作者: 张皓
G7业务快览
G7主要通过在货车上的传感器感知车辆的轨迹、油耗、点熄火、载重、温度等数据,将车辆、司机、车队、货主连接到一起,优化货物运输的时效、安全、成本等痛点问题。
整个数据是通过车载的传感器设备采集,比如公司的Smart盒子,CTBox盒子,油感设备,温度探头等,将车辆数据上报到后端平台,在后端平台计算和处理,最后展示到用户面前。
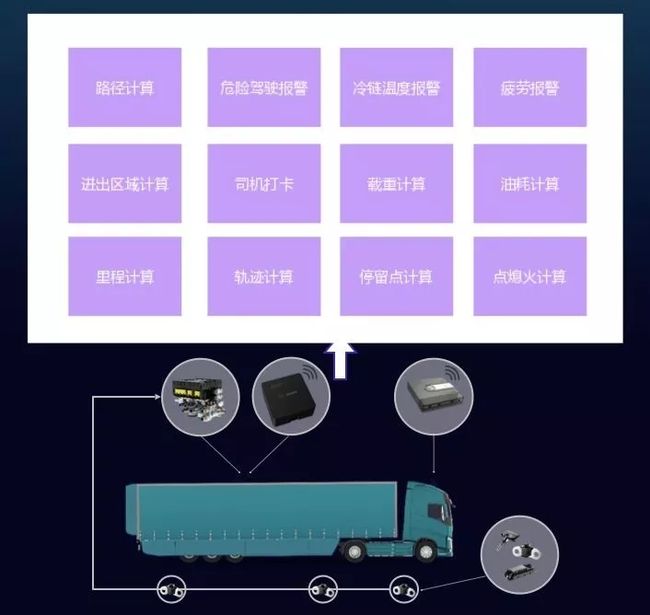
G7的业务场景是典型的IoT场景:
-
传感器数据
-
数据种类多
-
数据质量差
-
数据低延迟
- 数据量大
其中,数据质量差的原因是整个链条会非常的长,从传感器采集的车辆的数据,通过网络运营商将数据上报到后端服务器,再经过解析,mq,过滤,调用三方接口,业务处理,入库,整个过程非常的长,造成数据在传输过程中出现数据重复,数据缺失等。另外一点,IoT场景需要数据传输的延迟非常低,比如进出区域报警,当车辆进入到某个电子围栏中的时候需要触发报警,这个时候需要快速产生报警事件,通常不能超过30s,否则时间太长车辆已经通过了某个电子围栏区域再报警就没有价值了。再一个,数据量也是非常大的,现在每天产生轨迹点20亿+,每天产生数据量100亿+,对计算性能的要求非常高。
实时计算选型
从上面的场景我们可以感知到,在G7的IoT场景需要的是一个低延迟,处理速度快的实时计算引擎。最开始我们的一些架构是基于Lambda架构的,比如轨迹点计算,会使用实时计算引擎计算出实时数据,这份数据延迟比较低,但是数据不是很准确,另外需要用离线批量再计算一遍,这份数据通常比较准确,可以用来修复实时数据。这样做的缺点也比较明显,一是程序需要维护两套代码:实时程序和离线程序,二是实时数据不准确,准确的数据延迟又太高。后来我们惊喜的发现一种基于实时处理的架构体系Kappa。
Kappa的架构是强调数据的实时性,为了保证数据的实时性有些延迟太多的数据它会建议丢弃,所有的计算逻辑只有在实时计算中,整个计算只有一套逻辑,数据从MQ中获取,经过数据处理层计算和加工,最后落入到数据存储层,对外提供数据查询功能。相对Lambda架构,Kappa架构更加适合IoT领域。
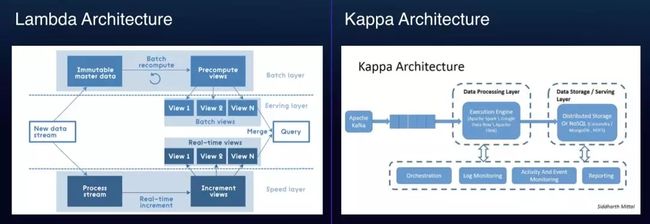
针对Kappa架构,我们对行业主流的实时流计算框架进行了对比:
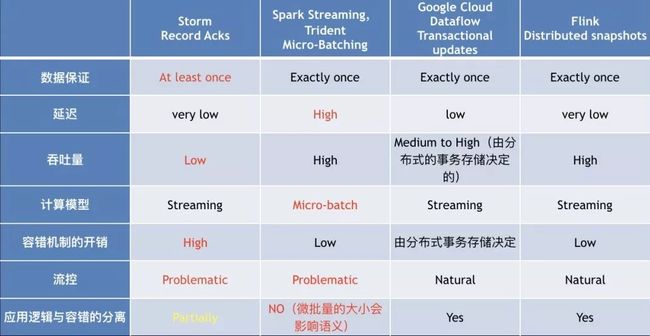
