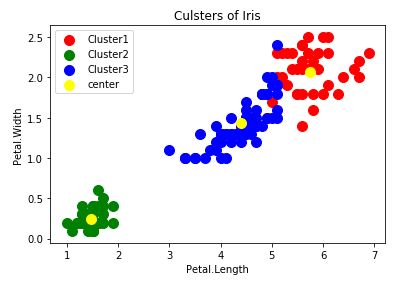
Kmeans分群
DBSCAN 分群
from sklearn.datasets import load_iris
iris=load_iris()
from sklearn.cluster import DBSCAN
dbs = DBSCAN(eps=1,min_samples=3)
# 无法设置分为几个群,eps点范围半径,半径内点成群,min_samples 最小3个成群
y_dbs = dbs.fit_predict(iris.data)
import matplotlib.pyplot as plt
plt.scatter(iris.data[y_dbs==0,2],iris.data[y_dbs==0,3],s=100,c='red',label='Cluster1')
plt.scatter(iris.data[y_dbs==1,2],iris.data[y_dbs==1,3],s=100,c='green',label='Cluster2')
plt.title('Culsters of Iris')
plt.xlabel('Petal.Length')
plt.ylabel('Petal.Width')
plt.legend()
plt.show()
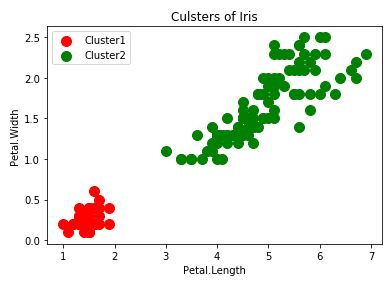
DBSCAN分群
k-means 和DBSCAN 对比
import numpy as np
from PIL import Image
img=Image.open('handwrite.png').convert('L').rotate(-90)
imgarr = np.array(img)
# convert('L') 将图片信息由三维转成二维,rotate(-90)将图片逆时针转90度
from sklearn.preprocessing import binarize
imagedata = np.where(binarize(imgarr,0)==0) # 将图片信息转成布尔型
import matplotlib.pyplot as plt
plt.scatter(imagedata[0],imagedata[1],s=100,c='red',label='Cluster1')
plt.legend()
plt.show()
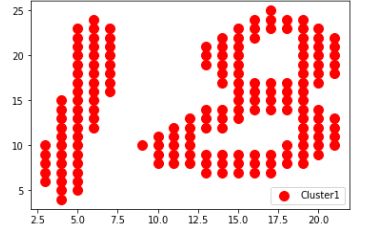
将1和8 分开
使用kmeans
from sklearn.cluster import KMeans
X = np.column_stack([imagedata[0],imagedata[1]])
kmeans = KMeans(n_clusters=2,init='k-means++',random_state=137)
y_kmeans = kmeans.fit_predict(X)
plt.scatter(X[y_kmeans==0,0],X[y_kmeans==0,1],s=100,c='red',label='Cluster1')
plt.scatter(X[y_kmeans==1,0],X[y_kmeans==1,1],s=100,c='blue',label='Cluster2')
plt.scatter(kmeans.cluster_centers_[:,0],kmeans.cluster_centers_[:,1],s=100,c='yellow',label='central')
plt.legend()
plt.show()
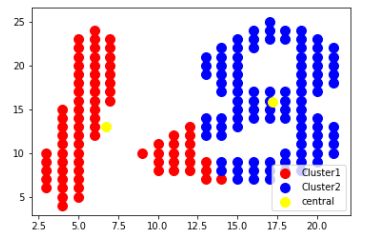
kmeans分群
使用DBSCAN
from sklearn.cluster import DBSCAN
dbs =DBSCAN(eps=1,min_samples =3)
y_dbs = dbs.fit_predict(X)
plt.scatter(X[y_dbs==0,0],X[y_dbs==0,1],s=100,c='red',label='Cluster1')
plt.scatter(X[y_dbs==1,0],X[y_dbs==1,1],s=100,c='blue',label='Cluster2')
plt.legend()
plt.show()
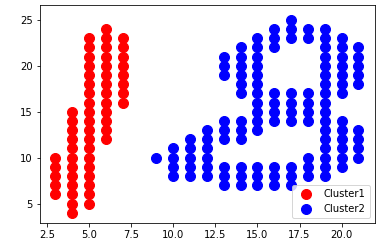
DBSCAN分群
分群结果评价
阶层式分群和kmeans分群都要事先输入分成几个群,以下方法主要判断分为几个群比较好。
