使用hive脚本一键动态分区、分区又分桶以及脚本步骤详细详解(亲测成功)
一、动态分区以及从linux本地文件映射到hive表中。
partitioned.sql脚本中的创造数据:
mkdir /mytemp
cd mytemp
vi stu_score.txt1,zhangshan,50,1
2,lisi,67,1
3,tom,49,2
4,jery,48,2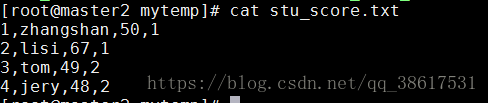
hive脚本内容如下------partitioned.sql
set mapreduce.framework.name=local;
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
use test;
drop table if exists stu_score;
create table if not exists stu_score(id int,name string,score int,status int) partitioned by (dt string) row format delimited fields terminated by ',';
load data local inpath '/mytemp/stu_score.txt' into table stu_score partition (dt='2018-10-18');
load data local inpath '/mytemp/stu_score.txt' into table stu_score partition (dt='2018-10-19');
dfs -cat /user/hive/warehouse/test.db/stu_score/dt=2018-10-18/stu_score.txt;
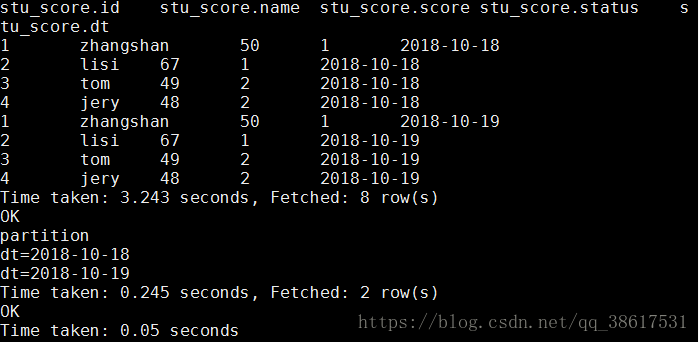
select * from stu_score;
show partitions stu_score;
create table if not exists stu_score_tmp(id int,name string,score int,status int) row format delimited fields terminated by ',';
load data local inpath '/mytemp/stu_score.txt' into table stu_score_tmp;
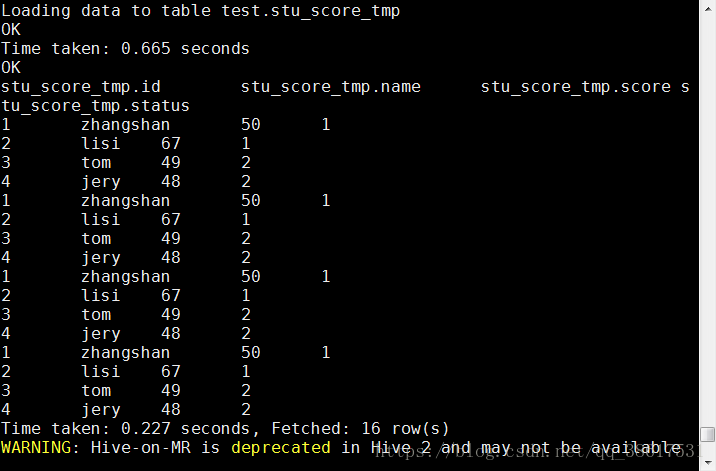
select * from stu_score_tmp;
insert into stu_score partition(dt) select id,name, score,status,'2018-10-28' from stu_score_tmp;
drop table if exists stu_score_tmp;
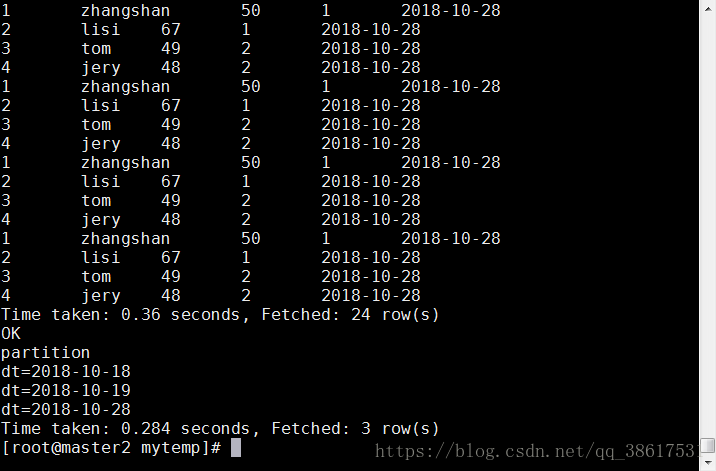
select * from stu_score;
show partitions stu_score;hive脚本内容详细解析如下
set mapreduce.framework.name=local;
-- 将mapreduce设置为本地运行,节省时间
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
---设置hive的动态分区参数设置
use test;
--使用test数据库,为了将表格创建在test数据库下(如果没有可以改变成自己的数据库)
drop table if exists stu_score;
--为了保证不存在目标表
create table if not exists stu_score(id int,name string,score int,status int) partitioned by (dt string) row format delimited fields terminated by ',';
创建表名为stu_score ,字段及类型:id int,name string,score int,status int
partitioned by (dt string):表示通过dt进行分区
terminated by ',':表示将文本文件中的数据通过表格分割映射到创建的表中
load data local inpath '/mytemp/stu_score.txt' into table stu_score partition (dt='2018-10-18');
加载linux本地/mytemp/stu_score.txt'文件,映射到stu_score表中的dt='2018-10-18'的分区中
load data local inpath '/mytemp/stu_score.txt' into table stu_score partition (dt='2018-10-19');
再加载linux本地/mytemp/stu_score.txt'文件,映射到stu_score表中的dt='2018-10-19'的分区中
