Challenge of Existing Systems:
Existing in-memory storage systems have interfaces based on fine-grained updates.
Required replicate data or logs across nodes for fault tolerance ,which is expensive.
How to design a distributed memory abstraction that is both fault-tolerant and efficient?
Solution: Resilient Distributed Datasets(RDDs)
- Distributed collections of objects that can be cached in memory across cluster.
- Manipulated through parallel operators.
- Automatically recomputed on failure based on lineage.
RDDs can express many parallel algorithms, and capture many current programming models.
- Data flow models: MapReduce, SQL
- Specialized models for iterative apps: Pregel...
RDDs is a fault-tolerant for In-Memory cluster computing, and a distributed memory abstraction that lets programmers perform in-memory computations on large clusters in a fault-tolerant manner.
Resilient
Fault-tolerant: is able to recompute missing or damaged partitions due to node failures.
Distributed
Data residing on multiple nodes in a cluster.
Dataset
A collection of partitioned elements, e.g.tuples or other objects.
RDD is the primary data abstraction in Apache Spark and the core of Spark. It enables operation on collection of elements in parallel.
RDD Traits
- In-memory: data inside RDD is stored in memory as much size and long time as possible.
- Immutable or Read only: it doesn't change once created and can only be transformed until an action is executed that triggers the execution.
- Cacheable: You can hold all the data in a persistent storage like memory or disk.
- Parallel: process data in parallel.
- Typed: values in a RDDs have types.
- Partitioned: the data inside a RDD is partitioned(split into partitions) and then distributed across nodes in a cluster(one partition per JVM that may or may not correspond to a single node)
RDD Operations
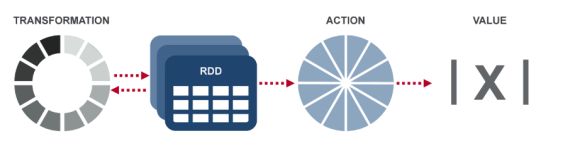
Tranformations: returns a new data.
Nothing get evaluated when you call a Transformation function, it just takes a RDD and return a new RDD.
Transformation functions include map, filter, flatMap, groupByKey, reduceByKey...
Action: evaluates and returns a new value.
When an Action function is called on a RDD object, all the data processing queries are computed at the time and the result value is returned.
Action functions include reduce, collect, count, first, take...
Working with RDDs
Create an RDD from a data source
- by parallelizing existing collections(lists or arrays)
- by tranforming an existing RDDs.
- from files in HDFS or any other storage system.
Apply transformation to an RDD:e,g,map,filter.
Apply actions to an RDD:e.g.collect,count
Users can control two other aspects:
- Persistence
- Partitioning
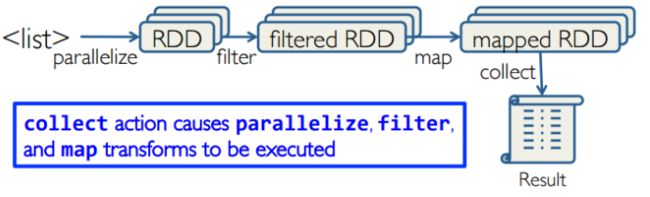
Creating RDDs
- From HDFS, text files, Amazon S3, Apache HBase, Sequence Files, any other Hadoop Inputformat.
- Creating an RDD from a File
- Turn a collection into an RDD
- Creating an RDD from an existing Hadoop Inputformat.
Spark Transformation
- Creating a new dataset from an existing one.
- Use lazy evaluation: Results not computed right away - instead Spark remembers set of transformations applied to base dataset.
Spark optimizes the required calculations.
Spark recovers from failures. -
Some transformation functions:
 transformation functions
transformation functions
Spark actions
- Cause spark to execute recipe to transform source.
- Mechanism for getting results out of Spark.
-
Some action functions:
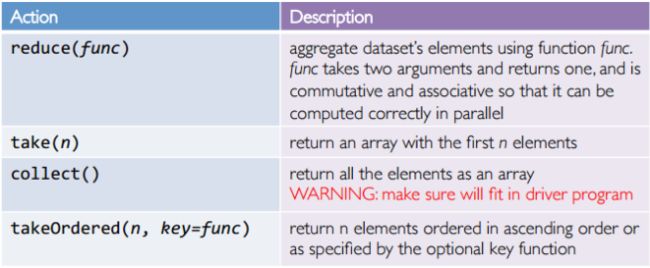 action functions
action functions
Spark Context
Sparkcontext is the entry point to Spark for a Spark application.
Once a SparkContext instance is created you can use it to
- Create RDDs.
- Create accumulators.
- Create broadcast variables.
- Access Spark services and run jobs.
A Spark context is essentially a client of Spark's execution environment and acts as the master of your spark application.
The first thing a Spark program must do is to create a SparkContext object which tells Spark how to access a cluster.
In the Spark shell, a special interpreter-aware SparkContext is already created for you, in the variable called sc.
RDD persistence cache/persist
One of the most important capabilities in Spark is persisting(caching) a dataset in memory across operations.
When you persist an RDD, each node stores any partitions of it. You can reuse it in other actions on that dataset.
Each persisted RDD can be stored using a different storage level:
- MEMORY_ONLY:
Store RDD as deserialised java objects in the JVM.
If RDD doesn't fit in memory, some partitions will not be cached and will be recomputed when they are needed.
This is the default level. - MEMORY_AND_DISK
If RDD doesn't fit in memory, store the partitions that don't fit on disk, and read them from there when they are needed.
cache = persist(StorageLevel.MEMOEY_ONLY)
Why persisting RDD?
- If you do errors.count() again, the file will be loaded again and computed again.
- Persist will tell spark to cache the data in memory, to reduce the data loading cost for further actions on the same data.
- errors.persist() will do nothing. It is a lazy operation. But now the RDD says "read this file and then cache the contents". This action will trigger computation and data caching.
Spark key-value RDDs
- Similar to MapReduce, Spark supports key-value pairs.
- Each element of a pair RDD is a pair tuple.
-
Some key-value transformation functions
 Some key-value transformation functions
Some key-value transformation functions
Setting the level of parallelism
All the pair RDD operations take an optional second parameter for number of tasks.
words.reduceByKey((x,y)=>x+y, 5)
words.groupByKey(5)