hive select 语句
hive 查询操作:
1、列匹配正则表达式
select 查询列使用正则表达式匹配列,hive 0.13 版本之前直接用。0.13及后续版本需要开设置hive的属性
set hive.support.quoted.identifiers=none;
hive (mydb)> select `price.*` from stocks;
OK
3.31 1.31 3.94 15.45 34.0
8.81 1.31 3.94 15.15 14.0
2.31 3.21 6.54 15.45 34.0
3.31 1.31 3.94 15.45 34.0
8.81 1.31 3.94 15.15 14.0
3.31 1.31 3.94 15.45 34.0
8.81 1.31 3.94 15.15 14.0
Time taken: 0.109 seconds, Fetched: 7 row(s)
hive (mydb)> desc stocks;
OK
exchanges string
symbol string
ymd string
price_open float
price_high float
price_low float
price_close float
volume int
2、查询集合数据类型,Hive输出的格式
hive (mydb)> desc employees;
name string Employee name
salary float Employee salary
subordinates array Name of subordinates
deductions map keys are deductions name,values are percentages
address struct Home address
hive (mydb)> select * from employees;
lisi 1402.65 ["chengliu","wangba"] {"guoshui":0.1,"dishui":0.05,"ps":0.02} {"street":"longhua","city":"shenzhen","state":"guangdong","zip":null}
lisi 1402.65 ["chengliu","wangba"] {"guoshui":0.1,"dishui":0.05,"ps":0.02} {"street":"longhua","city":"shenzhen","state":"guangdong","zip":null}
wangwu 154012.34 ["zhaoliu","zhangwu"] {"guoshui":0.1,"dishui":0.05,"ps":0.02} {"street":"futian","city":"shenzhen","state":"guangdong","zip":51800
array:元素是string类型,输出会使用双引号括起来,元素之间使用逗号隔开
string:基本数据类型,string 输出不使用双引号括起来
map: key 是string类型,value是float类型。输出{‘key’:value}
struct: JSON map 输出
3、查看数组的元素。数组下角标从0开始
hive (mydb)> SELECT name,subordinates[0],subordinates[1] FROM employees;
lisi chengliu wangba
lisi chengliu wangba
wangwu zhaoliu zhangwu
4、引用map中的元素
hive (mydb)> SELECT name,deductions["guoshui"] FROM employees;
lisi 0.1
lisi 0.1
wangwu 0.1
如果输入的key不存在会返回NULL
5、引用struct 中的元素
hive (mydb)> SELECT name,address.city FROM employees;
lisi shenzhen
lisi shenzhen
wangwu shenzhen
6、数学函数

#rount(d) d DOUBLE return BIGINT
# 四舍五入,只关注第一位小数是否大于等于5,大于或等于5,整数部分加1,然后返回,小于5,直接返回整数部分。最终返回整数部分和一位小数.0
hive (mydb)> select round(5.2312934394392);
5.0
hive (mydb)> select round(5.6312934394392);
6.0
hive (mydb)> select round(5.4);
5.0
hive (mydb)> select round(5.5);
6.0
#round(m,n) m DOUBLE,n int 表示保留几位小数,其他的四舍五入。 return DOUBLE
hive (mydb)> select round(5.11654546,3);
5.117
hive (mydb)> select round(5.11644546,3);
#floor(d) d DOUBLE return BIGINT 舍弃小数部分,返回整数部分,注意精度
hive (mydb)> select floor(3.6989080384023840);
3
hive (mydb)> select floor(3.69);
3
hive (mydb)> select floor(3.09);
3
hive (mydb)> select floor(2.999999999999999);
2
hive (mydb)> select floor(2.9999999999999998); #这个是临界值
3
hive (mydb)> select floor(2.9999999999999999);
3
#ceil(d) 和 ceiling(d) 两个函数一样 d DOUBLE return BIGINT。舍弃小数部分整数+1。同样要注意精度
hive (mydb)> select ceil(5.080982304823089402394);
6
hive (mydb)> select ceil(5.980982304823089402394);
6
hive (mydb)> select ceil(5.01);
6
hive (mydb)> select ceil(4.99);
hive (mydb)> select ceil(4.0000000000000001);
4
hive (mydb)> select ceil(4.000000000000001);# 临界值
5
hive (mydb)> select ceiling(4.0000000000000001);
4
hive (mydb)> select ceiling(4.000000000000001);
5
# rand() rand(seed) seed INT 随机因子 return DOUBLE 随机数
hive (mydb)> select rand();
0.17106158941936 # 小于1的随机数
hive (mydb)> select rand(1); # 无论这条命令运行多少次,值都不会发生变化,随机返回一个固定的数
0.7308781907032909 # 带随机因子后,返回固定小于1的double类型的小数。除非随机因子发生变化,否则返回的值不变
#exp(d) d DOUBLE return DOUBLE
hive (mydb)> select exp(1); # e=2.718281828459045
2.718281828459045
hive (mydb)> select exp(2); # e * e
7.38905609893065
hive (mydb)> select exp(3.5);
33.11545195869231