分别对主流的流计算框架:Storm,Storm Trident,Spark Streaming,Google Cloud Dataflow,Flink做了对比。基于微批量的Spark Streaming和Storm Trident延迟比较高,从这点就不适合我们的场景。Storm的延迟很低,但是数据一致性是At Least once,容错机制比较复杂,流控会比较抖动,这些方面都是不太适合。其中,Flink的一致性保证(1.4版本还支持了end-to-end一致性),延迟比较低,容错机制的开销是比较小的(基于Chandy-Lamport的分布式快照),流控是比较优雅的(算子之间的数据传输是基于分布式内存阻塞队列),应用逻辑与容错是分离的(算子处理和分布式快照checkpoint),基于以上我们认为flink是比较适合IoT这个场景的。
G7业务应用案例 Flink目前在G7的应用场景,主要有三方面:
-
实时计算
-
实时ETL
- 统计分析
下面分别介绍下以上三个场景的使用。
实时计算
在G7的场景中,有很多业务都属于实时计算的范畴,比如进出区域事件,超速事件,怠速事件,超速事件,疲劳报警事件,危险驾驶报警,油耗计算,里程计算等。其中疲劳报警计算是最早开始尝试使用flink来落地的。
疲劳报警业务模型
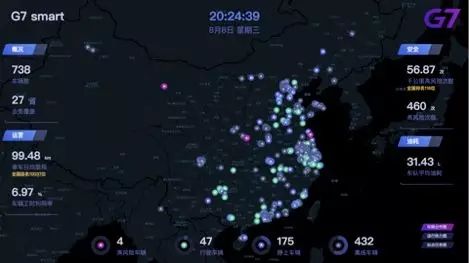
这是G7针对客户推出的G7大屏,其中风险相关的部分是根据疲劳计算得出。
根据G7的大数据计算,因为疲劳驾驶造成货车事故的比重占到整个事故的20%。对疲劳驾驶进行报警和预警就显得特别重要,可以有效降低事故发生的可能性。
根据车辆行驶的里程,驾驶员行驶的里程,驾驶时长,判断是否存在疲劳驾驶。如果超过报警阀值则报警,如果在报警阀值下面在预警阀值上面则预警。报警和预警都是下发语音到货车驾驶室提醒司机。
这个业务场景中面临的最大挑战是实时性,稳定性。只有用最短的时间、最稳定的方式将告警下发到相关人员才能最大程度减少风险。
业务流程
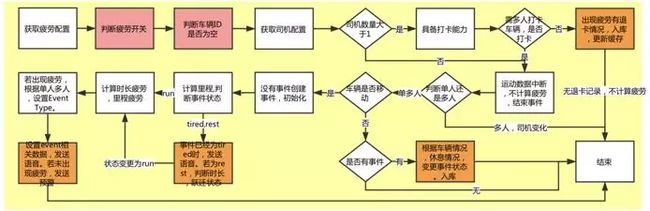
在整个处理流程中,首先会去获取疲劳配置,根据车辆的状态信息和司机打卡信息与疲劳配置结合,判断是否出现预警和报警。计算过程中会把疲劳驾驶开始的状态缓存起来,疲劳驾驶结束的时候获取之前的状态数据,匹配成功之后会生成一条完整的疲劳事件。中间会调用一些接口服务比如dubbo获取车辆的配置数据、状态数据,产生的疲劳报警则会调用下发语音的接口,疲劳事件结果也会存储到hbase、mysql、kafka等。
Streaming模型
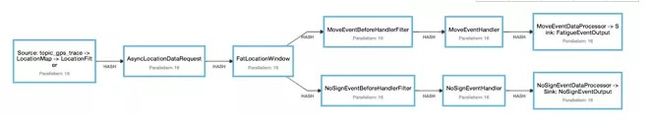
最后开发成Flink的程序,从头到到尾分别由以下算子构成:消费kafka算子、类型转换算子、数据过滤算子、异步调用第三方接口算子,窗口排序算子,疲劳处理业务逻辑算子,数据入库算子组成。
这个过程,也是踩了不少坑,我们也有一些心得体会:
-
算子表达尽量单一
-
每个算子尽量内聚,算子间尽量低耦合
-
算子打散,异步+多线程的性能发挥更好
-
单独设置每个算子单元的并行度,性能更优
-
hash和balance根据情况选择:只有需要使用keyby和valuestate地方才使用hash重新分布数据。其他地方尽量使用balance并且上下游并行度一致,会将task串联成一个线程,不会走网络IO性能更高