方法一 WCSS(with-in cluster sum of square)
import pandas
dataset = pandas.read_csv('Data/customers.csv')
dataset['sex'] = dataset['Genre'].map(lambda e:1 if e=='Male' else 0) # 数据预处理
del dataset['Genre'],dataset['CustomerID'] # 数据预处理
X = dataset.values
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 5,init='k-means++',random_state=42)
y_kmeans = kmeans.fit_predict(X)
print(kmeans.inertia_) # kmeans.inertia_ 就是这次kmeans模型的WCSS
import matplotlib.pyplot as plt
wcss= []
for i in range(1,11):
kmeans = KMeans(n_clusters= i ,init='k-means++',random_state=42) #将数据分成1-10个群,分别计算WCSS,然后画图
kmeans.fit(X)
wcss.append(kmeans.inertia_)
plt.plot(range(1,11),wcss)
plt.title('The Elbow Method')
plt.xlabel('Number of clusters')
plt.ylabel('WCSS')
plt.show()
得到的WCSS图,拐点处为最佳的分群数量(很难看出来,个人觉得这个方法没什么用)
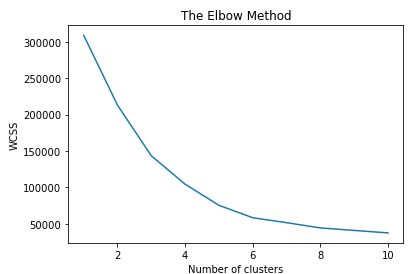
WCSS
方法二 silhouette coefficient
silhouette值越高,分群效果越好
from sklearn import metrics
import matplotlib.pyplot as plt
sil = []
for i in range(2,11):
kmeans= KMeans(n_clusters=i,init='k-means++',random_state=42) # 分成2-10群,分别计算silhouette值,画图
y_kmeans = kmeans.fit_predict(X)
sil.append(metrics.silhouette_score(X,y_kmeans))
plt.plot(range(2,11),sil)
plt.title('The Silhouette Method')
plt.xlabel('Number of clusters')
plt.ylabel('Silhouette Coefficient')
plt.show()
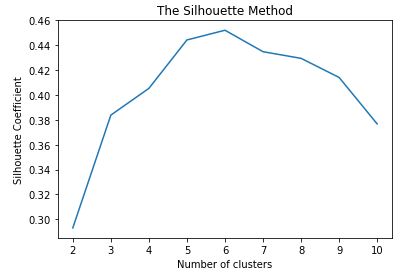
silhouette method
通过silhouette值比较不同分群方法
from sklearn.cluster import AgglomerativeClustering
from sklearn.cluster import KMeans
ward = AgglomerativeClustering(n_clusters=5,affinity='euclidean',linkage='ward')
y_ward = ward.fit_predict(X)
complete = AgglomerativeClustering(n_clusters=5,affinity='euclidean',linkage='complete')
y_complete = complete.fit_predict(X)
kmeans = KMeans(n_clusters=5,init='k-means++',random_state=42)
y_kmeans= kmeans.fit_predict(X)
for est,title in zip([y_ward,y_complete,y_kmeans],['ward','complete','kmeans']):
print(title,metrics.silhouette_score(X,est))
# ward 0.439975272125
# complete 0.439975272125
# kmeans 0.444242912753
# kmeans方法的silhouette值最高,分群效果最好