读书笔记:GCN—GAT—RGAT—CNNGAT
文章目录
- 前言
- 图神经网络
- GCN——图卷积神经网络
- GAT (图注意力神经网络)
- RGAT
- CNNGAT
前言
由于笔者最近对图神经网络感兴趣,因此粗略地看了一下这几年关于图神经网络的论文,在此写一下自己的理解,由于笔者水平有限,大家在阅读时尽可能保持一种互相学习的态度,有问题可以及时私信我,想一起交流学习的也可以加我,笔者邮箱:[email protected]
图神经网络
众所周知,当下深度学习已经取得了一定的成就,不管是在计算机视觉、语音识别、预测、自然语言处理等等都已经取得了很大的进步,而深度学习的代表网络恐怕也就是CNN、RNN、GAN,这三者以及其三者的变形应该占据了相当大的比重,当然,还有比较小众的DBN(深度置信网络),基于玻尔兹曼机(RBM),不适用反向传播,这一奇妙的神经网络也因为其复杂性而导致使用的人比较少(笔者之前也试图学习,无奈资源比较少,没有合适的教程也就搁置了),对了,还有一个很好的工具,DRL(深度强化学习),当下DRL也是研究的一大热点,当下已经在很多领域有了突破,前几年大热的AlphaGo,也是因为有着强化学习的算法可以在对战中进行学习,摆脱了之前人们硬性输入资料的形式,能够主动去学,也更像人工智能,因此,笔者相信,在将来,DRL一定有更大的突破和更广的应用。
现在,我们再来说一说文章的主角“图神经网络”,首先,它为何被提出?我们先来看传统的CNN,CNN处理的是图像,准确的说是矩阵,矩阵的特点就是方方正正,也就是论文中提到的Euclidean Structure,那么如果处理的数据不是这种矩阵格式,而是一种图的格式呢,比如社交网络,比如数据结构中常提到的旅行商问题,CNN可以去处理吗?答案当然是不行,而这种数据恰恰是真实世界中常常出现的,因此,图神经网络就此诞生了。那么,图神经网络和传统的CNN有什么区别呢,图神经网络所基于的数据结构便是图,用到的知识很多也是基于图论中的,整个图神经网络的构建也类似于图的构建,每个神经元类似于图中的顶点v,每两个神经元之间的连接类似于图中的边e,如果拿图像来对比,每个像素点可以当作每个顶点,而每两个像素点之间的连接(可以取每个像素8邻域或者取全像素)可以当作每条边,而在实验中,人们常常用的是图数据,常见的如cora,citeseer,pubmed,都是直接给出了图神经网络训练时所需要的数据。
那么,接下来,让我们一起去领略一下图神经网络的发展以及惊人之处。
GCN——图卷积神经网络
论文地址:https://arxiv.org/abs/1609.02907
github源码:https://github.com/tkipf/gcn
首先,说到图神经网络的发展,不得不提到GCN,人们常提到的论文即《SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS 》,使用GCN进行半监督学习,(笔者不清楚是否在这篇paper提出之前有无GCN的提出,笔者也是在查阅资料后看到大家都推荐这篇paper,在拜读后也是受益匪浅,因此在这就以此为基)
这里提到的是GCN,图卷积神经网络,顾名思义,图卷积,即要对图进行卷积,然后paper 的作者便用数学公式来不断的推算,通过各种变换得到最终图卷积的表达式,如下:
![]()
这里笔者对公式的推导就不详解了,主要是用到了拉普拉斯矩阵的谱分解,傅里叶变换等等,推算公式也不是笔者能明明白白介绍清楚的,而且已经有大牛解析得很透彻了,在文章的最后会放他们的链接,有兴趣的可以自己去看一下~
这里,我们主要讲一下这个公式。首先~A=A+I,A是图的邻接矩阵,I是图的单位矩阵,A本身包含的是图中每个点相邻顶点的连接信息,而加上I之后, ~A就包含包括自身顶点的信息,也就在接下来的运算操作中运用的信息来自自身以及其相邻顶点的, ~A也被成为具有强制自环的邻接矩阵。再来看 ~D, ~D是顶点的度矩阵,也成为对角矩阵,对角线上元素分别为每个顶点的度,其余为0.而W则是可以训练的权重矩阵,H0为输入的特征矩阵(加上自身的,经过一次卷积操作,会输出卷积后的特征矩阵,进行接下来的操作。在原paper中,构建了两层的图卷积网络,也就是输入一个特征矩阵H0,进行一次图卷积操作,使用激活函数α(这里用的是relu),得到输出的特征矩阵H1,然后再进行一次图卷积操作,使用激活函数(这里用的是softmax),得到每个顶点对应多分类的概率,然后再进行反向传播,不断迭代运算。
这里再说一下这里的半监督学习流程是如何进行的。我们以Cora数据集为例,Cora数据集是由机器学习论文组成,论文分为七类,整个语料库中有2708篇论文,每一篇论文对应1433个独特的单词。这里将数据的feature[2708:1433]作为H0输入,然后将权重矩阵W随机初始化,原文代码中也可以选择是否添加了偏置Bias(在每一次卷积输出后加上偏置),相应的,~A和 ~D也就可以相应的求出,然后经过一次卷积并经relu激活后,输出H1,再进行第二次卷积,经softmax分类器分类(这里两层的W权重是不共享的),得到输出Z。
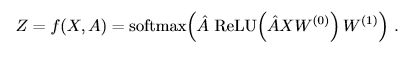
然后求损失函数。首先注意这里我们并不是给所有的顶点都给label,而是选择部分顶点,原文中是每一类论文选取20个设为有标注,也就是共有20×7=140个顶点是有label的。所以2708个顶点中仅有140个顶点有label,然后通过图寻找各个顶点之间的关系,以此推出其他顶点的label。
![]()
然后针对每一个有label 的顶点,求交叉熵作为损失函数,下面公式的yL指的是有label 的顶点。然后不断进行反向传播,迭代。