- 使用Asynchronous I/O 调用dubbo接口,zuul,db,hbase等外部接口
实时ETL
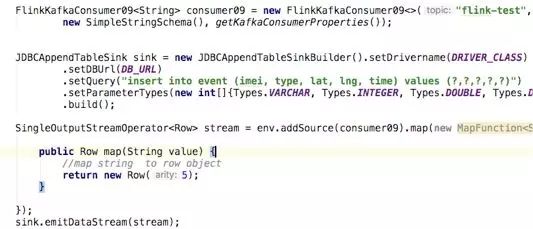
有部分场景是数据简单采集、处理,入库,也就是实时ETL,包括从Kafka采集数据到HDFS、DB、HBase、ES、Kafka等,这部分工作可以抽象成Flink的算子表达:Source -> Transformation -> Sink。
这部分通常可以FlinkKafkaConumser、MapFunction、JDBCAppendTableSink这类代码。如下:
统计分析
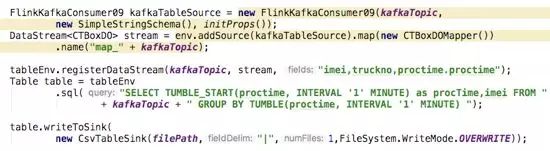
有部分场景需要有一些实时的统计分析,比如统计最近一小时内全国各城市,车辆总数,司机总数,疲劳事件,进出区域事件,打卡次数,点熄火事件等。这种场景,通常可以使用Flink SQl的做实时分析,sql+窗口函数(固定窗口,滑动窗口)。代码大致如下:
实时计算平台开发和现状
在业务上的成功落地,我们也希望能把打造一个实时计算平台,服务各条业务线,经过差不多3个月的打磨,内部代号为Glink的实时计算平台上线,大致的架构如下:
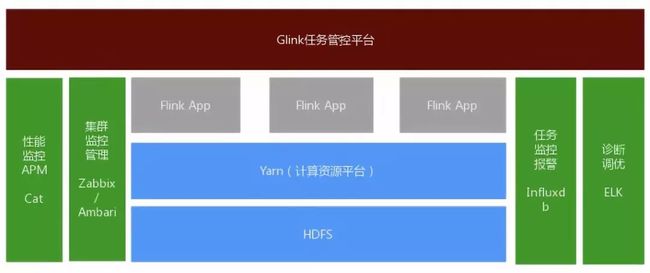
Glink主要由以下部分组成:
-
HDFS分布式文件系统。用来存储flink任务中产生的checkpoint/savepoint数据,任务报、第三方依赖包的存储和分发,任务运行中产生的临时数据等;
-
Yarn统一计算资源平台。用来提供统一的分布式计算资源平台,任务提交,任务调度,任务执行,资源隔离功能。目前所有的flink任务都是通过yarn进行统一的计算资源管理;
-
性能监控AMP工具。使用点评开源的Cat,在此基础上做二次开发并取名“天枢系统”。可以提供程序的耗时95、99线、平均耗时、最大耗时、java GC监控、线程监控、堆栈信息等;
-
集群监控管理。机器资源监控使用zabbix,提供cpu、内存、磁盘io、网络io、连接数、句柄监控。集群资源监控和管理使用开源Ambari,提供自动化安装、配置、集群整体任务、内存、cpu资源、hdfs空间、yarn资源大小监控报警;
-
任务监控报警。使用flink提供的statsD reporter将数据上传导时序数据库InfluxDB,通过扫描Infludb数据绘制出task的处理流量,通过监控流量阀值低于预期值报警;
-
诊断调试。使用成熟的日志查询系统 es+logstash+kibana,通过采集每个节点的日志写入到es中, 可以在kibana中查询关键信息获取日志内存,提供诊断和调优程序的线索;
-