hive (mydb)> select exp(0.5);
1.6487212707001282
hive (mydb)> select exp(-0.5);
0.6065306597126334
# ln(d) d DOUBLE return DOUBLE
# log10(d),log2(d) d DOUBLE return DOUBLE
# log(m,n) m,n DOUBLE return DOUBLE 求以m为底n的对数
hive (mydb)> select ln(10); # ln10 以e为低10的对数
2.302585092994046
hive (mydb)> select log10(10);
1.0
hive (mydb)> select log10(100); #log100 以10为低100的对数
2.0
hive (mydb)> select log10(89.06);
1.949682690795204
hive (mydb)> select log2(8); #以2为低8的对数
3.0
hive (mydb)> select log2(20);
4.321928094887363
hive (mydb)> select log(4,64); #以4为低64的对数。log(m,n) 以m为低n的对数。m,n都为double类型
3.0
hive (mydb)> select log(2,64);
6.0
# power(m,n) pow(m,n) 这两个函数功能一样 m,n DOUBLE return DOUBLE
hive (mydb)> select pow(2,3);
8.0
hive (mydb)> select pow(3,4); # 3^4=81
81.0
hive (mydb)> select power(2,4); # 2^4=16
16.0
hive (mydb)> select power(2,3.2);
9.18958683997628
hive (mydb)> select power(16,0.5);#0.5 次幂也就是求开平方根
4.0
# sqrt(d) d DOUBLE
hive (mydb)> select sqrt(16); #求开平方根
4.0
# bin(d) d BIGINT 或者 STRING return DOUBLE
hive (mydb)> select bin(20); #10 进制转换2进制
10100
hive (mydb)> select bin(255);
11111111
# hex(d) d BINARY 或者 STRING 或者 BIGINT return STRING
hive (mydb)> select hex(255);# 10 进制转换16进制
FF
hive (mydb)> select hex(111111);
1B207
hive (mydb)> select hex('111111'); # 将字符串转换成16进制,acs码转换
313131313131
hive (mydb)> select hex('a'); # a --> 97 十进制,查asc 码表
61
hive (mydb)> select hex('A'); # hex(d) d 可以是数值类型,string 类型,以及binary类型。
41
# binary 类型不知道如何换算,1 --> 31 10--> D7
hive (mydb)> select unhex('c'); # 这个没有输出,不知道什么原因。unhex(d) d:string 类型,返回binary类型
# CONV(m,n,k) m INT 或者 STRING 类型;n,k INT return STRING 将m 有n进制转换成k进制。注意m的值要符合n进制。如2进制,m的值只能是0或者1组成
hive (mydb)> select conv(10,2,8); # 将10 2进制 转换为8进制
2
hive (mydb)> select conv(255,2,16); # conv(num,i,j) 将num 由i进制转换成j进制。5在2进制中是不存在的
0
hive (mydb)> select conv(255,10,16);
FF
hive (mydb)> select conv(255,8,16);
AD
hive (mydb)> select conv(255,2,16);
0
hive (mydb)> select conv(11111111,2,16); # 2进制只有01
FF
hive (mydb)> select conv('ABCD',16,2); # conv(string,i,j) 将string这个字符串转换成数字,然后由i进制转换成j进制
1010101111001101
hive (mydb)> select conv('FF',16,2);
11111111
hive (mydb)> select conv('ff',16,2); # 大小写不敏感
11111111
#abs(d) d DOUBLE return DOUBLE
hive (mydb)> select abs(-12.32);#求绝对值
12.32
hive (mydb)> select abs(11.23);
11.23
# pom(m,n) m,n INT return INT
hive (mydb)> select pmod(10,3); # pmod(m,n) = m % n 取模
1
hive (mydb)> select pmod(10,2);
0
hive (mydb)> select pmod(3.8,2); # 可以支持小数对整数的取模,甚至是小数对小数的取模
1.7999999999999998
hive (mydb)> select pmod(3.8,2.0);
1.7999999999999998
hive (mydb)> select pmod(3.8,1.9);
0.0
hive (mydb)> select pmod(3.8,1.8);
0.19999999999999973
#sin(d) d DOUBLE return DOUBLE
#cos(d) d DOUBLE return DOUBLE
#asin(d) d DOUBLE return DOUBLE
#acos(d) d DOUBLE return DOUBLE
#tan(d) d DOUBLE return DOUBLE
#atan(d) d DOUBLE return DOUBLE
#degrees(d) d DOUBLE return DOUBLE
#radians(d) d DOUBLE return DOUBLE
hive (mydb)> select sin(90); # sin(d) d表示弧度,不是角度 sin90度=1
0.8939966636005579
hive (mydb)> select sin(0);
0.0
hive (mydb)> select sin(180);
-0.8011526357338304
hive (mydb)> select sin(45);
0.8509035245341184
hive (mydb)> select sin(360);
0.9589157234143065
hive (mydb)> select cos(0);
1.0
hive (mydb)> select cos(90); # cos90度=0 cos(d) d 表示弧度
-0.4480736161291702
hive (mydb)> select sin(90);
0.8939966636005579
hive (mydb)> select cos(90);
-0.4480736161291702
hive (mydb)> select asin(0.5); # asin(d) d 为double类型 asin 和 sin 是逆运算,相当于乘法和除法一样
0.5235987755982989