dfs -cat /user/hive/warehouse/test.db/stu_score/dt=2018-10-18/stu_score.txt;
查看分区表在hdfs上的存储情况
select * from stu_score;
查看表内容
show partitions stu_score;
查看stu_score表的分区情况
create table if not exists stu_score_tmp(id int,name string,score int,status int) row format delimited fields terminated by ',';
load data local inpath '/mytemp/stu_score.txt' into table stu_score_tmp;
创建临时表stu_score_tmp,用于将数据动态分区到已存在的分区表中
select * from stu_score_tmp;
查看临时表的stu_score_tmp内容
insert into stu_score partition(dt) select id,name, score,status,'2018-10-28' from stu_score_tmp;
将stu_score_tmp表中的数据动态分区的形式加载到stu_score表中
drop table if exists stu_score_tmp;
删除临时表,节省数据库空间
select * from stu_score;
查看stu_score表最终内容
show partitions stu_score;
查看stu_score表的最终分区情况
执行脚本命令以及测试结果:hive -f partitioned.sql


二、分区又分桶。
可以对数据表分区之后继续分桶。
stu_part_clu.sql脚本的分区又分桶用到的资源:
mkdir /mytemp
cd /mytemp
vi stu_tmp.txt1,tom,12
2,jack,15
3,date,23
4,hadoop,24
5,sqoop,10
6,yarn,67
7,hive,34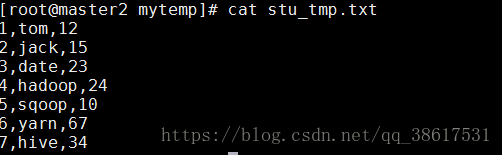
hive脚本的具体内容如下---stu_part_clu.sql
执行脚本命令:hive -f stu_part_clu.sql
set mapreduce.framework.name=local;
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
use test;
drop table if exists stu_part_clu;
drop table if exists stu_part_clu_tmp;
create table stu_part_clu_tmp(id int,name string,age int) row format delimited fields terminated by ',';
show tables;
load data local inpath '/mytemp/stu_tmp.txt' into table stu_part_clu_tmp;
select * from stu_part_clu_tmp;
create table stu_part_clu(id int,name string,age int)partitioned by(dt string,country string) clustered by(id) sorted by (id) into 2 buckets row format delimited fields terminated by ',';
insert into stu_part_clu partition(dt,country) select id,name,age,'2018-10-19','shanghai' from stu_part_clu_tmp;
insert into stu_part_clu partition(dt,country) select id,name,age,'2018-10-19','beijing' from stu_part_clu_tmp;
insert into stu_part_clu partition(dt,country) select id,name,age,'2018-10-20','beijing' from stu_part_clu_tmp;
dfs -ls /user/hive/warehouse/test.db/stu_part_clu/dt=2018-10-19/country=shanghai/;
dfs -ls /user/hive/warehouse/test.db/stu_part_clu/dt=2018-10-20/country=beijing/;
select * from stu_part_clu tablesample(bucket 1 out of 2 on id);
drop table if exists stu_part_clu_tmp;
show tables;分区又分桶的脚本详细解析--待更