Flink APP 程序应用层。具体开发的flink应用程序,通常解决实时etl,统计分析,业务计算的场景;
- Glink任务管控平台。将以下的功能进行封装,提供统一的任务管理,运维管理功能。
实时计算平台展示-任务管理
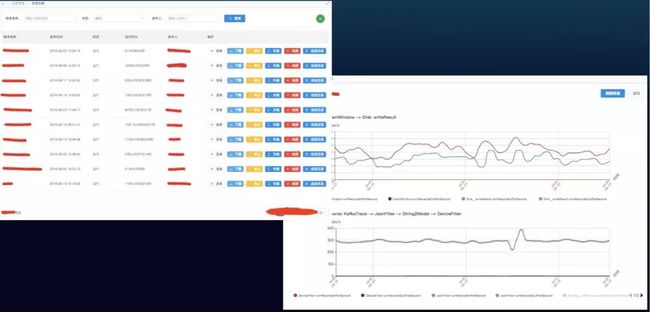
实时计算平台展示-日志和性能监控
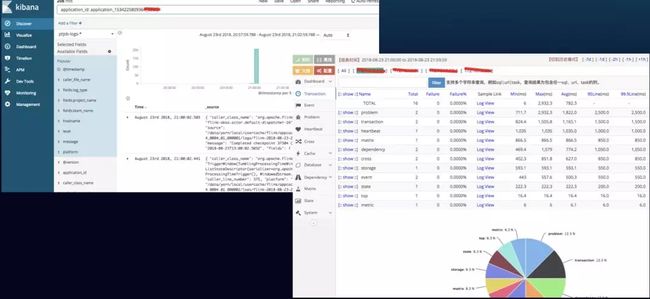
平台的部分功能介绍:
-
任务管理功能。提供任务发布,修改,升级,停止,申请资源,资源审核,启动日志查看功能;
- 运维管理功能。提供日志查看,程序监控,任务监控,流量监控,异常报警等功能。
以上Glink实时计算平台的功能,基本上满足用户独立完成从程序开发,发布,调优,上线,运维的工作。
Glink-Framework开发框架
除了提供相应的平台功能,还需要在flink的生态上提供比较好的封装和工具类,因此我们提供了开发工具的脚手架:Glink-Framework框架。
Glink-Framework提供以下封装:
-
简化pom文件,减少大量的依赖、插件配置;
-
三方调用集成:dubbo,zuul;
-
三方数据库集成:mysql,redis;
-
多环境管理;
-
依赖版本管理;
- 代码监测工具:checkstyle,pmd,findbugs。
平台与业务方BP合作方式
另外一方面,我们认为flink是有一定的技术门槛,特别对于之前没有并发编程、集群开发经验的小伙伴,需要有一段时间的学习才能上手,针对这个痛点,我们提出了技术BP的技术合作方式。我们会根据业务的复杂度,平台指派一至多名技术人员参与到业务方的整个开发和运维工作中,从需求分析到上线落地全程参与,后期还会有持续的技术分享和培训帮助业务方学习开发能力。

踩坑
在整个平台化,以及业务开发的过程中,flink也踩坑不少,比较典型的下面一些。
-
并行度太多造成barrier对齐的花费时间更长,有个并行度28的子任务的对齐时间超过50s;
-
Valuestate不能跨算子共享;
-
flink1.3 kafka connector不支持partition增加;
-
与spring整合,出现handler匹配的问题;
- hadoop的包冲突造成,程序无法正常启动的问题且无异常;
其中比较有意思的是并行度太多,造成barrier对齐花费时间太多的问题。要理解这个问题首先要了解flink在生成checkpoint的过程中,会在source的插入barrier与正常消息一起往下游发射,算子中等到指定的brrier后会触发checkpoint。如下图所:
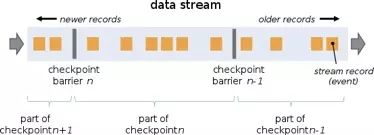