hive (mydb)> select sin(0.5235987755982989);
0.5
hive (mydb)> select sin(asin(0.5));
0.5
hive (mydb)> select cos(acos(0.4)); #scos 和 cos 是逆运算。有些时候会出现些精度上的损耗,需要四舍五入
0.4000000000000001
hive (mydb)> select cos(acos(0.28));
0.28
hive (mydb)> select tan(20); #正切 tan(d) d 单位弧度
2.237160944224742
hive (mydb)> select tan(atan(20));#atan 和 tan 一对逆运算。同样有精度损失。
19.999999999999993
hive (mydb)> select atan(20);
1.5208379310729538
hive (mydb)> select tan(1.5208379310729538);
19.999999999999993
hive (mydb)> select degrees(1); # degrees(d) d为double类型,将弧度转换成角度
57.29577951308232
hive (mydb)> select sin(radians(30));# radians(d) 与 degrees(d) 逆运算
0.49999999999999994
hive (mydb)> select radians(30);
0.5235987755982988
hive (mydb)> select sin(0.5235987755982988); # sin30度=0.5
0.49999999999999994
hive (mydb)> select degrees(radians(30)); # 有精度上的损失
29.999999999999996
# positive(m) m INT 或者DOUBLE return INT DOUBLE。这个函数感觉没有什么用,输入INT/DOUBLE 类型的值,返回INT/DOUBLE 类型的值,输入什么返回什么。
hive (default)> select positive(9.20);
9.2
hive (default)> select positive(-9);
-9
hive (default)> select positive(-9.20);
-9.2
hive (default)> select positive(10);
10
hive (default)> select positive(10);
10
#negative(i) i DOUBLE/INT return DOUBLE/INT 返回-i,正数返回负数,负数返回正数
hive (default)> select negative(10);
-10
hive (default)> select negative(-10);
10
hive (default)> select negative(-9.55);
9.55
hive (default)> select negative(9.55);
-9.55
# sign(d) d DOUBLE return FLOAT 如果d 为正数(d>0) 返回1.0。如果d 为负数(d <0) 返回-1.0,否则返回0.0
hive (default)> select sign(3.13445);
1.0
hive (default)> select sign(-3.13445);
-1.0
hive (default)> select sign(0);
0.0
# e(),pi() 这两个函数没有参数 retrun DOUBLE
hive (default)> select e();
2.718281828459045
hive (default)> select pi();
3.1415926535897937、hive 算式运算符

# A / B
hive (default)> select (7 / 2);
3.5
hive (default)> select (7 / 3);
2.3333333333333335
#按位取与
hive (default)> select ( 55 & 50);
50
hive (default)> select conv(55,10,2);
110111
hive (default)> select conv(50,10,2);
110010
# 按位异或。异或是相同为0,不同为1
hive (default)> select ( 55 ^ 50);
5
hive (default)> select conv(50,10,2);
110010
hive (default)> select conv(55,10,2);
110111
# 按位取反。不知道怎么计算的,~a = -(a + 1)
hive (default)> select (~ 55);
-56
hive (default)> select (~ 50);
-51
hive (default)> select (~ 35);
-36
hive (default)> select (~ 26);
-27
hive (default)> select (~ (-26));
25
hive (default)> select (~ (-2));
1
hive (default)> select (~ (-45));
44
hive (default)> select (~ (-45.12)); # 不能是小数
FAILED: SemanticException [Error 10014]: Line 1:12 Wrong arguments '45.12': No matching method for class org.apache.hadoop.hive.ql.udf.UDFOPBitNot with (double). Possible choices: _FUNC_(bigint) _FUNC_(int) _FUNC_(smallint) _FUNC_(tinyint)
hive (default)> select (~ (-35));
348、hive 聚合函数
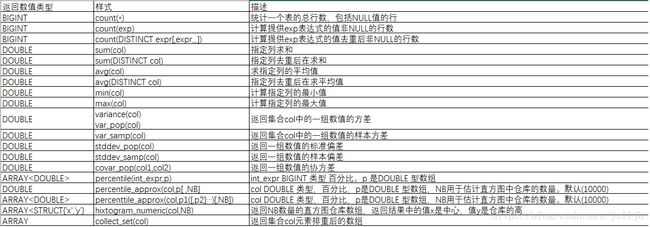
使用聚合函数设置hive.map.aggr 为true,可以提高聚合函数的性能
set hive.map.attr=ture
这个设置会增加内存的使用率
# 这个例子中,设置了hive.map.attr=true 会触发在map阶段进行的"顶级"聚合过程。(非顶级的聚合过程会在执行一个GROUP BY后进行)
hive (default)> SELECT COUNT(*),AVG(salary) FROM employees;
7 102857.14285714286
# 可以使用多次 DISTINCT() 函数
hive (default)> SELECT COUNT(DISTINCT ymd),COUNT(DISTINCT volume) FROM stocks;
741 976799、查询hive内嵌的函数
hive -S -e 'show functions' | grep FUNCTION_NAME
#显示某个具体函数的帮助信息
hive -S -e 'desc function extended FUNCTION_NAME'
例如:hex()
hive -S -e 'desc function extended hex'
hex(n, bin, or str) - Convert the argument to hexadecimal
If the argument is a string, returns two hex digits for each character in the string.
