目标跟踪算法五:MDNet: Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
目标跟踪算法五:MDNet: Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
原文:https://zhuanlan.zhihu.com/p/25312850文章链接: 在这里
代码链接: https:// github.com/HyeonseobNam /MDNet
MDNet是2015年VOT的冠军。这篇文章其实2015年底就出来了,被这是我第三次读它了。MDNet是Korea的POSTECH这个团队做的,与TCNN和CNN-SVM同一出处。
2015年底的时候,Visual Tracking领域继Object Detection之后,陆续将CNN引入,但是大部分算法只是用在大量数据上训练好的(pretrain)的一些网络如VGG作为特征提取器,结果证明确实用了CNN深度特征对跟踪结果是有较大的改进的。那么其实自己设计一个网络来做跟踪是大家都能够想到的思路,Korea的POSTECH这个团队就做了MDNet。但是为什么其实自己设计网络的并不多呢?因为训练数据是个问题,再者MDNet的效果在当时来说几乎是无法超越的。来看看它是怎么做的吧。
1. Motivations
- 对于跟踪问题来说,CNN应该是由视频跟踪的数据训练得到的更为合理。所有的跟踪目标,虽然类别各不相同,但其实他们应该都存在某种共性,这是需要网络去学的。
- 用跟踪数据来训练很难,因为同一个object,在某个序列中是目标,在另外一个序列中可能就是背景,而且每个序列的目标存在相当大的差异,而且会经历各种挑战,比如遮挡、形变等等。
- 现有的很多训练好的网络主要针对的任务比如目标检测、分类、分割等的网络很大,因为他们要分出很多类别的目标。而在跟踪问题中,一个网络只需要分两类:目标和背景。而且目标一般都相对比较小,那么其实不需要这么大的网络,会增加计算负担。
2. Multi-Domain Network(MDNet)
2.1 网络结构
首先来看看MDNet的网络结构:
- Input: 网络的输入是107x107的Bounding box,设置为这个尺寸是为了在卷积层conv3能够得到3x3的feature map。
- Convolutional layers: 网络的卷积层conv1-conv3来自于VGG-M [1]网络,只是输入的大小做了改变。
- Fully connected layers: 接下来的两个全连接层fc4,fc5各有512个输出单元,并设计有ReLUs和Dropouts。fc6是一个二分类层(Domain-specific layers),一共有K个,对应K个Branches(即K个不同的视频),每次训练的时候只有对应该视频的fc6被使用,前面的层都是共享的。
为了学到不同视频中目标的共性,采用Domain-specific的训练方式:假设用K个视频来做训练,一共做N次循环。每一个mini-batch的构成是从某一视频中随机采8帧图片,在这8帧图片上随机采32个正样本和96个负样本,即每个mini-batch由某一个视频的128个框来构成。在每一次循环中,会做K次迭代,依次用K个视频的mini-batch来做训练,重复进行N次循环。用SGD进行训练,每个视频会对应自己的fc6层。通过这样的训练来学得各个视频中目标的共性。训练好的网络在做test的时候,会新建一个fc6层,在线fine-tune fc4-fc6层,卷积层保持不变。
2.2 用MDNet来做跟踪
2.2.1 网络在线更新策略
采用long-term和short-term两种更新方式。在跟踪的过程中,会保存历史跟踪到的目标作为正样本,当然样本是在得分高于一个阈值的时候才会被添加作为训练的正样本的。long-term对应历史的100个样本(超过100个抛弃最早的),固定时间间隔做一次网络的更新(程序中设置为每8帧更新一次),short-term对应20个(超过20个抛弃最早的),在目标得分低于0.5进行更新。负样本都是用short-term的方式收集的。另外在训练中负样本的生成用到了hard negative mining [2],就是让负样本越来越难分,从而使得网络的判别能力越来越强。
2.2.2 目标跟踪
每次新来一帧图片,以上一帧的目标位置为中心,用多维高斯分布(宽,高,尺度三个维度)的形式进行采样256个candidates,将他们大小统一为107x107后,分别作为网络的输入进行计算。
网络的输出是一个二维的向量,分别表示输入的bounding box对应目标和背景的概率。目标最终是确定为目标得分概率最高的那个bounding box:
最后得到的candidate其实不是直接作为目标,还要做一部bounding box regression。做法与R-CNN [3]一样,是常规算法,就不细讲了。这一步对最后的结果贡献还是有的,可以看下面的实验结果。
2.3 实验
2.3.1 OTB50和OTB100
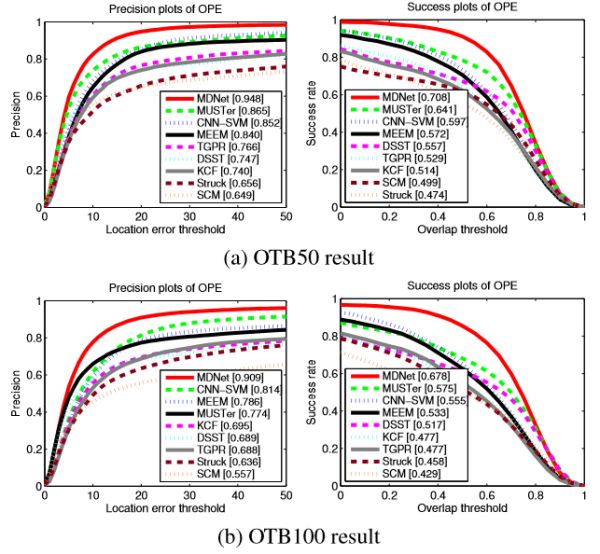 2.3.2 VOT2014
2.3.2 VOT2014
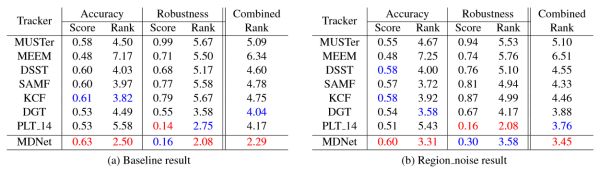
2.3.3 自身对比实验
作者对文章中用到的一些策略做了结果验证。首先是不用多域训练,而是单域训练的SDNet,不做bounding box regression的MDNet-BB,以及不做hard negative mining和bounding box regression的MDNet-BB-HM,结果如下:
可以看到Multi-domain策略的提升在两个指标都比较明显,有3%~4%。另外hard negative mining和bounding box regression对结果也是有贡献的。
3. Conclusion
总结一下MDNet效果好的原因:- 用了CNN特征,并且是专门为了tracking设计的网络,用tracking的数据集做了训练
- 有做在线的微调fine-tune,这一点虽然使得速度慢,但是对结果很重要
- Candidates的采样同时也考虑到了尺度,使得对尺度变化的视频也相对鲁棒
- Hard negative mining和bounding box regression这两个策略的使用,使得结果更加精确
[1] K. Chatfield, K. Simonyan, A. Vedaldi, and A. Zisserman. Return of the devil in the details: Delving deep into convolutional nets. In BMVC, 2014
[2] K.-K. Sung and T. Poggio. Example-based learning for viewbased human face detection. IEEE Trans. Pattern Anal. Mach. Intell., 20(1):39–51, 1998.
[3] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014.