这是在一个流的情况下,如果有多个流同时进入一个算子处理就会复杂一点。flink在做checkpoint的时候,发现有多个流进入一个算子,先进入这个算子的barrier对应的那段消息就会buffer到算子中等待另外的流对应的barrier也到达才会触发checkpoint,这个buffer再等待的过程称为checkpoint alignment(barrier对齐),如下图:

在线上运行的某个程序的一些算子因为barrier对齐的时间超过50s,造成程序 checkpoint超时失败。对于这个问题,我们的调优策略是两种,一是尽量减少并行度,就是让流入一个算子的流尽量少,如果在4个以内barrier对齐的时间是比较少的。另外一种方式,使用at least once的语义替换exactly once的语义,这样checkpoint的时候不会去做barrier对齐,数据到了算子马上做checkpoint并发送下游。目前 我们的解决办法是根据不同的业务场景来区分,如果使用at least once数据保证就能满足业务需求的尽量用at least once语义。如果不支持的,就减少并行度以此减少barrier对齐的数据量和时间。
平台收益
通过近段时间的平台化建设,在”降本增效“方面的收益主要体现在以下几个方面:
-
资源利用率提高。目前通过对整个集群的监控,在混合部署的情况下平均cpu利用率在20%左右,在某些cpu密集计算的业务cpu利用率会更高一些;
-
开发效率提升。比如ETL采集程序的开发,传统开发采集数据、转化、入库大概需要1天左右时间,通过平台化的方式开发简单的ETL程序在1小时内完成开发;
-
数据处理量大。平均每天处理数据量在80亿条以上;
- 业务覆盖面广。平台上线业务30+,预计年内突破100+。服务于公司各条业务线,IoT平台,EMS,FMS,智能挂车,企业解决方案,SaaS,硬件部门等。
未来规划
未来对于flink的规划,我们主要还是会围绕“降本增效,提供统一的计算平台”为目标,主要聚焦在以下几个方面:
1 .资源隔离更彻底。目前的资源隔离使用yarn的默认隔离方式只是对内存隔离,后续需要使用yarn+cgroup对内存和cpu都做隔离。另外会考虑使用yarn的node label做彻底机器级别隔离,针对不同的业务划分不同类型的机器资源,例如高CPU的任务对应CPU密集型的机器,高IO的任务对应IO比较好的机器;
-
平台易用性提高。平台包括代码发布、debug、调试、监控、问题排查,一站式解决问题;
-
减少Code。通过使用Flink SQL+UDF函数的方式,将常用的方法和函数进行封装,尽量用SQL表达业务,提高开发效率。另外也会考虑CEP的模式匹配支持,目前很多业务都可以用动态CEP去支持;
- 通用的脚手架。在Glink-Framework上持续开发,提供更多的source、sink、工具等,业务封装,简化开发;
此篇文章,摘自于张皓在 「Flink China社区线下 Meetup·成都站」 的技术分享
更多资讯请访问 Apache Flink 中文社区网站