If the argument is a number or binary, returns the hexadecimal representation.
Example:
> SELECT hex(17) FROM src LIMIT 1;
'H1'
> SELECT hex('Facebook') FROM src LIMIT 1;
'46616365626F6F6B'10、表生成函数:将单列扩展成多列,或者多行,与聚合函数相反
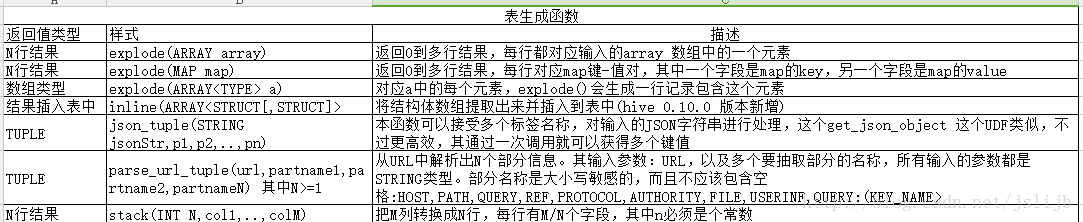
hive (default)> SELECT explode(subordinates) AS sub FROM employees;
Mary Smith
Todd Jones
Bill King
John Doe
Fred Finance
Stacy Accountant
hive (default)> SELECT subordinates FROM employees;
["Mary Smith","Todd Jones"]
["Bill King"]
[]
[]
["John Doe","Fred Finance"]
["Stacy Accountant"]
[]
# subordinates 字段为空的话,那么不会产生行的记录(一行),如果不为空的话,那么这个数组的每一个元素都将产生一行新的记录
# AS sub 定义列别名,也可以不用定义,看个人需求11、hive 内置函数
ascii(‘abc’) 返回’abc’这个字符串中首字符’a’对应的ASCII码
hive (default)> select ascii('abc');
97
hive (default)> select ascii('123');
49
hive (default)> select ascii('1abc');
49
hive (default)> select ascii(',abc');
44bade64(b) 函数,b是binary类型,将b转换为基于64位的字符串
# unhex() 函数返回binary类型,这个类型貌似不能用键盘输入
hive (default)> select unhex("234");
4
hive (default)> select base64(unhex("234"));
AjQ=binary() 函数将输入转换成2进制值
hive (default)> select binary('abc');
abc
hive (default)> select base64(binary('abc'));
YWJjcast(expr,type) expr 是hive任意的数据类型,type是要转换的数据类型
hive (default)> select cast('abc' as INT);
NULL
hive (default)> select cast('123' as INT);
123
hive (default)> select cast('123' as FLOAT);
123.0concat() concat_ws() 拼接字符串,可以拼接STRING 类型的字符串,也可以拼接BINARY 类型的字符串
#将2进制字节码按照输入的顺序拼接成一个字符串,返回STRING 类型
hive (default)> select concat(binary('abc'),binary('cdr'),binary('erf'));
abccdrerf
# 所拼接的字符串类型可以不相同
hive (default)> select concat(binary('abc'),binary('cdr'),binary('erf'),'abc');
abccdrerfabc
hive (default)> select concat('abc','edf','ghj');
abcedfghj
# concat_ws() 需要指定连接字符串
hive (default)> select concat_ws('-','abc','edf','ghj');
abc-edf-ghj
# hive 1.2.2 concat_ws() 不支持二进制类型
encode(BINARY bin,STRING charset) 和 decode(STRING str,STRING charset) 这两个函数想反,相当于+和-这两个操作
支持的字符集:US_ASCII,ISO-8859-1,UTF-8,UTF-16BE,UTF-16LE,UTF-16
hive (default)> select decode(binary('abc'),'utf-8');
abc
hive (default)> select decode(binary('98ecf'),'ISO-8859-1');
98ecf
hive (default)> select decode(binary('#@1abv'),'UTF-16');
⍀ㅡ扶
hive (default)> select encode('#13lad','utf-16be');
#13lad
hive (default)> select encode('#13lad','ISO-8859-1');
#13ladfind_in_set(str,str_array) str:STRING,str_array:包含”,”的字符串,当然也可以不包含”,”的字符串。在str_array以逗号分隔的字符串中查找str出现的位置
hive (default)> select find_in_set('ab','abc,de,erg,ab,ef');
4
hive (default)> select find_in_set('ab','abcdeerg-abef');
0
# 不包含","的字符串,返回0
hive (default)> select find_in_set('ab','ab-cde-erg-ab-ef');
0
hive (default)> select find_in_set('ab','ab,cde-erg-ab-ef');
1format_number(num,d) num:NUMBER,d:INT。将num格式化”#,###,###.##”.d 表示小数的位数,如果为0表示没有小数
# 四舍五入
hive (default)> select format_number(123456.49,0);
123,456
hive (default)> select format_number(123456.59,0);
123,457
hive (default)> select format_number(123456.5945687,5);
123,456.59457s in (val1,val2,val3,….) s:任意类型,val:任意类型。s和val任一个相同就可以了。
# 123,‘123’ 相同
hive (default)> select '123' in ('123','abc','456',456);
hive (default)> select '123' in (123,'abc','edf');
true
hive (default)> select 123 in (123,'abc','edf');
true
hive (default)> select 123 in ('123','abc','edf');
hive (default)> select 'abcd' in ('123',231,'abcde');