就此,整个GCN也就搭建好了,所以个人理解这篇论文的要点主要在于1)提出图卷积的方法2)通过图卷积进行半监督学习,当然学习这篇论文主要还是学习图卷积的思想。
GAT (图注意力神经网络)
论文地址:http://arxiv.org/abs/1710.10903
github源码:https://github.com/PetarV-/GAT
介绍完GCN,我们再来看GAT(Graph Attention Networks)。相比于GCN,GAT提出了一种新的方法来对图神经网络进行处理,当然,这里新的方法也是已经在CNN、RNN中展现风采的注意力机制。

简单理解,对于每一个顶点,我们取它的一些邻居(比如直接相邻的顶点),然后每一个邻居都会对该顶点产生一定的影响力,每个影响力的影响效果不同,然后通过算法得出该顶点的新的feature。
然后,我们来看一下里面的Graph Attention Layer。
该层也是GAT的核心之处。该层的输入是一堆顶点特征h,输出是一堆新的顶点特征h’。首先,为了能从获得足够的表达能力把输入特征转化为更高一层的特征,至少需要一个可学习的线性变换。因此,这里需要一个权重矩阵W,应用于每一个顶点,然后,对顶点应用self-attention,用注意力机制a求得注意力系数,也就是j顶点的特征对i顶点的重要性。
![]()

一般来说,这个模型可以允许一个每个顶点对所有的顶点都有一定的注意力影响,在这篇论文中,仅计算与每一个顶点直接相连的顶点(包含自身),然后对结果正则化通过softmax求得每个顶点的邻居对该顶点的影响力分布。

在论文实验中,对每个对每个影响力先经过LeakyRelu(α=0.2)进行一次非线性映射,然后再用softmax求得影响力分布。

一但获得之后,这些正则化注意力系数被用来计算特征的线性组合(对于每个顶点),以此作为输出对每个顶点。
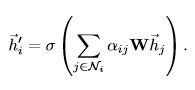
此外,论文还提出了multi-head attention的方式,这里和Vaswani在2017年的paper《Attention Is All You Need 》类似,这里笔者也没有仔细研究,因此有兴趣的可以去看看这篇论文。
论文地址:https://arxiv.org/abs/1706.03762

