例一:爬取信息关于'gbk' codec can't encode character '\xa0' in position 6: illegal 错误提示:
1 from DrawStu.DrawStu import DrawStu; 5 #初始化class 得到对象 6 draw=DrawStu(); 7 if __name__ == '__main__': 8 print('爬取研究生调剂信息'); 9 size=draw.get_page_size(); 10 print(size) 11 for x in range(size): 12 start=x*50; 13 print(start); 14 print('https://yz.chsi.com.cn/kyzx/tjxx/?start='+str(start)); 15 pass
1 import urllib.request; 2 from bs4 import BeautifulSoup; 3 """爬取核心的核心模块,功能只负责爬取研究生调剂信息""" 4 5 6 class DrawStu(): 7 """docstring for DrawStu""" 8 def __init__(self): 9 self.baseurl='https://yz.chsi.com.cn/kyzx/tjxx/'; 10 pass; 11 12 13 #爬取基本列表 14 def draw_base_list(self,url): 15 print('url is:::',url); 16 pass 17 18 #爬取页面的总页数 19 def get_page_size(self): 20 requesturl=self.baseurl; 21 response=urllib.request.urlopen(requesturl); 22 html=response.read();#read进行乱码处理 23 print(html); 24 doc=BeautifulSoup(html); 25 pcxt=doc.find('div',{'class':'pageC'}).findAll('span')[0].text; 26 print(pcxt); 27 #re正则表达式 字符串截取api 28 pagesize=pcxt.strip(); 29 pagearr=pagesize.split('/'); 30 pagestr=pagearr[1]; 31 return int(pagestr[0:2]); 32 pass 33 34
运行时出现如下的错误提示:![]()
找了很多方法仍然无果最后同学提供了一段解决编码格式问题的万能代码段,分享给大家。
import io import sys sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
将这段代码加入即可解决。
正确运行结果:
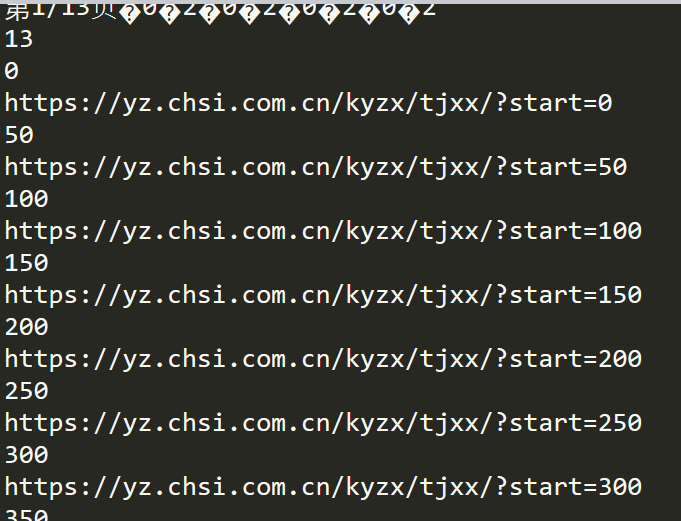
例二:在安装pip instal XX是出现如下错误:
pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host=‘files.pythonhosted.org’, port=443): Read timed out.
解决办法:
设置超时时间,
pip --default-timeout=100 install -U Pillow(对应的是软件包模块的名称)
找了很久的解决办法才找到。原网址:https://blog.csdn.net/m0_43432638/article/details/84400474
例三:在对csv进行写入操作时出现错误,TypeError: sequence item 0: expected str instance, int found
1 number_lst=[1,2,3,4] 2 numbei_lst=[str(x) for x in number_lst] 3 with open('price2017.csv','a',encoding='utf8')as f: 4 f.write(','.join('%s' %id for id in number_lst))#遍历list的元素,把他转化成字符串。 5 f.close()
解决办法:print(" ".join('%s' %id for id in number_lst))
原网址:https://blog.csdn.net/laochu250/article/details/67649210