falseget_json_object(json_string,path) json_string:STRING,path:STRING。json_string json 类型的字符串,path路径
从给定路径上的JSON字符串中抽取出JSON对象,并返回这个对象的JSON字符串形式。如果输入的JSON字符串是非法的,在返回NULL,如果没有匹配到也会返回NULL
select get_json_object(
'{
"stroe":
{
"fruit":
[
{"weight":8,"type":"apple"},
{"weight":9,"type":"pear"}
],
"bicycle":{"price":19.951,"color":"red1"}
},
"email":"amy@only_for_json_udf_test.net","owner":"amy1"
}',
'$.owner1'
);
# 输出:
amy1in_file(s,filename) s:STRING,filename:STRING。filename 文件的路径(最好是绝对路径)。s字符串和filename文件中某一行完全匹配,返回true否则false
# cat /root/hive.txt
hello hive!
hive is hadoop tools
hive (default)> select in_file("Hello hive!",'/root/hive.txt');
false
hive (default)> select in_file("hello hive!",'/root/hive.txt');
trueinstr(s,sub) s:STRING,sub:STRING return INT。
在s中搜索sub子串,返回第一次出现的位置,索引从1开始
hive (default)> select instr('adasdfhabchksdkfabcdsrabcdsd','abc');
8
hive (default)> select instr('efgabcdeabcdesrabcde','abc');
4
hive (default)> select instr('efgabcdeabcdesrabcde','abd');
0lower(s) lcase(s) s:STRING。return STRING。将s中大写转换成小写。小写直接输出
upper(STRING s)
ucase(STRING s)
小写转换成大写
hive (default)> select lower('abcd');
abcd
hive (default)> select lower('Abcd');
abcd
hive (default)> select lower('Ab12Cd');
ab12cd
hive (default)> select lcase('123AvcDerR');
123avcderr
hive (default)> select lcase('123abdser');
123abdser
hive (default)> select upper('abcdDER');
ABCDDER
hive (default)> select ucase('abcdDER');
ABCDDERlength(s) s:STRING,返回INT。计算字符串s的长度
hive (default)> select length('abcdser');
7locate(substr,str[,pos]) substr:STRING,str:STRING,pos:INT。return INT。在字符串str中从pos位置(包含pos)开始查找substr,返回第一次出现的位置,索引从1开始
hive (default)> select locate('abc','defsdabcsfsdfabc',7);
14
hive (default)> select locate('abc','defsdabcsfsdfabc');
6
hive (default)> select locate('bar','foobarbar');
4
hive (default)> select locate('bar','foobarbar',5);
7lpad(s,len,pad) s:STRING,len:INT,pad:STRING.从左边开始对字符串pad进行填充,最终达到len的长度为止,如果s的长度大于len将舍弃多余的部分
rpad(STRING s,INT len,STRING pad)
hive (default)> select lpad('abc',10,'-');
-------abc
hive (default)> select lpad('abcerfsafgsdf',5,'-');
abcer
hive (default)> select rpad('abcd',20,'*');
abcd****************ltrim(s) 如果s最左边有空格,将最左边的空格删除,返回STRING
hive (default)> select ltrim(' hive ');
hive
#验证只删除了左边的空格,没有删除右边的空格
# a=hive -S -e "select ltrim(' hive ')"
# echo ${#a} 输出7
# echo $a 输出 a
hive (default)> select ltrim(' hive ad');
hive ad
hive (default)> select ltrim('adr hive ad');
adr hive ad
# 删除又不的空格,如果左边有空格保留
hive (default)> select rtrim(' abcd ');
abcd
#删除前后的空格
hive (default)> select trim(' hive ');
hiveparse_url(url,partname[,key]) url:STRING,partname:STRING,key:STRING
这个函数的功能是解析url。partname表示要抽取部分(区分大小写):HOST,PATH,QUERY,REF,PROTOCOL,AUTHORITY,FILE,USERINFO,QUERY:
hive (default)> SELECT parse_url('http://facebook.com/path/p1.php?query=1', 'HOST');
facebook.com
hive (default)> SELECT parse_url('http://facebook.com/path/p1.php?query=1', 'PATH');
/path/p1.php
hive (default)> SELECT parse_url('http://facebook.com/path/p1.php?query=1', 'PROTOCOL');
http
hive (default)> SELECT parse_url('http://facebook.com/path/p1.php?query=1', 'FILE');
/path/p1.php?query=1
# HOST AUTHORITY 这两个参数输出内容相同
hive (default)> SELECT parse_url('https://baike.baidu.com/item/url/110640?fr=aladdin', 'AUTHORITY');
baike.baidu.com
hive (default)> SELECT parse_url('https://baike.baidu.com/item/url/110640?fr=aladdin', 'HOST');
