Flink的基本概念与架构
概述
Flink是构建在数据流之上的一款有状态计算框架。通常被人们称为第三代大数据分析方案。
第一代大数据处理方案:Hadoop Map Reduce 静态批处理 | Storm实时流计算,两套独立的计算引擎,开发难度大。
第二代大数据处理方案: Spark RDD静态批处理、Spark Streaming(DStream)实时流计算(实时性差),统一的计算引擎 难度小。
第三代大数据处理方案:Apache Flink DataStream 流处理、Flink DataSet 批处理框架 2014年12月可以看出spark和Flink几乎同时诞生,但是Flink之所以成为第三代大数据处理方案,原因是因为早期人们对大数据分析的认知或者业务场景大都停留在批处理领域。才导致了Flink的发展相比较于Spark 较为缓慢,直到2017年人们才慢慢将 批处理开始转向流处理 。
更多介绍:https://blog.csdn.net/weixin_38231448/article/details/100062961
流计算场景:实时计算领域,系统监控、舆情监控、交通预测、国家电网、疾病预测,银行/金融风控。
Spark VS Flink

Flink 核心是一个流式的数据执行引擎,其针对数据流的分布式计算提供了数据分布、数据通信、以及容错机制等功能。基于流执行引擎,Flink提供了诸多更高抽象层的API以便用户编写分布式任务。
DataSet API:对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便的使用Flink提供的各种操作符对分布式数据集进行处理,支持Java、Scala、和Python。
DataStream API:对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便地对分布式数据进行各种操作,支持Java和Scala。
Table API:对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过类SQL的DSL对关系表进行各种查询操作,支持Java和Scala。此外,Flink还针对特定的应用领域提供了领域库
Flink ML,Flink的机器学习库,提供了机器学习Pipelines API并实现了多种机器学习算法。
Gelly,Flink的图计算库,提供了图计算的相关API及多种图计算算法实现。
Flink 架构
Flink概念
Tasks and Operator Chains(阶段划分)
对Flink分布式执行,Flink尝试根据任务计算并行度,将若干个操作符连接成一个任务Task(阶段-stage),一个Flink的计算任务通常会被拆分成若干Task,每一个Task都有自己任务并行度,每个并行度表示一个线程-subtask.
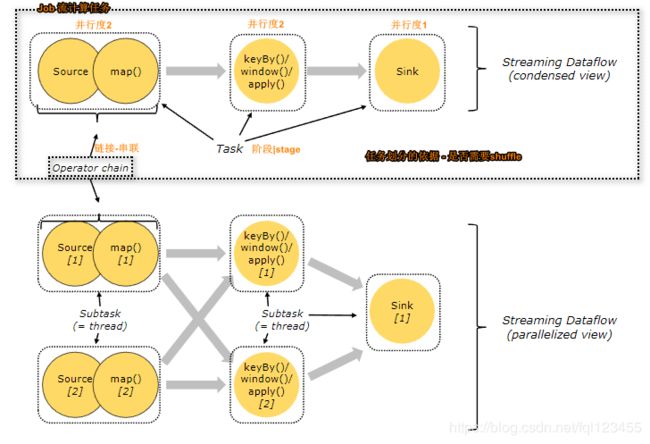
- Task 等价于Spark任务中Stage
- OPerator Chain Flink通过Operator Chain方式实现Task划分,有点类似Spark宽窄依赖。Operator Chain方式有两种
forward、hash|rebalance
Job Managers, Task Managers, Clients
JobManagers(Master) :协调并行计算任务。负责调度Tasks、协调checkpoint以及故障恢复,等价Spark Master+Driver
There is always at least one Job Manager. A high-availability setup will have multiple JobManagers, one of which one is always the leader, and the others are standby.
TaskManagers(Slaves):真正负责Task执行节点(执行subtask|线程),同时需要向JobManagers汇报节点状态以及工作负荷。
client:和Spark不同,Client并不是集群计算的一部分,只负责任务提交== dataflow ==(类似Spark DAG图)给JobManager。提交完成后可以退出。与spark的client称为Driver,负责生产DAG并且监控整个任务的执行和故障恢复。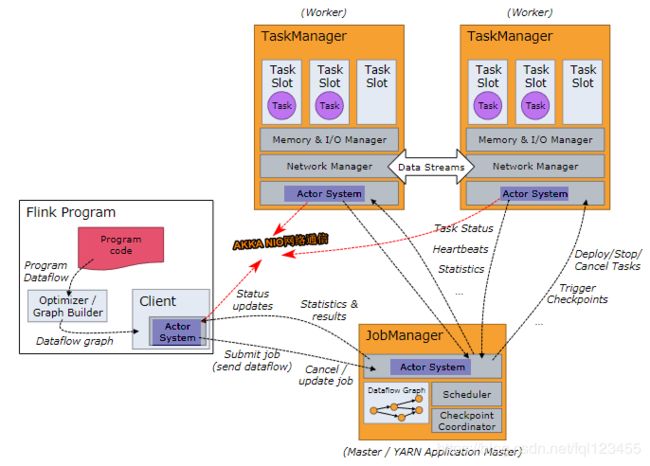
Task Slots and Resources
每个Worker(TaskManager)是一个JVM进程,可以执行一个或多个子任务(Thread|subtask)。为了控制woker接受多少个任务,Woker具有所谓的Task Slot(至少一个task slot)。
每个Task Slot代表TaskManager资源的固定子集。例如,具有3个slot的TaskManager则每个slot表示占用当前TaskManager进程的1/3的内存。每个Job在启动的时候都有自己的TaskSlots-数目是固定的,这样通过slot划分就可以避免不同job的subtask之间竞争内存资源。
以下表示一个Job获取6个slot,但是仅仅只有5个线程,3个task .
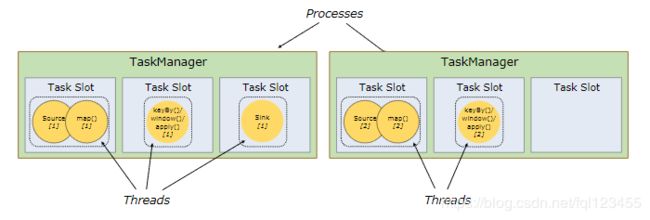
默认来自同一个job的不同task(阶段)的subtask可以共享task slot。默认情况下Flink中job计算所需的slots的个数是由Task中最大并行度所决定。
- Flink集群所需的任务槽与作业中使用的最高并行度恰好一样多。
- 更容易获得更好的资源利用率。如果没有插槽共享,则非密集型source / map()子任务将阻塞与资源密集型window子任务一样多的资源。通过slot共享可以讲任务并行度由2增加到6,可以得到如下资源分配。
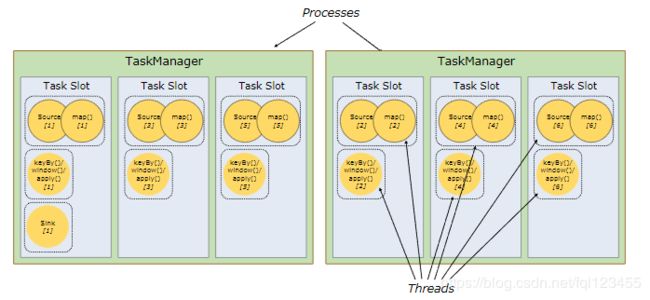
- 更多参考:https://ci.apache.org/projects/flink/flink-docs-release-1.9/concepts/runtime.html