基本上到这里,GAT的核心也就介绍完了。可以看出,GAT的思想主要在于不断对其相邻顶点的特征进行提取、利用、转化,最终通过不同的权重、不同的注意力系数将其他顶点的feature组合在一起,进而得到输出的feature。因此,可以看出,GAT和GCN是两种不同的处理方式,但是在原理上两者都可以说用了其相邻顶点的信息,也就是图的特点。
接下来,再让我们一起来看看2019年新出炉的关于图神经网络的paper。
RGAT
由于笔者还没来得及看RGAT,所以在这里先介绍一下CNNGAT,等看过RGAT之后再补上缺失的内容。
论文地址:https://arxiv.org/abs/1904.05811
CNNGAT
论文地址:https://arxiv.org/abs/1905.03036
首先,为何这篇paper被提出?回顾一下上面的论文,无论是GCN还是GAT,都有一个问题,就是输入的feature是固定的,而如果针对图像问题,如果是用预处理提取的feature进行训练,结果会直接受到提取出来的feature影响,一旦feature有问题,整个网络的准确性也会受到很大的干扰,因此,这篇论文将CNN和GAT结合在一起,将提取特征和图注意力模型相结合,使其在学习时能够主动学习通过CNN提取出来的feature,并将CNN提取出来的结果经过Graph Attention layer层处理,将其GAT层输出与CNN输出结合、连接,得到的结果再经处理得到分类结果。也就是说,CNNGAT是一种端到端的模型。

上图摘自原文,为整个网络架构的示意图。
整个网络大致可以分为四个模块。
首先,将M张图片以及N张相邻图片,因为这篇论文是用来做疾病分类的,所以相邻无论是M还是N,都是疾病相关的,然后将这些图片一起放入一个CNN网络中,最终得到一张(M+N)×128维的feature map。
然后,将CNN得到的feature放入GAT网络中,和上文提到的GAT一样,输入一个feature,然后经过图注意力层之后得到一个新的feature。这里的一个关键便是如何对每一个顶点,确定其“邻居”包含哪些顶点。
论文中提到,尽管可以假设所有的顶点都是其“邻居”,但是在实验中,先设定一个“邻居”数量N,对于每一个顶点vi,如果其他顶点vj和该顶点vi有边相连,那么就把顶点vj作为一个“邻居”,如果按这方法得到的“邻居”数量不足N个,那么再随机抽取,直到数量满足N个的要求。

接下来,从网络结构图可以看到,CNN提取之后的feature map有一个跳跃层,将M张图片的feature map提取出来卷积(使用LeakyRelu激活)后变为M×32维的,同时,经GAT层处理后输出的结果也是M×32维的,然后,将两者连接起来,这里连接方式笔者还不是很清楚,因为还没有源码,但是推断应该和unet那种连接类似,是将通道数叠加,因为连接后的结果是M×64维的。
最后,将M×64维矩阵再经卷积、softmax分类后,得到结果,将得到的label’与目标label求交叉熵,再反向传播,迭代,循环。
综上,可以看出,CNNGAT并没有提出关于图神经网络处理的新的算法,而是将CNN和GAT结合在一起,使其可以端到端的处理图像分类,可以让网络自适应学习特征,反向传播贯穿整个网络,不仅仅是图神经网络可以权值更新,CNN也可以梯度下降,所以,图神经网络的应用更“人性化”了,从这也可以看出,图神经网络也朝着应用的方向发展,在一开始,笔者刚接触图神经网络的时候,对整个网络也是很不理解,不清楚他在做些什么,因为在开始的paper中使用的数据都是直接用的 graph-structured data,也不清楚网络是在做些什么,加上之前接触的都是CNN、GAN等比较容易理解的网络,在看了一段时间之后对其才开始有了感觉,想写这篇博文来巩固一下并且给有需要的人一些帮助,也欢迎大家和我一起讨论这方面,相信在这个方向未来前景一定是广阔的。