baike.baidu.com
hive (default)> SELECT parse_url('https://baike.baidu.com/item/url/110640?fr=aladdin#abcde', 'ref');
NULL
hive (default)> SELECT parse_url('https://baike.baidu.com/item/url/110640?fr=aladdin#abcde', 'REF');
abcde
hive (default)> SELECT parse_url('http://facebook.com/path/p1.php?query=2', 'QUERY', 'query');
2printf(format,Obj…args) 安装printf格式化输出字符串。format:STRING
hive (default)> SELECT printf("Hello World %d %s", 100, "days");
Hello World 100 days
hive (default)> SELECT printf("Hello World %d\n%s", 100, "days");
Hello World 100
daysregexp_extract(STRING subject,STRING regex_pattern,INT index)
subject 字符串
regex_pattern 匹配模式,可以有多个模式
index:表示输出第几个模式,从1开始
# \d 匹配一位数字:0-9,但是\ 需要转义,否则无法匹配成功
hive (default)> SELECT regexp_extract('abc-456', '^([a-z]+)-(\\d)',1);
abc
hive (default)> SELECT regexp_extract('abc-456', '^([a-z]+)-(\\d+)',2);
456
hive (default)> select regexp_extract('foothebar', 'foo(.*?)(bar)', 2);
bar
hive (default)> select regexp_extract('foothebar', 'foo(.*?)(bar)', 1);
theregexp_replace(STRING s,STRING regex,STRING replacement)
s::字符串
regex:java 正则表达式
replacement:一个字符串,将匹配到的字符串使用这个字符串替换,如果为空,表示去掉匹配到的字符串。这个参数即使为空也需要给定否则报语法错误
hive (default)> select regexp_replace("foobar", "oo|ar", "");
fb
hive (default)> select regexp_replace("foobar", "oo|ar", "a");
faba
hive (default)> select regexp_replace("foobar", "oo|ar", "abcd");
fabcdbabcd
# 同样 \ 需要转义
hive (default)> select regexp_replace("foobarii33", "oo|ar|\\d+","aa");
faabaaiiaarepeat(STRING s,INT n)
将字符串s重复n次
hive (default)> select repeat('abc',3);
abcabcabc
hive (default)> select repeat('123',3);
123123123
hive (default)> select repeat('abc123def',3);
abc123defabc123defabc123defreverse(STRING s)
将s逆序输出
hive (default)> select reverse('abc');
cba
hive (default)> select reverse('abcerfg');
gfrecbasentences(STRING s,STRING lang,STRING locale)
lang:语言环境
locale:地区,定义字符集
返回字符串数组
hive (default)> SELECT sentences('Hello there! I am a UDF.');
[["Hello","there"],["I","am","a","UDF"]]
hive (default)> SELECT sentences('Hello there I am a UDF.');
[["Hello","there","I","am","a","UDF"]]
hive (default)> SELECT sentences('Hello there.I am a UDF.');
[["Hello","there.I","am","a","UDF"]]
hive (default)> SELECT sentences('Hello there . I am a UDF.');
[["Hello","there"],["I","am","a","UDF"]]# deductions map 类型,查询有多少个键值对
hive (default)> select size(deductions) from employees;
3
3
3
3
3
3
3
hive (default)> select deductions from employees;
{"Federal Taxes":0.2,"State Taxes":0.05,"Insurance":0.1}
{"Federal Taxes":0.2,"State Taxes":0.05,"Insurance":0.1}
{"Federal Taxes":0.15,"State Taxes":0.03,"Insurance":0.1}
{"Federal Taxes":0.15,"State Taxes":0.03,"Insurance":0.1}
{"Federal Taxes":0.3,"State Taxes":0.07,"Insurance":0.05}
{"Federal Taxes":0.3,"State Taxes":0.07,"Insurance":0.05}
{"Federal Taxes":0.15,"State Taxes":0.03,"Insurance":0.1}
# subordinates array 类型,查询元素的个数
hive (default)> select size(subordinates) from employees;
2
1
0
0
2
1
0
hive (default)> select subordinates from employees;
["Mary Smith","Todd Jones"]
["Bill King"]
[]
[]
["John Doe","Fred Finance"]
["Stacy Accountant"]
[]space(INT n) 返回n个空格
split(STRING s,STRING pattern)
对字符串s使用pattern进行分割,返回一个字符串数组
hive (default)> select split('abc edf ert','[ ]');
["abc","edf","ert"]
