NLP学习路径(七):NLP文本向量化
1、文本向量化概述
(1)含义
文本向量化就是将文本表示成一系列能够表达文本语义的向量。词语都是表达文本处理的最基本单元。当前阶段,对文本向量化大部分研究都是通过词向量化实现的。但也有一部分将文章或者句子作为文本处理的基本单元,于是产生了doc2vec和str2vec技术。
(2)方法
word2vec(词语),doc2vec(文章),str2vec(句子)
2、向量化算法 word2vec
词袋模型是最早的以词语为基本处理单元的文本向量化方法。
①John likes to watch movies,Mary likes too.
②John also likes to watch football games.
基于上述两个文档中出现的单词,构造如下词典:
{"John":1,"likes":2,"to":3,......},该词典中共包含10个单词,每个单词都有一个唯一的索引,那么每个文本我们都可以使用一个10维的向量来表示。
[1,2,1,1,1.....]
该向量与原来文本中单词出现的顺序没有关系,而是词典中每个单词在文本中出现的频率。但是这种方法存在如下三个问题:
1)维度灾难;2)无法保留词序信息;3)存在语义鸿沟的问题
词向量(doc2vec)技术就是为了利用神经网络从大量无标注的文本中提取有用信息而产生的。因为词袋模型只是将词语符号化,所以词袋模型是不包含任何语义信息的。神经网络词向量模型就是根据上下文与目标词之间的关系进行建模。
(1)神经网络语言模型(NNML)
与传统方法估算P(wi|wi-(n-1),...,wi-1)不同,NNLM模型直接通过一个神经网络结构对n元条件概率进行估计。
NNLM的基本结构图如下所示:
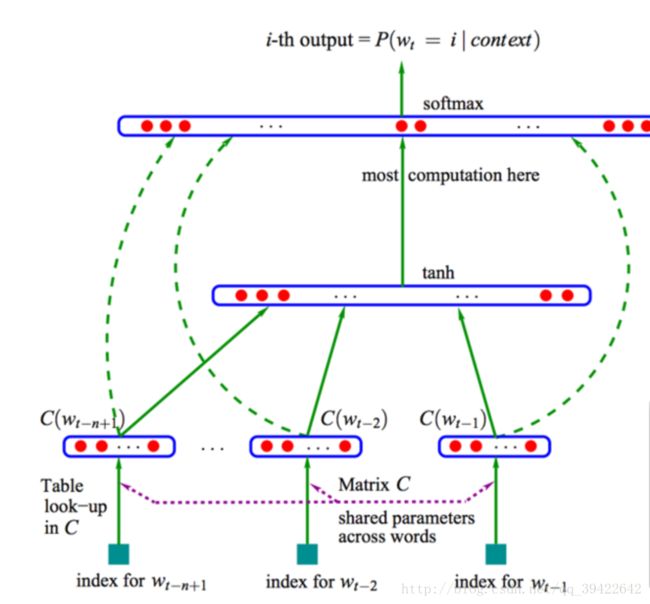
大致的操作是:从语料库中搜集一系列长度为n的文本序列wi-(n-1),...,wi-1,wi,假设这些长度为n的文本序列组成的集合为D,那么NNLM的目标函数为:
∑P(wi|wi-(n-1),...,wi-1),含义为:在输入词序列为wi-(n-1),...,wi-1的情况下,计算目标为wi的概率。
上图所示的神经网络语言模型是经典的三层前馈神经网络结构,为解决词袋模型数据稀疏的问题,输入层的输入为低维度的、紧密的词向量,输入层的操作就是将词序列wi-(n-1),...,wi-1中的每个词向量按顺序拼接,比如:x=[v(wi-(n-1));...;v(wi-2);v(wi-1)]。在输入层得到x后,将x输入隐藏层得到h,再将h接入输出层得到最后的输出变量y,隐藏层变量h和输出变量y的计算如下所示:
①h=tanh(b+Hx) ②y=b+Uh
上式中H为输入层到隐藏层的权重矩阵,其维度为|h|*(n-1)|e|;U为隐藏层到输出层的权重矩阵,其维度为|V|*|h|,|V|表示词表的大小;b为模型中的偏置项。NNLM模型中最大的计算量就是隐藏层到输出层的矩阵运算Uh。输出变量y是一个|V|维的向量,该向量的每一个分量依次对应下一个词为词表中某个词的可能性。用y(w)表示有NNML模型计算得到的目标词w的输出量,为保证输出y(w)的表示概率值,需要对输出层进行归一化操作。一般在输出层之后加入softmax函数,将y转化成对应的概率值。
在相似的上下文语境中,NNML模型可以预测出相似的目标词。输出的y(wi)代表上文出现词序列wi-(n-1),...,wi-1的情况下,下一个词为wi的概率,因此在语料库D中最大化y(wi)是NNML的目标函数,即∑logP(wi|wi-(n-1),...,wi-1)。一般使用随机梯度下降算法对NNML模型进行训练。
(2)C&W模型
NNLM模型的目标是构建一个语言概率模型,而C&W则是以生成词向量为目标的模型。C&W模型没有采用语言模型的方式去求解词语上下文的条件概率,而是直接对n元短语打分。
C&W的核心机理是:如果n元短语在语料库中出现过,那么模型会给该短语打高分,反之短语会得到比较低的评分。结构如下图所示:
C&W模型需要优化的目标函数为:
其中(w,c)为从语料库中抽取的n元短语,为保证上下文词数的一致性,n因为奇数;w是目标词;c表示上下文语境;w’是从词典中随机抽取的一个词语。C&W模型采用成对词语的方式对目标函数进行优化。目标函数期望正样本的得分比负样本至少高一分。(w,c)表示正样本,该样本来自语料库;(w',c)表示负样本,负样本是将正样本序列中的中间词替换成其他词得到的。一般,用一个随机的词语替换正确文本序列的中间词,得到新的文本序列基本上都是不符合语法习惯的错误序列,因此这种构造负样本的方法是合理的。同时由于负样本仅仅是修改了正样本的一个词的得来的,故其基本的语境没有改变,不会对分类结果造成太大的影响。
与NNML模型的目标词在输出层不同,C&W模型的输入层就包含了目标词,其输出层也变为一个节点,该节点输出值的大小代表n元短语的打分高低。
(3)CBOW模型
CBOW的模型图如下所示:
CBOW模型使用一段文本中的中间词作为目标词;同时CBOW模型去掉了隐藏层,大幅提升了运算速率。CBOW模型使用上下文各词的词向量的平均值替代NNML模型各个拼接的词向量。由于CBOW模型去除了隐藏层,所以其输入层就是语义上下文的表示。
上述为CBOW模型对目标词的条件概率计算式。
CBOW的目标函数与NNML相似,为最大化:
CBOW的计算流程:
- 随机生成一个所有单词的词向量矩阵,每一个行对应一个单词的向量
- 对于某一个单词(中心词),从矩阵中提取其周边单词的词向量
- 求周边单词的的词向量的均值向量
- 在该均值向量上使用logistic regression 进行训练,softmax作为激活函数
- 期望回归得到的概率向量可以与真实的概率向量(即中心词的one-hot编码向量)相匹配
(4)Skip-gram模型
Skip-gram模型的结构图同样没有隐藏层,但与CBOW模型输入上下文词的平均词向量不同,Skip-gram模型是从目标词w的上下文中选择一个词,将其词向量组成上下文的表示。
对整个语料而言,Skip-gram模型的目标函数为最大化:
CBOW的目标是根据上下文来预测当前词语的概率,且上下文所有的词对当前词出现的概率影响的权重是一样的。Skip-gram刚好相反,其实根据当前词语来预测上下文概率的。
3、向量化算法doc2vec/str2vec
word2vec基于分布假说理论可以很好地提取词语的语义信息,利用word2vec技术计算词语间的相似度有非常好的效果。同时其也用于计算句子或者其他长文本间的相似度,其一般的做法是:对文本分词后,提取其关键词,用词向量表示这些关键词,接着对关键词向量求平均或者将其拼接,最后利用词向量计算文本间的相似度。但是这种方法丢失了文本中的语序信息。
doc2vec技术存在两种模型:DM;DBOW。分别对应word2vec技术中的CBOW和Skip-gram模型。DM模型试图预测给定上下文中某单词出现的概率,只不过DM模型的上下文不仅包括上下文单词而且还包括相应的段落。DBOW则在仅给定段落向量的情况下预测段落中一组随机单词的概率。
(1)DM
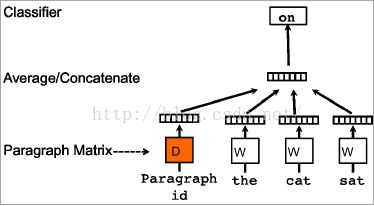
与CBOW模型相比,DM模型增加了一个与词向量长度相等的段向量,DM模型结合词向量和段向量预测目标词的概率分布。在训练的过程中,DM模型增加了一个paragraph id,它也是先映射成一个向量,即paragraph vector(矢量)。虽然paragraph vector和word vector的维数相等,但是代表两个不同的向量空间。在后面的计算中,paragraph vector和word vector累加或者拼接,将其输入softmax层。在一个句子或者文档的训练过程中,paragraph id不变,共享者同一个paragraph vector,相当于每次在预测单词的概率时,都利用了整个句子的语义。在预测阶段,给待预测的句子新分配一个paragraph id,重新利用随机梯度下降法训练待预测的句子,带误差收敛后,就得到待预测句子的paragraph vector。
(2)DBOW模型
DM模型通过段落向量和词向量相结合的方式预测目标词的概率分布,而DBOW模型的输入只有段落向量,它通过一个段落向量预测段落中某个随机词的概率分布。
4、实战:将网页文本向量化
参考:《pytho自然语言处理实战 核心技术与算法》