编写MapReduce程序,实现WordCount
一、在集群创好文件夹,并上传好相应的文件
输入hdfs dfs直接回车即可出现操作提示

(1)创建目录
hdfs dfs -mkdir /wordcount(2)创建文件input和output目录
hdfs dfs mkdir /wordcount/input
hdfs dfs mkdir /wordcount/output(3)上传本地TXT文件到集群
hdfs dfs -put text1.txt /wordcount/input
二、打开eclipse编写MR程序代码
不知道如何接入集群的同学可以参照博客,将eclipse接入hadoop:https://blog.csdn.net/qq_38741971/article/details/88876815
(1)新建map工程
(2)编写Mapper类型
package demo;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* map阶段 --->
* 分析:text1.txt
* hello world -->=<0,"hello world">-->==<"hello",1>,<"world",1>
* hello hadoop -->=<11,"hello hadoop">-->==<"hello",1>,<"hadoop",1>
*/
public class WordMapper extends Mapper {
Text word = new Text();
IntWritable one = new IntWritable(1);
/**
* map函数:处理行,有几行就处理几行,上述案例会调用两次
*/
@Override
protected void map(LongWritable key, Text value,Context context)throws IOException, InterruptedException {
//将每行数据按空格分割开
StringTokenizer itr = new StringTokenizer(value.toString()," ");
while (itr.hasMoreElements()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
(3)编写Reduce类型
package demo;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* reduce阶段:====
* 分析:reduce接收来自map阶段输出数据=<"hello",1>,进到reduce函数后,数据变成如下内容:
* <"hello",[1,1]>,<"world",[1]>....(shuffle阶段)重点知识
*
*/
public class WordReduce extends Reducer{
IntWritable result = new IntWritable();
@Override
protected void reduce(Text k2, Iterable v2,Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable v : v2) {
sum = sum + v.get();
}
result.set(sum);
context.write(k2, result);
}
}
(4)编写Driver类型
package demo;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* Driver 驱动类
*
*
*/
public class WordCount {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
System.setProperty("HADOOP_USER_NAME", "dodo");
Job job = Job.getInstance(conf);
job.setJobName("max air");
//创建job作业,需要conf,给作业命名"word count"
//设置通过一个类的全路径,加载寻找相应的jar包
job.setJarByClass(WordCount.class);
//设置job所需的mapper类
job.setMapperClass(WordMapper.class);
//job.setCombinerClass(cls);
//设置job所需的reducer类
job.setReducerClass(WordReduce.class);
//设置job作业的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//为MR的job添加数据输入路径
FileInputFormat.addInputPath(job, new Path("hdfs://192.168.81.128:9000/wordcount/input/text*.txt"));
//为MR的job设置数据输出路径
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.81.128:9000/wordcount/output/out"));
//提交job到集群,并且等待完成
try {
System.exit(job.waitForCompletion(true)?1:0);
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
如果想从window本地读取文件,同时跑完MR程序,文件落到window可以如下设置

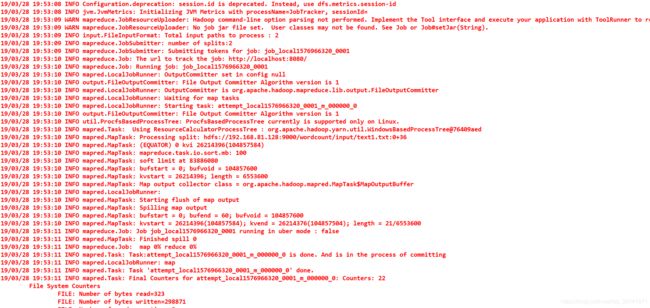
(5)运行,执行成功出现下图