hive (default)> SELECT split('oneAtwoBthreeC', '[ABC]');
["one","two","three",""]
hive (default)> select split('abc edf ert','');
["a","b","c"," ","e","d","f"," ","e","r","t",""]
hive (default)> select split('abc edf ert',' ');
["abc","edf","ert"]str_to_map(STRING s[,STRING delim1,STRING delim2])
delim1:键值对的分隔符,默认值是逗号分隔符(“,”)
delim2:键和值之间的分隔符,默认值是冒号分隔符(“:”)
return MAP
hive (default)> select str_to_map('abc-cde,erf-avd',',','-');
{"abc":"cde","erf":"avd"}
hive (default)> select str_to_map('abc:cde,erf:avd');
{"abc":"cde","erf":"avd"}
hive (default)> select str_to_map('abcder','=','-');
{"abcder":null}
hive (default)> select str_to_map('abrefcoiriocqeriq','c','r');
{"ab":"ef","qe":"iq","oi":"io"}substr(STRING s,INT start_index,INT len)
substring(STRING s,INT start_index,INT len)
从start_index (包含)位置开始截取长度为len个字符串
hive (default)> select substr('abcde',3,2);
cd
hive (default)> select substring('abcde',3,2);
cd
# 可以截取二进制类型的字符串
hive (default)> select substr(binary('abcdergh'),3,4);
cder
hive (default)> select substring(binary('abcdergh'),3,4);
cdertranslate(STRING s, STRING input,STRING from)
input 和 from 长度相等,两者对应在原字符串中查找input包含的字符使用from中对应位置的字符替换
input 的长度大于 from,两者对应在原字符串中查找input包含的字符使用from中对应位置的字符替换,在原字符串中查找input 中多余的字符,将其删除
input 长度小于from,两者对应在原字符串中查找input包含的字符使用from中对应位置的字符替换。from多余的字符忽略
# 将原字符串中a 替换成1,d替换成9,删除c
hive (default)> select translate('abcdef', 'adc', '19')
1b9ef
hive (default)> select translate('abcdef', 'ad', '19');
1bc9ef
hive (default)> select translate('abcdef', 'adc', '193');
1b39ef
# 4 多余的忽略掉
hive (default)> select translate('abcdef', 'adc', '1934');
1b39ef
hive (default)> select translate('a b c d', ' ', '');
abcd
# 将原字符串中"a" 替换成 1,将"d" 替换成 9,将"c" 替换成 3
hive (default)> select translate('abcdefsdfaerdsfdc', 'adc', '193');
1b39efs9f1er9sf93unbase64(STRING str) 将基于64位的字符串str 转换成二进制值
hive (default)> select unbase64('abcd');
i�from_unixtime(BIGINT,unixtime[,STRING format])
将unix 时间戳转换成字符串,可以使用format格式化
hive (default)> SELECT FROM_UNIXTIME(1520584960,'yy-MM-dd HH:mm:ss');
18-03-09 08:42:40
hive (default)> SELECT FROM_UNIXTIME(1520584960,'yyyy-MM-dd HH:mm:ss');
2018-03-09 08:42:40
hive (default)> SELECT FROM_UNIXTIME(1520584960,'HH:mm:ss');
08:42:40
hive (default)> SELECT FROM_UNIXTIME(1520584960);
2018-03-09 08:42:40unix_timestamp() 获取本地区当前时间戳
hive (default)> select unix_timestamp();
1520585915unix_timestamp(STRING s)
s:必须包含年月日,时分秒,格式”yyyy-MM-dd HH:mm:ss”
hive (default)> select unix_timestamp("2018-2-3");
NULL
hive (default)> select unix_timestamp("2018-2-3 12:20:11");
1517660411
hive (default)> select unix_timestamp("18-2-3 12:20:11");
-61596416389
hive (default)> select unix_timestamp("2018-2-3 12:20:11");
1517660411
hive (default)> select unix_timestamp("2018-2-3 12:20");
NULLhive (default)> select unix_timestamp("2018-3-20",'yyyy-MM-dd');
1521504000
hive (default)> select unix_timestamp("12:39:00",'HH:mm:ss');
45540
hive (default)> select unix_timestamp("01:00:00",'HH:mm:ss');
3600
hive (default)> select unix_timestamp("2018-3-20",'HH:mm:ss');
NULLhive (default)> select to_date('2018-02-31');
2018-03-03
hive (default)> select to_date('2018-02-30');
2018-03-02
hive (default)> select to_date('2018-02-29');
2018-03-01
hive (default)> select to_date('2018-02-28');
2018-02-28
hive (default)> select to_date('2018-3-3');
2018-03-03year(STRING date) return INT
month(STRING date) return INT
day(STRING date) return INT
date 格式:’yyyy-MM-dd HH:mm:ss’ or ‘yyyy-MM-dd’
hive (default)> select year("2017-03-32");
2017
hive (default)> select year("2018-1-2 1:1:00");
2018hive (default)> select month("2018-1-2 1:1:00");
1
hive (default)> select month("2018-05-06 1:1:00");
5
# day > 31 month自增 month > 12 year 自增
hive (default)> select month("2018-6-40 1:1:00");
7
hive (default)> select year("2018-16-40 1:1:00");
2019
# 2月份比较特殊
hive (default)> select day("2018-02-31 1:1:00"),month("2018-02-31 1:1:00");
3 3
hive (default)> select day("2018-02-29 1:1:00"),month("2018-02-29 1:1:00");
1 3
# 6 月没有31
hive (default)> select day("2018-06-31 1:1:00"),month("2018-06-31 1:1:00");
1 7hour(STRING date) return INT
minute(STRING date) return INT
second(STRING date) return INT
date 格式:’yyyy-MM-dd HH:mm:ss’ or ‘HH:mm:ss’.
hive (default)> select hour("2018-02-23 20:10:00");
20
hive (default)> select hour("11:10:00");
11
hive (default)> select hour("2018-02-23 25:10:00"),day("2018-02-23 25:10:00");
1 23
# second 缝60进1,minute 缝60进1,hour缝24进1,second 进1给minute,minute进1给hour,但hour进1不会使day增加,即使是23:59:59 进1,day也会加1
hive (default)> select day("2017-12-31 23:59:1000000000000000000000"),month("2017-12-31 23:59:1000000000000000"),year("2017-12-31 23:59:10000000000");
31 12 2017
hive (default)> select hour("2017-12-31 23:59:60"),minute("2017-12-31 23:59:60"),second("2017-12-31 23:59:60");
0 0 0
hive (default)> select year("2017-12-31 23:59:60"),month("2017-12-31 23:59:60"),day("2017-12-31 23:59:60"),hour("2017-12-31 23:59:60"),minute("2017-12-31 23:59:60"),second("2017-12-31 23:59:60");
2017 12 31 0 0 0
# day 缝28/30/31 进1给month,month 缝12 进1,给year
hive (default)> select year("2018-12-32"),month("2018-12-32"),day("2018-12-32");
2019 1 1weekofyear(STRING date) return INT
给出的日期是这一年的第几周
hive (default)> select weekofyear("2018-1-7");
1
hive (default)> select weekofyear("2018-1-8");
2
# day 不变,周也会变
hive (default)> select weekofyear("2018-1-7 23:59:61");
1datediff(STRING end_date,STRING start_date)
两个日期之间相隔多少天数。大日期在前面,小日期在后面
hive (default)> select datediff('2018-10-12','2018-10-20');
-8
hive (default)> select datediff('2018-10-01','2018-03-12');
203
hive (default)> select datediff('2018-10-01','2018-03-12 23:61:00');
203date_add(STRING date,INT days)
给定日期增加的天数,不含给定日期的
hive (default)> select date_add("2018-03-12",30);
2018-04-11
hive (default)> select date_add("2018-03-12",349);
2019-02-24date_sub(STRING date,INT days)
给定日期减少days天
hive (default)> select date_sub("2018-03-12",2);
2018-03-10from_utc_timestamp(STRING utc,STRING timezone)
utc 格式:’yyyy-MM-dd HH:mm:SS’
将utc 时间转换成指定时区的时间
to_utc_timestamp(timestamp,STRING timezone)
# 感觉是hive的bug,相差时间不一致
hive (default)> select from_utc_timestamp('2018-03-11 08:00:00','CST');
2018-03-11 03:00:00
hive (default)> select from_utc_timestamp('2018-03-12 08:00:00','CST');
2018-03-12 03:00:00
hive (default)> select from_utc_timestamp('2018-01-01 08:00:00','CST');
2018-01-01 02:00:00
hive (default)> select from_utc_timestamp('2018-03-01 08:00:00','CST');
2018-03-01 02:00:00
# 一会相差5个小时,一会有相差6个小时
hive (default)> select to_utc_timestamp('2018-03-12 08:00:00','CST');
2018-03-12 13:00:00
hive (default)> select to_utc_timestamp('2018-01-01 08:00:00','CST');
2018-01-01 14:00:00